初识 C 语言
章节概要:C 语言的特点;计算机工作原理;高级计算机语言;编译器;编程步骤;C 编程机制
特点
设计特性:
C 语言融合了计算机科学理论和实践的控制特性
C 语言的设计理念让用户轻松完成自顶向下的规划、结构化编程和模块化设计
高效性:
C 语言充分利用计算机的优势,因此程序更紧凑,运行速度很快
C 语言具有通常汇编语言才具有的微调控制能力,可以更具具体情况微调程序以获得最大运行速度或最有效地使用内存可移植性:
C 是可移植的语言,这意味着,在一种系统中编写的 C 程序稍作修改或不修改就能在其他系统上运行
注意程序中针对特殊硬件设备(如显示监视器)或操作系统特殊功能编写的部分通常不可移植
C 语言与 UNIX 关系密切,UNIX 系统通常会将 C 编译器作为软件包的一部分
供个人计算机使用的 C 编译器很多,因此在各个版本的操作系统上,都可以找到合适的 C 编译器强大而灵活:
C 语言功能强大而灵活
UNIX 操作系统、其他语言(FORTRAN、Perl、Python、Pascal)等的编译器和解释器都是用 C 语言编写的面向程序员:
C 语言是为了满足程序员的需求而设计的,程序员可以利用 C 访问硬件、操控内存中的位
大多数 C 实现都有一个大型的库,包含众多有用的 C 函数,可以让程序员更加方便地使用 C 语言
通俗了解计算机工作原理
- 简而言之,计算机的工作原理是:如果希望计算机做某些事,就必须为其提供特殊的指令列表(程序),确切地告诉计算机要做的事以及如何做。你必须用计算机能直接明白的语言(机器语言)创建程序。这是一项繁杂、乏味、费力的任务
高级计算机语言与编译器
- 高级编程语言(如 C 语言)以多种方式简化了编程工作。首先,不必用数字码表示指令;其次,使用的指令更贴近你如何想这个问题,而不是类似计算机那样繁琐的步骤
- 编译器是把高级语言程序翻译成计算机能理解的机器语言指令集的程序,在计算机看来,高级语言指令就是一堆无法理解的无用数据。由此,程序员进行高级思维活动,而编译器则负责处理冗长乏味的细节工作
使用 C 语言的 7 个步骤
C 是编译型语言,我们把编写 C 语言的程序分解为七个步骤:
1、定义程序的目标
2、设计程序
3、编写代码
4、编译
5、运行程序
6、测试与调试程序
7、维护和修改代码
编程机制
- 用 C 语言编写程序时,编写的内容被储存在文本文件中,该文件被称为源代码文件(source code file)。大部分 C 系统,都要求文件名以
.c结尾 - C 编程的基本策略是,用程序把源代码文件转换成可执行文件(其中包含可直接运行的机器语言代码)
典型的 C 实现通过编译和链接两个步骤来完成这一过程。编译器把源代码转换成中间代码,连接器把中间代码和其他代码合并,生成可执行文件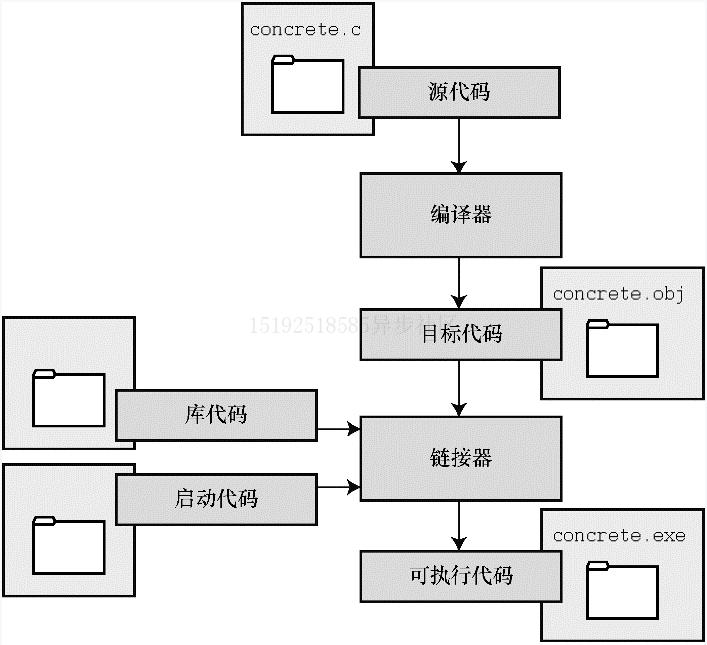
C 语言概述
章节概要:C 语言程序简单示例;
#include与头文件;主函数main;注释;花括号;声明与变量;赋值;printf函数;return语句;C 语言程序基础结构;多条声明;打印多个值;多个函数;关键字和保留标识符
简单的 C 程序示例及分析
示例程序
#include <stdio.h> int main(void) //一个简单的C程序 { int num; //定义一个名为num的变量 num = 1; //为num赋一个值 printf("I am a simple "); //使用printf函数 printf("computer.\n"); printf("my favourite number is %d because it is first.\n", num); return 0; }程序分析及知识概要
#include指令和头文件1、
#include <stdio.h>在程序的第一行,该语句作用相当于把stdio.h文件中的所有内容都输入该行所在位置,本质上是一种“拷贝-粘贴”的操作。include文件提供了一种方便的途径共享许多程序共有的信息
