print 函数,转义字符与原字符
print 函数
- 可以输出数字,字符串,含有运算符的表达式
- 可以将内容输出到显示器,文件
- 输出形式可以是换行,不换行
- 输出换行:一行 print()输出后默认换行,同一行中使用逗号
,连接输出的内容不换行
print 语法
- 打印到显示器:
print(需要输出的内容1 , 需要输出的内容2 , 需要输出的内容....) - 打印到文件:
变量名=open('文件路径','采用格式') print(需要输出的内容,file = 存有输出地址的变量) 变量名.close()test = open('D:\desktop\新建文件夹\新建文本文档.txt','a+') print("hello world" ,file = test) file.close()
转义字符
- 转义字符:反斜杠
\ - 转义字符应用场景
- 当字符串中包含反斜杠、单引号、双引号等有特殊用途的字符时,必须使用转义字符对这些字符进行转义
如:反斜杠\\,单引号\',双引号\" - 当字符串中包含换行、回车、水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符
如:换行\n,回车\r,水平制表符\t,退格\b
- 当字符串中包含反斜杠、单引号、双引号等有特殊用途的字符时,必须使用转义字符对这些字符进行转义
标识符与保留字,注释
标识符与保留字
- 有一些单词被 python 赋予了特定的含义,这些词便是保留字,变量和对象起名不能使用,使用代码输出所有保留字:
import keyword print(keyword.kwlist)
注释
单行注释:井号
#; 多行注释:三引号"""或'''#这是单行注释 """ 这是多行注释 """编码声明注释:在文件开头注明编码格式,用以以指定格式打开文件
#coding:gb18030
变量,数据类型及转换,进制
变量
- Python 变量由三部分组成
标识:表示对象所储存的内存地址,使用内置函数
id()来获取
类型:表示的是对象的数据类型,使用内置函数type()来获取
值:表示对象所存储的具体数据,使用print()可以打印输出 - 变量多次赋值以后,会指向新的空间,而不是原来的空间更改数值
数据类型
- 常见数据类型:整型,浮点型,布尔型,字符串
- 整型int:整数,默认十进制,可以使用
0b、0o、0x来分别指定二、八、十六进制print("十进制",124) print("二进制",0b1111100) print("八进制",0o174) print("十六进制",0x7C) - 浮点型float:浮点数由整数部分和小数部分组成,浮点数储存由于二进制储存有不精确性,因此进行运算可能出现错误,可以导入模块
decimal来解决from decimal import Decimal print(Decimal('1.1')+Decimal('2.2')) - 布尔型bool:布尔型只有两个值,True和False,表示真假,数值上,true=1,false=0
Python 一切皆对象,所有对象都有一个布尔值,使用内置函数bool()获取布尔值
以下对象的布尔值为False:false,数值 0,None,空字符串,空列表,空元组,空字典,空集合 - 字符串str:字符串由若干个字符组成,字符串中的字符可以是任意字符,字符串又被称为不可变的字符序列,可以使用单引号、双引号或内容可换行的三引号(
'''或""")来定义
Python 中,字符串的+运算为拼接
类型转换
- 可以使用
str()、int()、float()、bool()等函数来转换数据类型 - float 转为 int 时,只截取整数部分
- int 转为 float 时,会多加.0 后缀作为小数部分
input 函数,运算符及优先级
input 函数
- input()函数作用:接收来自用户的输入
- 默认文件类型为字符串
- 结合类型转换改变数据类型:
a=int(input("请输入数据:")) print(a)
运算符
算术运算符
运算符:加
+、减-、乘*、除/、整除//、取模%、幂**
整除注意:整除一正一负时,向下取整,如 9//-4=-3
取模注意:取模一正一负时,按照余数=被除数-除数*商,如 9%-4 按公式 9-(-4)*(-3)=-3赋值运算符
执行顺序:从右到左
支持链式赋值:a=b=c=20
支持参数赋值:+=、-=、*=、/=、//=、%=(a+=1 等同于 a=a+1)
支持系列解包赋值:a,b,c=10,20,30; 同级运行,可以用来交换数值:a,b=10,20 a,b=b,a print(a,b)比较运算符
比较结果:比较结果是 bool 类型
对象数值 value 的比较:>,<,>=,<=,==,!=
对象地址 id 的比较:is,is not布尔运算符
and(与):两者都为 true,结果才为 true
or(或):二者中只要一者为 true,结果就为 true
not(非):后者取相反(true 变 false,false 变 true)
in:前者是否在后者中
not in:前者是否不在后者中位运算符
- 按位运算符是把数字看做二进制来计算的,Python 中的按位运算法则如下(下表中 a 为 60,b 为 13,二进制格式如下)
a = 00111100 b = 00001101 -------------- a&b = 00001100 a|b = 00111101 a^b = 00110001 ~a = 11000011运算符 描述 实例 & 按位与运算符:参与运算的两个值,如果两个相应位都为 1,则该位结果为 1,否则为 0 (a&b)输出结果 12,二进制解释:00001100 | 按位或运算符:参与运算的两个值,如果两个相应位有一个为 1,则该位结果为 1,否则为 0 (a|b)输出结果 61,二进制解释:00111101 ^ 按位异或运算符:当两个对应位的二进制数值相异时(不相等时),该位结果为 1,否则为 0 (a^b)输出结果 49,二进制解释:00110001 ~ 按位取反运算符:对数据的每个二进制位取反,即把 1 变为 0,0 变为 1。数值上类似于-x-1 ~a 输出结果 -61,二进制解释:11000011,一个有符号二进制数的补码形式 << 左移动运算符:运算数的各二进制位全部左移若干位,高位丢弃,低位补零 (a<<2)输出结果 240,二进制解释:11110000 >> 右移动运算符:运算数的各二进制位全部右移若干位,高位补零,低位丢弃 (a>>2)输出结果 15,二进制解释:00001111
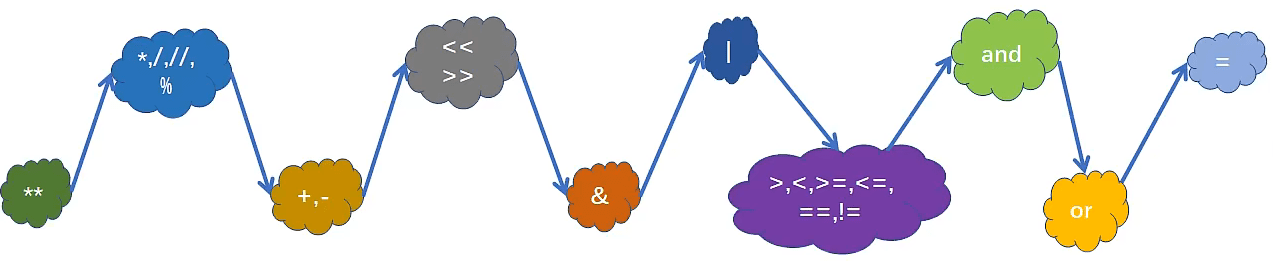
优先级
顺序结构,分支结构,pass 语句
顺序结构
- 程序从上到下顺序地执行代码,中间没有任何的判断和跳转,直到程序结束
分支结构
- 分支if语句,语法如下(注意缩进):
if 条件表达式1: 条件执行体1 elif 条件表达式2: 条件执行体2 else: 条件执行体3 - 嵌套if语句,语法如下(注意缩进,且同缩进下代码为同一层级):
if 条件表达式: if 内层条件表达式: 内层条件执行体 else: 内层条件执行体 else: 条件执行体 - 条件表达式