2、#include这行代码是一条 C预处理器命令,通常,C 编译器在编译前会对源码做一些准备工作,即预处理
3、所有的 C 编译器软件都提供stdio.h头文件,该文件包含供编译器使用的IO 函数(I:input 输入,O:output 输出)。该文件名含义为标准输入/输出头文件。通常,C 程序顶部的信息集合被称为头文件main()函数1、
main()函数是程序的主函数,它是程序的入口点,从这里开始执行
2、int main()中int是函数的返回类型,表明函数返回操作系统的是整数,此处将在后续探讨
3、如果浏览旧式的 C 代码,会发现程序如main()开始,C90 标准勉强接受这种形式,但 C99 和 C11 标准不允许,因此不要这样写
4、你还会看到void main()的形式,部分编译器允许这样写,但所有标准都未认可,因此也不要这样写注释
1、注释是一种记录程序信息的方式,被注释的部分不会被程序运行
2、可以使用/*注释内容*/进行注释,此类注释可以换行注释,直到*/为止
3、也可以使用//进行注释(C99 新加入),此类注释不能换行,直到行尾为止花括号
1、程序中花括号
{}把main()括起来,一般而言,所有的C 函数都使用花括号标记函数体的开始和结束
2、花括号还可用于把函数中多条语句合并为一个单元和块声明与变量
1、
int num;这行代码叫做声明,声明是 C 语言中最重要的特性之一
2、该条例中,声明完成了两件事。其一,函数中有一个名为num的变量,其二,int表示num的数据类型是一个整数
3、int是 C 语言中的一个关键字,表示一种基本的 C 语言数据类型。关键字是语言定义的单词,不能用做其他用途,例如不可作为函数名或变量名
4、num是一个标识符,也就是一个变量、函数或其他实体的名称
5、把变量声明正确的为数据类型(整型、浮点型、字符等),计算机才能正确的存储、读取和解释数据
6、变量的命名,要尽可能使用有意义的变量名或标识符,如程序需要一个变量属羊,则可起名sheep_count。变量命名时仅可以使用大小写字母、数字和下划线,且第一个字母不能是数字赋值
1、
num = 1是赋值表达式语句,赋值是 C 语言的基本操作之一,意为“把值 1 赋给变量num”
2、在执行int num声明时,编译器在计算机内存中为变量num预留了空间,然后执行赋值表达式语句时,把值存储在预留的位置
3、注意,赋值表达式语句从右侧把值赋给左侧,另外,该语句以分号;结尾printf函数1、
printf是 C 语言的一个标准函数,圆括号()表明printf是一个函数名,圆括号中的内容是从main()函数传递给printf函数的信息
2、printf函数会查看双引号中的内容(字符串),并将其打印到屏幕上
3、\n的作用是换行,\n组合代表一个换行符。换行符是一个转义列表,用于代表难以表示或无法输入的字符。如\t代表Tab 键,\b代表Backspace 键,每个转义序列都以反斜杠\开始
4、对比发现,参数中的%d被数字 1代替了,而 1 就是num的值。%d是一个占位符,其作用是指明输入num的位置return语句1、
int main(void)中的int表明函数main要返回一个整数,C 标准要求main()这样做。
2、有返回值的 C 函数要有return语句,该语句以return关键字开始,后面是待返回的值,并以分号;结尾
3、如果遗漏main函数末尾的return语句,程序在运行至最外面的}时,会自动返回一个默认值,即 0。因此此处可以省略,但在其他有返回值的函数中不可省略,所以建议保留此习惯
简单程序的结构
- 程序由一个或多个函数组成,必须有
main()函数。 - 函数由函数头和函数体组成,函数头包括函数名、传入该函数的信息类型和函数的返回值类型
- 通过函数名后的圆括号可以识别出函数,圆括号里可能为空,可能有参数
- 函数体被花括号括起来,由一系列语句、声明组成
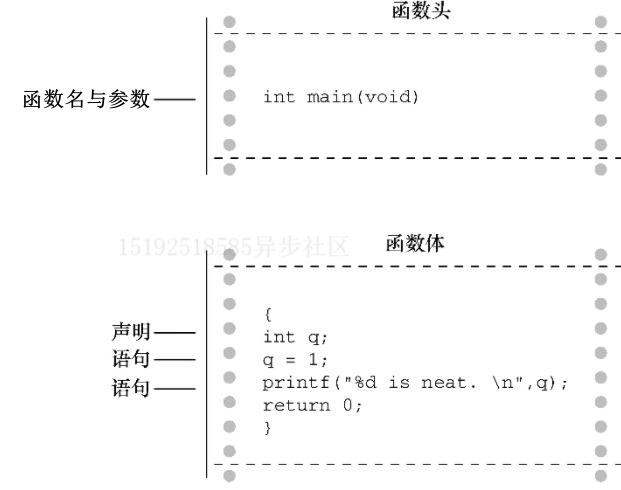
简言之,一个简单的 C 语言程序格式如下(大部分语句都以分号