- 条件表达式是
if...else的简写,与 c++三目运算符类似,语法如下:x if 判断条件 else y
- 条件表达式是
pass 语句
- 语句什么都不做,只是一个占位符,用在语法上需要语句的地方
- 常见用途:搭建语法结构,还没想好代码怎么写的时候
- 可以用在if 语句的条件执行体,for 语句的循环体,while 语句的循环体,try 语句的异常处理体,with 语句的上下文管理体,定义函数时的函数体
循环结构,break,continue 语句
循环结构
- range 函数
- 用于生成一个整数序列,返回值是一个迭代器对象,语法如下:
range(起始值, 终止值, 步长) - 起始值:可选,默认为 0;终止值:生成至 < 终止值;步长:可选,默认为 1
- range 优点:不管 range 生成的整数序列有多长,所有 range 对象占用的内存空间是相同的,只有用到 range 对象时才会去计算序列相关元素
- 用于生成一个整数序列,返回值是一个迭代器对象,语法如下:
- while 循环
- 语法如下:
while 条件表达式: 循环体
- 语法如下:
- for-in 循环
- in表达从(字符串、序列等)中依次取值,又称为遍历,语法如下:
for 自定义变量 in 可迭代对象: 循环体
- in表达从(字符串、序列等)中依次取值,又称为遍历,语法如下:
- 循环嵌套:同if 嵌套,只需注意缩进层次
流程控制语句
break语句:在循环结构内使用,用于结束本层循环,执行后直接跳出循环结构continue语句:在循环结构内使用,用于结束本层本次循环,执行后继续下一次循环
列表
列表的创建
列表的创建需要使用中括号,元素之间用英文的逗号分隔:
列表名 = [元素1, 元素2, ...]还可以使用内置函数
list()创建列表,语法如下:列表名 = list([元素1, 元素2, ...])列表的创建可以使用列表生成式,语法如下:
[表示列表元素的表达式 for 自定义变量 in 可迭代对象]list1=[i for i in range(1,10)] # [1,2,3,4,5,6,7,8,9] list1=[i*i for i in range(1,10)] # [1,4,9,16,25,36,49,64,81]
列表的特点
1、列表元素按顺序有序排序
2、索引映射唯一一个数据
3、列表可以储存重复数据
4、列表可以储存任意数据类型,且任意数据类型混存
5、列表根据需要动态分配和回收内存
关于列表元素有关操作
基本使用操作
- 列表的索引切片,获取列表中元素的值,语法如下:
lst[起点:终点:步长] - 当步长为正数,正向调取;当步长为负数,逆向调取
- 列表的正向索引为 0 ~ n-1,逆向索引为-n ~ -1
- 列表可以作为可迭代对象使用
for-in进行循环遍历
- 列表的索引切片,获取列表中元素的值,语法如下:
列表的增删改查排序
列表的添加操作
1、
append函数,在列表的末尾添加一个元素
2、extend函数,在列表的末尾添加至少一个元素,可以是列表
3、insert函数,在列表的指定位置插入一个元素
4、切片操作,将原列表指定范围替换为新元素或新列表示例:
list1=[10,20,30] list1.append(100) print(list1) list2=["hello","world"] list1.extend(list2) print(list1) list1.insert(1,20) print(list1) list3=[True,False,"hello"] list1[1:]=list3 print(list1)[10, 20, 30, 100] [10, 20, 30, 100, 'hello', 'world'] [10, 20, 20, 30, 100, 'hello', 'world'] [10, True, False, 'hello']
列表的删除操作
1、
remove函数,删除列表中第一个值为 value 的元素
2、pop函数,删除列表中指定位置的元素,并返回该元素,默认删除最后一个元素
3、切片操作,将原列表指定范围替换为空列表以删除
4、clear函数,清空列表
5、del函数,删除列表示例:
list1=[10,20,30,40,50,60,30] list1.remove(30) print(list1) list1.pop(1) print(list1) list2=list1[1:3] print(list2) list1[1:3]=[] print(list1) list1.clear print(list1) del list1 #print(list1) 报错,不存在list1[10, 20, 40, 50, 60, 30] [10, 40, 50, 60, 30] [40, 50] [10, 60, 30] [10, 60, 30]
列表的修改操作
为指定索引的元素赋予一个新值 或 为指定的切片赋予一个新值
示例:
list1=[10,20,30,40] list1[2]=100 print(list1) list1[1:3]=[300,400,500,600] print(list1)[10, 20, 100, 40] [10, 300, 400, 500, 600, 40]
列表的查找判断操作
- 可以使用
index函数获取列表(指定范围内)中第一个值为所填 value 的元素的索引,语法如下:lst.index(value, start, stop) - 列表可以使用
in与not in运算符,判断指定元素在列表中是否存在
- 可以使用
列表的排序操作
1、调用
sort方法,列有中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序
2、调用内置函数sorted,可以指定reverse=True,进行降序排序,原列表不发生改变,产生新的列表对象示例:
list1=[20,40,10,98,54] list1.sort() print(list1) list1.sort(reverse=True) print(list1) list1=[20,40,10,98,54] list2=sorted(list1) print(list2) print(list1)[10, 20, 40, 54, 98] [98, 54, 40, 20, 10] [10, 20, 40, 54, 98] [20, 40, 10, 98, 54]
字典
字典的创建
字典的创建可以使用花括号,格式如下:
scores={"张三":100,"李四":98,"王二马":89}字典的创建可以使用
dict函数,格式如下:scores=dict(name="Jack",age=20)字典的创建可以使用
zip函数,用于将可迭代对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表,格式如下:name=["张三","李四","王二马"] scores=[56,89,14] lst=zip(name,scores)字典的创建可以使用字典生成式,格式如下:
{表示字典key的表达式:表示字典value的表达式 for 表示key的自定义变量,表示value的自定义变量 in zip(可迭代对象a,可迭代对象2)}name=["张三","李四","王二马"] scores=[56,89,14] dictionary={a:b for a,b in zip(name,scores)}
字典的特点
1、以键值对的方式存储数据,字典是一个无序的数列,与列表一样是一个可变序列
2、字典中的所有元素都是一个 key-value 对, key不允许重复,value可以重复
3、字典中的key必须是不可变对象
4、字典也可以根据需要动态地伸缩
5、字典会浪费较大的内存,是一种使用空间换时间的数据结构
有关字典的操作
字典元素的获取
1、用
[]获取元素,语法:dict[key],返回 key 对应的 value
2、用get方法获取元素,语法:dict.get(key),返回 key 对应的 value,如果 key 不存在,则返回默认值(可设置,默认为 None)字典元素的增删改查
增加元素:
dict[new_key]=new_value
删除元素:del dict[key]
更新元素:dict[key]=value
查询元素:in与not in获取字典视图
字典的键视图:
dict.keys()
字典的值视图:dict.values()
字典的键值对视图:dict.items()示例:
scores={"张三":100,"李四":98,"王二马":89} a=scores.keys() print(a) print(type(a)) print(list(a)) #将所有key组成的视图转换为列表 print() b=scores.values() print(b) print(type(b)) print(list(b)) #将所有key组成的视图转换为列表 print() c=scores.items() print(c) print(list(c)) #转换之后的列表元素由元组组成dict_keys(['张三', '李四', '王二马']) <class 'dict_keys'> ['张三', '李四', '王二马'] dict_values([100, 98, 89]) <class 'dict_values'> [100, 98, 89] dict_items([('张三', 100), ('李四', 98), ('王二马', 89)]) [('张三', 100), ('李四', 98), ('王二马', 89)]
元组
元组的创建
用
()创建,格式如下:a=("python","hello",90)使用内置函数
tuple,格式如下:a=tuple(("python","hello",90))只包含一个元组的元素需要使用逗号与小括号,例如:
a=(10,)
元组的特点
- 元组是不可变序列
为什么要将元组设计成不可变序列
- 在多任务环境下,同时操作对象时不需要加锁,因此,在程序中尽量使用不可变序列
- 注意事项:
1、元组中储存的是对象的引用
2、如果元组中对象本身是不可变对象,则不能再引用其他对象
3、如果元组中对象本身是可变对象,则可变对象的引用不允许改变,但数据可以改变 - 元组的遍历使用
for-in进行循环遍历
集合
集合创建
使用
{}创建,格式如下:s={"python","hello",90}使用内置函数
set,格式如下:s=set(range(6)) print(s)使用集合生成式创建,格式如下:
{表示集合元素的表达式 for 自定义变量 in 可迭代对象}s={i for i in range(10)}
集合概述与特点
1、与列表、字典一样都属于可变类型的序列
2、集合是没有 value 的字典
3、集合的元素是不可重复的
集合的相关操作
- 集合元素的判断操作:
in或not in
- 集合元素的新增操作:
1、调用
add()方法,一次添中一个元素
2、调用update()方法,至少添加一个元素(字典) - 集合元素的删除操作
1、调用
remove()方法,一次删除一个指定元素,如果指定的元素不存在抛出 KeyError
2、调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛异常
3、调用pop()方法,一次只删除一个任意元素
4、调用clear()方法,清空集合
集合的关系
- 两个集合是否相等
- 可以使用运算符
==或!=
- 可以使用运算符
- 一个集合是否是另一个集合的子集
- 可以调用方法
issubset进行判断,例如:s1={10,20,30,40,50,60} s2={10,20,30} print(s2.issubset(s1))
- 可以调用方法
- 一个集合是否是另一个集合的超集
- 可以调用方法
insuperset进行判断,例如:s1={10,20,30,40,50,60} s2={10,20,30} print(s1.issuperset(s2))
- 可以调用方法
- 两个集合是否没有交集
- 可以调用方法
isdisjoint进行判断,例如:s1={10,20,30,40,50,60} s2={10,456,789} print(s1.isdisjoint(s2))
- 可以调用方法
集合的数学操作
- 交集
- 使用内置函数
intersection或使用&符号获取,示例:s1={10,20,30,40} s2={20,30,40,50,60} print(s1.intersection(s2)) print(s1 & s2)
- 使用内置函数
- 并集
- 使用内置函数
union或使用符号|符号获取,示例:s1={10,20,30,40} s2={20,30,40,50,60} print(s1.union(s2)) print(s1 | s2)
- 使用内置函数
- 差集
- 使用内置函数
difference或使用符号-符号获取,示例:s1={10,20,30,40} s2={20,30,40,50,60} print(s1.difference(s2)) print(s2.difference(s1)) print(s1 - s2) print(s2 - s1){10} {50, 60} {10} {50, 60}
- 使用内置函数
- 对称差集
- 使用内置函数
symmetric_difference或使用符号^符号获取,示例:s1={10,20,30,40} s2={20,30,40,50,60} print(s1.symmetric_difference(s2)) print(s1 ^ s2){10, 50, 60} {10, 50, 60}
- 使用内置函数
字符串
字符串的特点与驻留机制:
- 特点:python 基本数据类型,是一个不可变的字符序列
- 驻留机制:
- 仅保存一份相同且不可变的字符串的方法。不同的值被存放在字符串的驻留池中,Python 的驻留机制对相同的字符串只保留一份拷贝,后续创建相同的字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
- 驻留机制的几种情况(交互模式):
1、字符串长度为 0 和 1 时
2、符合标识符的字符串
3、字符串只在编译时进行驻留,而非运行时
4、[-5,256]之间的整数数字
字符串的操作
字符串的查询
方法 作用 index() 查找子串 substr 第一次出现的位置,如果子串不存在,则抛出 ValueError rindex() 查找子串 substr 最后一次出现的位置,如果子串不存在,则抛出 ValueError find() 查找子串 substr 第一次出现的位置,如果子串不存在,则返回-1 rfind() 查找子串 substr 最后一次出现的位置,如果子串不存在,则返回-1 示例:
s="hello,hello" print(s.index("lo")) print(s.find("lo")) print(s.rindex("lo")) print(s.rfind("lo"))3 3 9 9
字符串大小写转换
方法 作用 upper() 把字符串中所有字符转换成大写字母 lower() 把字符串中所有字符转换成小写字母 swapcase() 把字符串中大写转为小写,小写转为大写 capitalize() 把第一个字符转为大写,其余转为小写 title() 把每个单词第一个字母转为大写,每个单词其余字母转为小写 字符串内容对齐
方法 作用 center() 居中对齐,第一个参数指定宽度,第二个参数指定填充符,默认空格,如果设置宽度小于实际宽度则返回原字符串 ljust() 左对齐,第一个参数指定宽度,第二个参数指定填充符,默认空格,如果设置宽度小于实际宽度则返回原字符串 rjust() 右对齐,第一个参数指定宽度,第二个参数指定填充符,默认空格,如果设置宽度小于实际宽度则返回原字符串 zfill() 右对齐,左边用 0 填充,该方法只接收一个参数,用于指定字符串宽度,如果指定宽度小于等于字符串长度,返回字符串本身 字符串的劈分
方法 作用 split() 从字符串左边开始劈分,返回列表。可以通过设定 sep 参数指定劈分符(默认空格),通过设定 maxsplit 参数指定劈分字符串时的最大劈分次数,剩余子串会单独作为一部分 rsplit() 从字符串右边开始劈分,返回列表。可以通过设定 sep 参数指定劈分符(默认空格),通过设定 maxsplit 参数指定劈分字符串时的最大劈分次数,剩余子串会单独作为一部分 示例:
s1="hello world python" list1=s1.split() print(list1) s2="hello|world|python" list2=s2.split(sep="|") print(list2) #rsplit从右侧开始['hello', 'world', 'python'] ['hello', 'world', 'python']
字符串的判断
方法 作用 isidentifier() 判断指定字符串是不是合法的标识符 isspace() 判断指定字符串是否全部由空白字符组成(空格、换行、制表符) isalpha() 判断指定字符串是否全部由字母组成 isdecimal() 判断指定字符串是否全部由十进制数字组成 isnumeric() 判断指定字符串是否全部由数字组成 isalnum() 判断指定字符串是否全部由字母和数字组成 字符串替换与合并
方法 功能 作用 replace() 字符串替换 第一个参数指定被替换子串,第二个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前字符串不发生变化,还可以通过第三个参数指定最大替换次数 join() 字符串的合并 将列表或元组中的字符串合并成一个字符串 示例 1:
s="hello,python" print(s.replace("python","java")) s="hello,python,python,python" print(s.replace("python","java",2))hello,java hello,java,java,python示例 2:
list1=["hello","java","python"] print('|'.join(list1)) print('*'.join("python"))hello|java|python p*y*t*h*o*n
字符串的比较
- 字符串可以使用
<、>、<=、>=、==、!=进行比较 - 比较规则:从前向后依次比较ASCII 码,相等则继续,不相等则结束并返回结果
- 字符串可以使用
字符串的切片操作
- 大致同前
[起点:终点:步长],但可以额外通过加号+组合拼接
- 大致同前
格式化字符串与占位、保留小数
- 格式化字符串
- 格式化字符串常用于字符串中可变数值位置进行保留,可以随时方便的替换格式化后位置的内容
- 格式化的三种方法,语法如下:
其中第一种name="张三" age=20 print("我叫%s,今年%d岁" % (name,age)) print("我叫{0},今年{1}岁".format(name,age)) print(f"我叫{name},今年{age}岁")%的用法,%s为字符串,%d或%i为整数,%f为浮点数
- 占位与保留小数
%的占位保留- 占位(%与数据类型之间写数字,表示域宽),示例:
print("%10d" % 99)99 - 保留小数(%与浮点类型之间写.保留位数,保留小数),示例:
print("%.3f" % 3.1415926)3.142 - 注意:上述二者可共存,如:
print("%10.3f" % 3.1415926)
- 占位(%与数据类型之间写数字,表示域宽),示例:
{}的占位保留- 基本同上,跟写在
:后面print("{1 :10.3f}".format(3.1415926))
- 基本同上,跟写在
字符串的编码与解码
编码:将字符串转换为二进制数据(bytes)
解码:将 bytes 类型数据转换为字符串类型示例:
s="天涯共此时" #编码 print(s.encode(encoding="GBK")) print(s.encode(encoding="UTF-8")) #解码 #byte代表的就是一个二进制数据 byte=s.encode(encoding="GBK") print(byte.decode(encoding="GBK")) byte=s.encode(encoding="UTF-8") print(byte.decode(encoding="UTF-8"))b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1' b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6' 天涯共此时 天涯共此时
函数
函数的定义、创建与调用
什么是函数:函数就是执行特定任务和以完成特定功能的一段代码
函数创建与调用,语法如下:
def 函数名(形式参数): 函数体 return 返回值示例:
def sum(a,b,c): result=a+b*c return result print(sum(12,4,3))24形参可以默认一个值,如
def sum(a,b=2,c=3),当有默认值的形参有数据传入,则使用传入数据,否则使用默认值
函数的参数传递
- 位置实参:根据形参对应的位置进行实参传递
例如def sum(a,b,c)中,使用sum(1,2,3),则按位置对应a=1,b=2,c=3 - 关键字实参:根据形参名称进行实参传递
例如def sum(a,b,c)中,使用sum(c=3,b=2,a=1),则按名称对应a=1,b=2,c=3 - 参数传递内存分析:调用函数时,形参内存地址指向被调用的实参,获取数据;调用函数后,释放内存
函数的返回值
1、如果函数没有返回值(函数执行完毕之后,不需要给调用处提供数据),
return省略不写
2、函数的返回值,如果是 1 个,直接返回类型
3、函数的返回值,如果是多个,则返回类型为元组
个数可变的位置形参和关键字形参
- 个数可变的位置形参
- 使用
*定义个数可变的位置形参 - 结果为一个元组
def fun(*a): print(a) fun(10) fun(10,100,20)
- 使用
- 个数可变的关键字形参
- 使用
**定义个数可变的关键字形参 - 结果为一个字典
def fun(**a): print(a) fun(a=10) fun(a=10,b=100,c=20)
- 使用
变量的作用域
变量的作用域为程序能够访问该代码的区域,按范围分为局部变量(仅在当前函数内使用)和全局变量(全局都可使用)
函数外部默认全局变量,函数内部使用
global声明,使局部变量变为全局变量,例如:def fun(a,b): global c c=a+b fun(10,20) print(c)
递归函数
定义:如果一个函数的函数体内调用了它本身,就被称为递归函数
组成部分:递归调用与递归终止条件
调用过程:每递归调用一次函数,都会在栈内存分配一个栈帧;每执行完一次函数,都会释放对应的空间
优缺点
- 缺点:占用内存多,效率低下
- 优点:思路和代码简单
例子:
def forFun_1(i): # 传入最小的数1 if i <= 10: print(i) forFun_1(i + 1) # 尾递归
异常处理
try-except 报错提示语
python 提供了异常处理功能,可以在异常出现时即时捕获,内部“消化”处理,让程序继续执行,语法如下:
try: 可能出现异常的代码 except 错误类型(报错提示写的类型): 异常处理例如:
try: a=int(input("请输入被除数")) b=int(input("请输入除数")) print(a/b) except ZeroDivisionError: #except后跟错误类型 print("除数不允许为0") print("程序结束")此外,同一个 try 下,可以跟多个 except,用来处理多种可能出现的错误类型
最后,可以
except BaseException,表示捕获所有的异常,防止疏漏try-except-else-finally结构:- 如果 try 中没有出现异常,则执行else 块
- finally 块无论是否发生异常都会执行,用来释放try 块中申请的资源
常见错误类型
ZeroDivisionError:除数为 0IndexError:索引超出范围KeyError:键不存在NameError:变量名不存在TypeError:类型错误ValueError:数值错误SyntaxError:语法错误
类与对象
编程两大思想

类与对象认识
- 数据类型
- 不同数据类型属于不同的类
- 使用内置函数
type()查看数据类型
- 对象
- 100,99,520 都是 int 类下包含的相似的不同个例,这些个例专业术语称为实例或对象
定义 python 中的类
创建类的语法
class 类名(每个单词首字母大写,其余小写): pass(内容)示例:
class Student: pass #python中一切皆对象 print(id(Student)) print(type(Student)) print(Student)类的组成
类属性、实例方法、静态方法、类方法
示例:
class Student: native_place="青岛" #直接写在类里的变量称为类属性 def __init__(self,name,age): self.name=name #self.name称为实例属性,进行了赋值操作,将局部变量的name的值给实例属性 self.age=age def eat(self): #实例方法,self可省略,但建议保留//在类外定义称为函数,类内定义称为方法 print("学生在吃饭......") @staticmethod #静态方法使用staticmethod修饰 def method(): #不能写括号内 print("使用了staticmethod进行修饰,所以是静态方法") @classmethod #类方法使用classmethod进行修饰 def cm(cls): print("使用了classmethod进行修饰,所以是类方法")
对象的创建
对象的创建又称为类的实例化
语法:
实例名=类名()示例:
class Student: native_place="青岛" def __init__(self,name,age): self.name=name self.age=age def eat(self): print("学生在吃饭......") @staticmethod def method(): print("使用了staticmethod进行修饰,所以是静态方法") @classmethod def cm(cls): print("使用了classmethod进行修饰,所以是类方法") #创建Student类的对象 stu1=Student("张三",20) #对应类中__init__的两个参数name和age print(id(stu1)) print(type(stu1)) print(stu1) #存储的值为id地址的十六进制2214680575184 <class '__main__.Student'> <__main__.Student object at 0x00000203A53FBCD0>意义:有了实例,就可以调用类中的内容
示例:
class Student: native_place="青岛" def __init__(self,name,age): self.name=name self.age=age def eat(self): print("学生在吃饭......") @staticmethod def method(): print("使用了staticmethod进行修饰,所以是静态方法") @classmethod def cm(cls): print("使用了classmethod进行修饰,所以是类方法") #创建Student类的对象 stu1=Student("张三",20) #对应类中__init__的两个参数name和age stu1.eat() Student.eat(stu1) print(stu1.name) print(stu1.age)学生在吃饭...... 学生在吃饭...... 张三 20
类属性,类方法,静态方法
类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
静态方法:使用@staticmethod修饰的方法,使用类名直接访问的方法
示例:
class Student: native_place="青岛" #类属性 def __init__(self,name,age): self.name=name self.age=age def eat(self): print("学生在吃饭......") @staticmethod def method(): print("使用了staticmethod进行修饰,所以是静态方法") @classmethod def cm(cls): print("使用了classmethod进行修饰,所以是类方法") #使用类属性 print(Student.native_place) stu1=Student("张三",20) stu2=Student("李四",30) print(stu1.native_place) print(stu2.native_place) #共享性 Student.native_place="天津" print(stu1.native_place) print(stu2.native_place,"\n") #类方法的使用方式 Student.cm() #静态方法的使用方式 Student.method()青岛 青岛 青岛 天津 天津 使用了classmethod进行修饰,所以是类方法 使用了staticmethod进行修饰,所以是静态方法
动态绑定属性和方法
python 是动态语言,在创建对象之后,可以动态的绑定属性和方法
示例:
class Student: def __init__(self,name,age): self.name=name self.age=age def eat(self): print(self.name+"在吃饭") stu1=Student("张三",20) stu2=Student("李四",30) stu1.gender="男" #动态绑定属性,将“男”绑定到stu1的gender属性 print(stu1.gender) #print(stu2.gender) 因为没有绑定,所以报错 def show(): print("定义在类之外的,称为函数") stu1.show=show #动态绑定方法,将show函数绑定到stu1的show方法 stu1.show() #stu2.show() 因为没有绑定,所以报错男 定义在类之外的,称为函数
面向对象-封装、继承、多态
面向对象的三大特征
- 封装:提高程序的安全性
- 将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度。
- 在 Python 中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个下划线
_
- 继承:提高代码的复用性
- 多态:提高程序的可扩展性和可维护性
封装的实现方式
示例:
class Student: def __init__(self,name,age): self.name=name self.__age=age #age不希望在类的外部被使用,所以加了__ def show(self): print(self.name,self.__age) stu=Student("张三",20) #在类内使用 stu.show #在类外使用 print(stu.name) #print(stu.__age) 不能在类外访问,所以报错 print("\n",dir(stu),"\n") #列出stu全部的属性 print(stu._Student__age) #在类的外部可以通过 _类名__实例属性 来访问张三 ['_Student__age', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'show'] 20
继承及其实现方式
- 继承
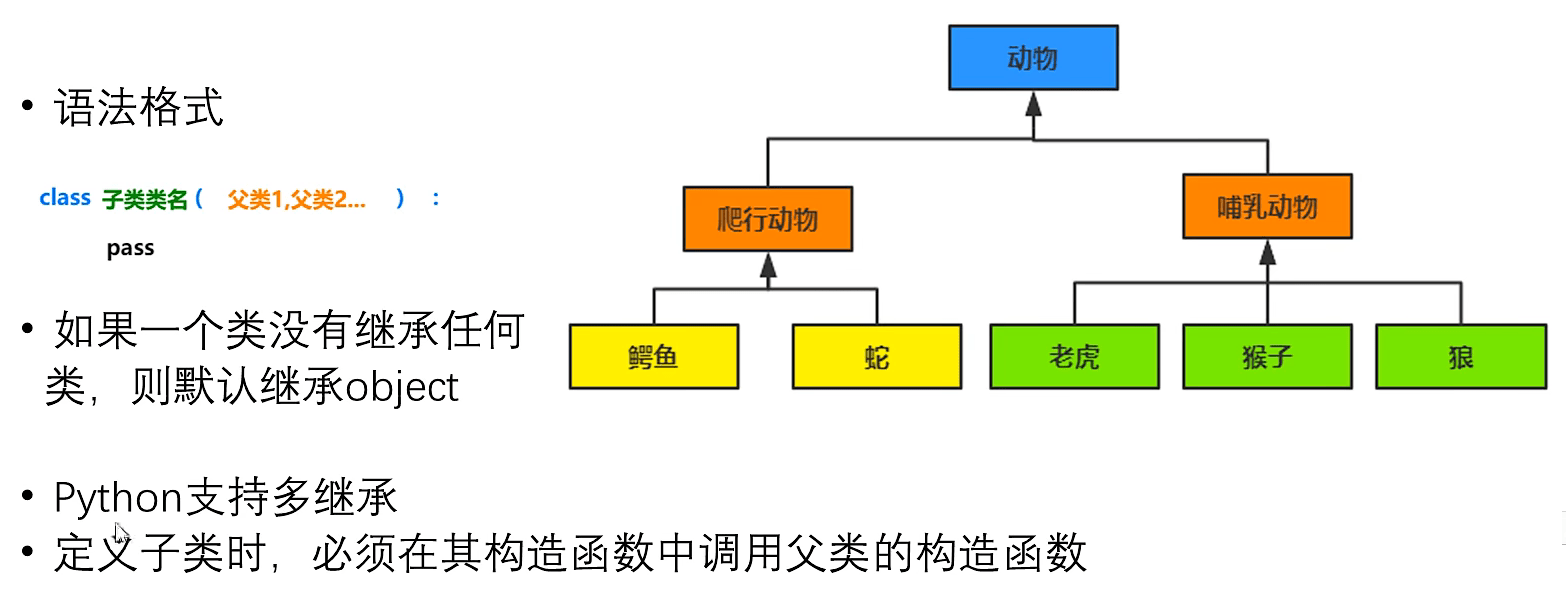
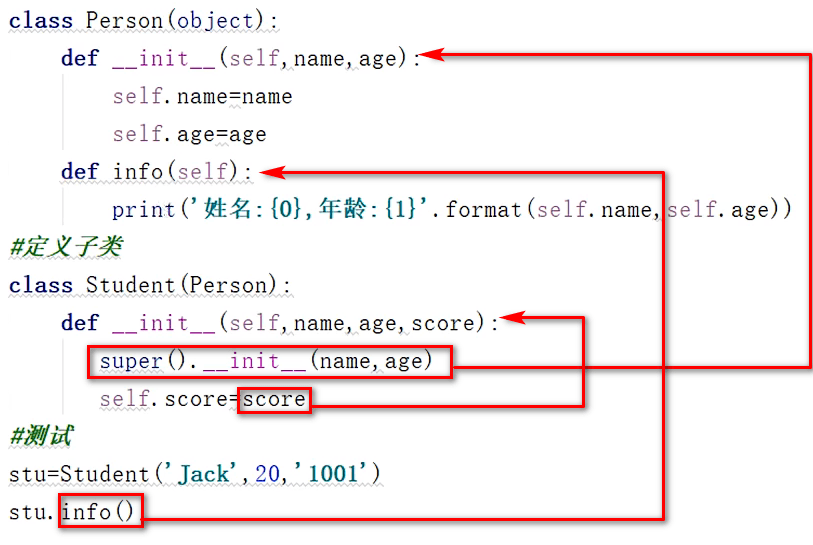
- 方法重写

- object 类

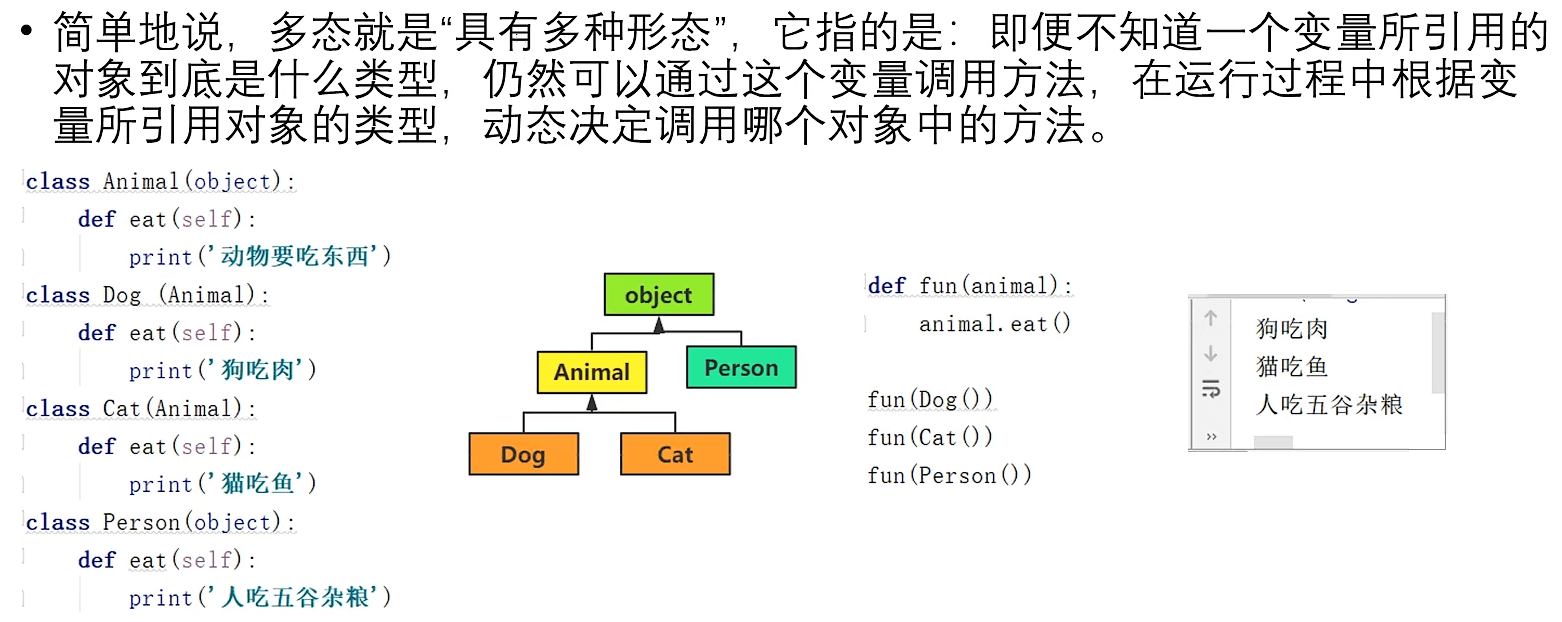
多态
- 多态
- 静态语言和动态语言关于多态的区别
- 静态语言实现多态的三个必要条件
1、继承
2、方法重写
3、父类引用指向子类对象 - 动态语言的多态崇尚“鸭子类型”当看到一只鸟走起来像鸭子、游泳起来像鸭子、收起来也像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为。
- 静态语言实现多态的三个必要条件
类与对象补充、类的赋值与深浅拷贝
特殊属性与特殊方法
大纲总览
类别 名称 描述 特殊属性 dict 获得类对象或实例对象所绑定的所有属性和方法的字典 特殊方法 len() 通过重写len()方法,让内置函数 len()的参数可以是自定义类型 特殊方法 add() 通过重写add()方法,可使用自定义对象具有”+”功能 特殊方法 new() 用于创建对象 特殊方法 init() 对创建的对象进行初始化 特殊属性示例
class A: pass class B: pass class C(A,B): def __init__(self,name,age): self.name=name self.age=age x=C("Jack",20) #x是C类型的一个实例对象 print(x.__dict__) #实例对象的属性字典 print(C.__dict__) #类对象的属性以及方法 print(x.__class__) #对象所属的类 print(C.__bases__) #C的父类类型的元素 print(C.__bases__) #C的类的基类 print(C.__mro__) #类的层次结构,继承关系 print(A.__subclasses__()) #A的子类类型的元素{'name': 'Jack', 'age': 20} {'__module__': '__main__', '__init__': <function C.__init__ at 0x000001943D99A170>, '__doc__': None} <class '__main__.C'> (<class '__main__.A'>, <class '__main__.B'>) (<class '__main__.A'>, <class '__main__.B'>) (<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>) [<class '__main__.C'>]特殊方法示例
class Student: def __init__(self,name): self.name=name def __add__(self,other): return self.name+other.name def __len__(self): return len(self.name) stu1=Student("张三") stu2=Student("李四") s=stu1+stu2 #如果第4,5行不定义,程序报错(因为在Student类中编写了__add__()特殊的方法,所以实现了两个不同类的实例变量相加) print(s) s=stu1.__add__(stu2) #如果第4,5行不定义,程序报错 print(s) print(len(stu1)) #如果第6,7行不定义,程序报错 print(len(stu2))张三李四 张三李四 2 2**new与init演示创建对象的过程**
class Person(object): def __new__(cls,*args,**kwargs): print("__new__被调用了,cls的id值为{0}".format(id(cls))) obj=super().__new__(cls) print("创建的对象的id为{0}".format(id(obj))) return obj def __init__(self,name,age): print("__init__被调用了,self的值为{0}".format(id(self))) self.name=name self.age=age print("object这个类对象的id为{0}".format(id(object))) print("Person这个类对象的id为{0}".format(id(Person))) #创建Person类的实例对象 p1=Person("张三",20) print("p1这个Person类的实例对象的id为{0}".format(id(p1)))object这个类对象的id为140734130337664 Person这个类对象的id为1973241802080 __new__被调用了,cls的id值为1973241802080 创建的对象的id为1973248703792 __init__被调用了,self的值为1973248703792 p1这个Person类的实例对象的id为1973248703792传参过程

类的赋值与深浅拷贝
概念概览
- 变量的赋值操作
- 只是形成两个变量,实际上还是指向同一个对象
- 浅拷贝
- python 拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
- 深拷贝
- 使用
copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
- 使用
- 示例:
- 变量的赋值操作
类的赋值与浅拷贝
class CPU: pass class Disk: pass class Computer: def __init__(self,cpu,disk): self.cpu=cpu self.disk=disk #变量的赋值 cpu1=CPU() cpu2=cpu1 print(cpu1) print(cpu2,"\n") #类的浅拷贝 disk=Disk() computer=Computer(cpu1,disk) #浅拷贝 import copy computer2=copy.copy(computer) print(computer,computer.cpu,computer.disk) print(computer2,computer2.cpu,computer2.disk)<__main__.CPU object at 0x000001E2DF41BE80> <__main__.CPU object at 0x000001E2DF41BE80> <__main__.Computer object at 0x000001E2DF41BD60> <__main__.CPU object at 0x000001E2DF41BE80> <__main__.Disk object at 0x000001E2DF41BD90> <__main__.Computer object at 0x000001E2DF41BCA0> <__main__.CPU object at 0x000001E2DF41BE80> <__main__.Disk object at 0x000001E2DF41BD90>深拷贝
class CPU: pass class Disk: pass class Computer: def __init__(self,cpu,disk): self.cpu=cpu self.disk=disk cpu1=CPU() disk=Disk() computer=Computer(cpu1,disk) #深拷贝 import copy computer2=copy.deepcopy(computer) print(computer,computer.cpu,computer.disk) print(computer2,computer2.cpu,computer2.disk)<__main__.Computer object at 0x0000020C2AE6BD60> <__main__.CPU object at 0x0000020C2AE6BE80> <__main__.Disk object at 0x0000020C2AE6BD90> <__main__.Computer object at 0x0000020C2AE6BC10> <__main__.CPU object at 0x0000020C2AE6B910> <__main__.Disk object at 0x0000020C2AE91480>
模块
模块概览
- 模块英文为 Modules
- 函数与模块的关系
- 一个模块中可以包含 N 多个函数
- 在 Python 中一个扩展名为.py 的文件就是一个模块
- 使用模块的好处
1、方便其它程序和脚本的导入并使用
2、避免函数名和变量名冲突
3、提高代码的可维护性
4、提高代码的可重用性
模块的导入
创建模块
- 新建一个
.py文件,名称尽量不要与 python 自带标准模块冲突
- 新建一个
导入模块
import 模块名称 [as 别名] from 模块名称 import 函数/变量/类示例:
- calc.py文件:
def add(a,b): return a+b def div(a,b): return a/b - main.py文件:
import calc print(calc.add(10,20)) print(calc.div(10,4))30 2.5
- calc.py文件:
注意:VScode 无需设置当前目录为源目录,如使用其他编译器,视情况操作
以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量name,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的name变量的值为main
语法
if __name__=="__main__": #只有以当前模块为主程序运行时才会执行 执行语句示例:
calc.py文件:
def add(a,b): return a+b if __name__=="__main__": print(10+20)main.py文件:
import calc print(calc.add(100,200))300
python 中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
作用
- 代码规范
- 避免模块名称冲突
包与目录的区别
- 包含
__init__.py文件的目录称为包 - 目录里通常不含
__init__.py文件
- 包含
包的导入
import 包名.模块名包的创建:在文件夹目录下创建
__init__.py文件
python 常用内容模块
| 模块名 | 描述 |
|---|---|
| sys | 与 Python 解释器及其环境操作相关的标准库 |
| time | 提供与时间相关的各种函数的标准库 |
| os | 提供了访问操作系统服务功能的标准库 |
| calendar | 提供与日期相关的各种函数的标准库 |
| urllib | 用于读取来自网上(服务器)的数据标准库 |
| json | 用于使用 JSON 序列化和反序列化对象 |
| re | 用于在字符串中执行正则表达式匹配和替换 |
| math | 提供标准算术运算函数的标准库 |
| decimal | 用于进行精确控制运算精度、有效位数和四舍五入操作的十进制运算 |
| logging | 提供了灵活的记录事件、错误、警告和调试信息等日志信息的功能 |
第三方模块的安装与使用
- 在终端 cmd 中执行命令:
如果出错,则在 python 文件根目录打开 cmd 输入pip install 模块名 - 由于服务器在国外,访问速度过慢,可以使用清华源镜像安装
- 临时使用
pip install -i [https://pypi.tuna.tsinghua.edu.cn/simple](https://pypi.tuna.tsinghua.edu.cn/simple) 包名称 - 注意,
simple不能少, 是https而不是http - 设为默认
升级 pip 到最新的版本 (>=10.0.0) 后进行配置(逐行输入):python -m pip install --upgrade pip pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
- 临时使用
简单文件、系统操作
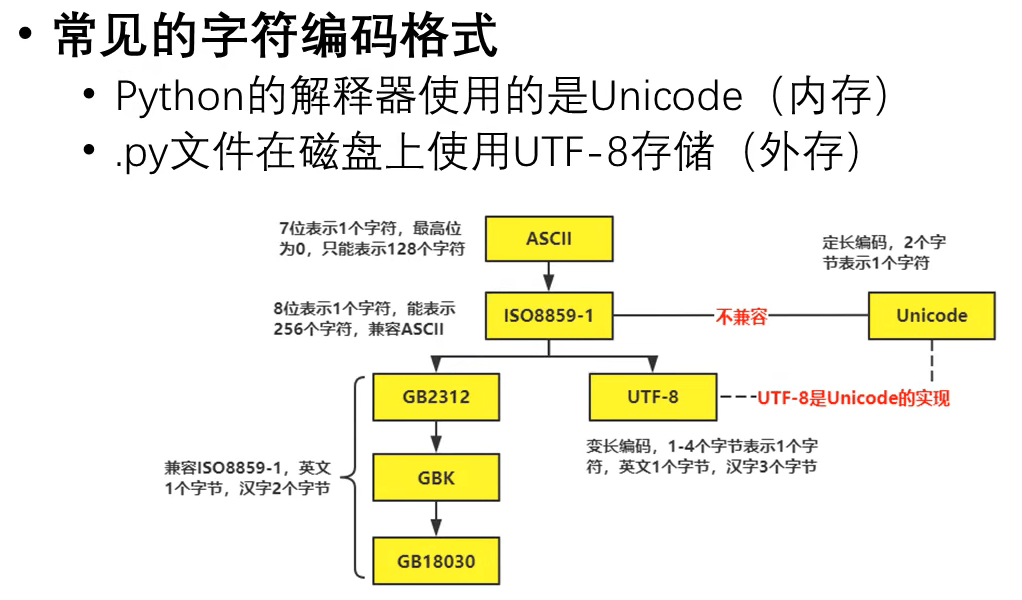
编码格式介绍
文件读写
使用内置函数
open()创建或打开文件对象,语法如下:被创建的文件对象=open(要创建或打开的文件名称,[打开方式(默认只读),编码格式(默认GBK)])读示例:
同目录下有a.txt文件:hello,worldfile=open("a.txt","r") #r为只读 print(file.readlines()) file.close写示例:
同print 教程中写入文件的示例test = open('D:\desktop\新建文件夹\新建文本文档.txt','a+') print("hello world" ,file = test) file.close()
常用文件打开方式
文件的类型
- 文本文件:储存的是普通字符文本,默认为unicode 字符集,可以使用记事本打开
- 二进制文件:把数据内容用“字节”进行储存,无法用记事本打开,必须使用专用的软件打开。如.mp3、.jpg、.doc 文件
打开模式 描述 r 以只读模式打开,文件的指针将会放在文件开头 w 以只写模式打开,如果文件不存在则创建,存在则覆盖原有内容,文件指针将会放在文件开头 a 以追加模式打开,如果文件不存在则创建,文件指针在文件开头;存在则在文件末尾追加内容,文件指针在文件末尾 b 以二进制方式打开文件,不能单独使用,需要与其他模式一起使用,如 rb 或 wb + 以读写方式打开文件,不能单独使用,需要与其他模式一起使用,如 a+
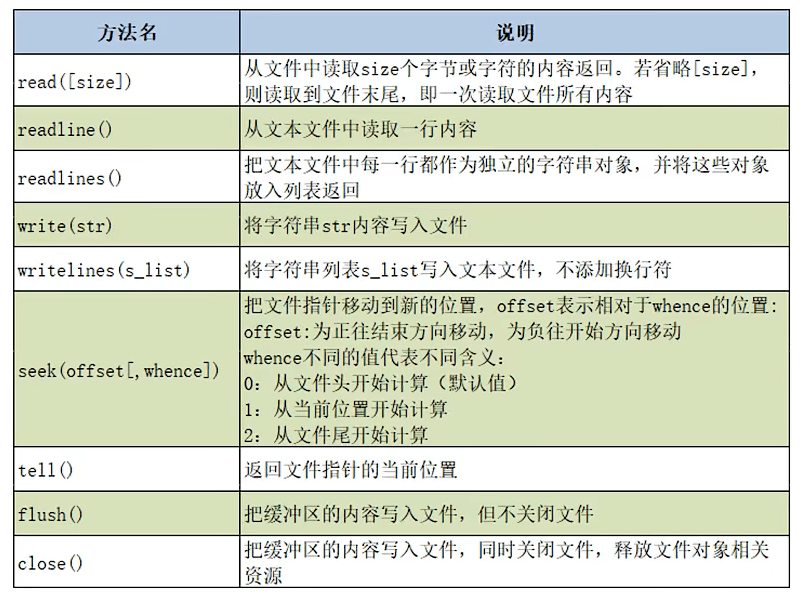
文件对象常用方式
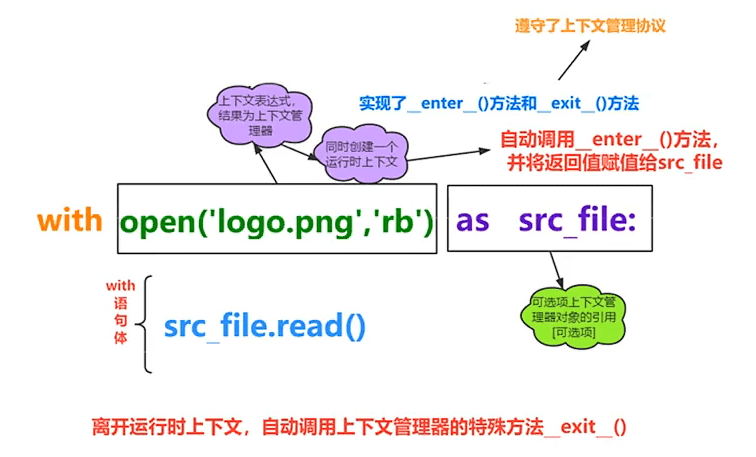
with 语句(上下文管理器)
- with 语句可以自动管理上下文资源,不论什么原因跳出 with 块,都能确保文件正确的关闭,以此来达到释放资源的目的
os 模块的常用函数
os 模块是 Python 内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
os 模块与 os.path 模块用于对目录或文件进行操作
示例:
#os模块是与操作系统相关的一个模块 import os os.system("notepad.exe") #运行系统命令,打开记事本 #直接调用可执行文件 os.startfile("D:\\Edge\\Edge\\msedge.exe") #调用系统文件,打开edge
| 函数 | 说明 |
|---|---|
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path[,mode]) | 创建目录 |
| makedirs(path1/path2/…[,mode]) | 创建多级目录 |
| rmdir(path) | 删除目录 |
| removedirs(path1/path2/…) | 删除多级目录 |
| chdir(path) | 将 path 设置为当前工作目录 |
os.path 模块的常用函数
| 函数 | 说明 |
|---|---|
| abspath(path) | 用于获取文件或目录的绝对路径 |
| exists(path) | 用于判断文件或目录是否存在,返回 true 或 false |
| join(path,name) | 将目录与目录或者文件名拼接起来 |
| splitext() | 分离文件名和拓展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 用于判断是否为路径 |
打包.py 为可执行文件.exe
安装执行库 pyinstaller(在 cmd 执行)
pip install pyinstaller如果是控制台运行,记得最后使用 os 模块中的 system 暂停
import os os.system("pause")在想要打包文件存放的目录下执行 cmd,也可以之间使用 Vscode 的终端自动获取目录,执行下列语句(区分大小写)
pyinstaller -F(单文件)/D(目录) -c(带控制台)/w(不带控制台) (-i 文件目录地址,这里是改.exe的显示图标,图片需要为.ico格式) 主文件目录上述(-i)内容选写,仅用来修改图标,如果输入没错但图标没变,是由于操作系统缓存的问题,可以复制到别的目录查看即可解决
打包后文件在 dict 目录中,多余文件可以删除
如果报错,可以使用 cmd 查看错误原因(需要带控制台,可以重新打包变为带控制台再 debug)
D:(进入盘符) cd 目录 .exe文件名(直接输入即可运行)如果有运行依赖的文件,需要一起放在 dist 目录下,否则会无法运行



如果较为紧急,建议添加微信或QQ,并注明来意
评论系统可能加载较慢,请耐心等待或刷新重试