;结尾):#include <stdio.h> int main(void) { //语句 return 0; }
- 程序由一个或多个函数组成,必须有
进一步使用 C
示例程序
//把2英寻转换成英尺 #include <stdio.h> int main(void) { int feet, fathoms; fathoms = 2; feet = 6 * fathoms; printf("There are %d feet in %d fathoms!\n", feet, fathoms); printf("Yes,I said %d feet!\n", 6 * fathoms); return 0; }程序分析及知识概要
多条声明
1、
int feet, fathoms;语句,使用多条声明声明了两个变量,使用逗号,隔开,此语句与int feet;+int fathoms;等价打印多个值
1、程序的第一个
printf()进行了两次替换,按顺序将feet、fathoms替换了两个%d
2、第二个printf()说明待打印的值不一定是变量,只要可求值得出合适类型值的项即可
多个函数
把自己的函数添加到程序中,此处只做简单了解,后续学习:
#include <stdio.h> void def(void) { printf("hello world!"); } int main(void) { def(); return 0; }
关键字和保留标识符
下表中粗体 表示
C90标准新增关键字,斜体 表示C99标准新增关键字,粗斜体 表示C11标准新增关键字关键字 关键字 关键字 关键字 auto extern short while break float signed _Alignas case for sizeof _Alignof char goto static _Atomic const if struct _Bool continue inline switch _Complex default int typedef _Generic do long union _Imaginary double register unsigned _Noreturn else restrict void _Static_assert enum return volatile _Thread_local
数据和 C
章节概要:交互式程序;变量与常量数据;数据;位、字节、字;存储单元换算;数据类型关键字;C 语言基本数据类型;进制打印显示;可移植类型;使用程序获得数据类型大小
交互式程序
示例程序
#include <stdio.h> int main(void) { float weight; float value; printf("Please enter your weight in pounds:"); scanf("%f", &weight); value = 1700.0 * weight * 14.5833; printf("your weight in platinum is worth $%.2f.\n", value); return 0; }新元素简单分析
1、新的变量声明,使用
float浮点数类型,浮点类型可以储存带小数的数字,详细说明见本章后面部分
2、为了打印新类型的变量(浮点数),printf处使用%f处理浮点值了
3、%.2f用于精确控制输出,指定保留小数后两位
4、scanf()函数用于读取键盘的输入,%f说明scanf()读取输入浮点数,&weight告诉scanf()把输入的值赋给名为weight的变量
5、scanf()函数使用&符号表明找到weight变量的地点,下章将详细讨论,目前请按照这样写
变量与常量数据
- 变量:有些数据类型在程序运行期间可能会改变或被赋值,这些称为变量
- 常量:有些数据类型在程序使用之前已经预先设定好了,整个程序运行过程中没有变化,称为常量
数据
位、字节、字
位、字节、字是描述计算机数据单元或存储单元的术语,这里主要指储存单元
位(bit):最小的储存单元。可以储存0 或 1,是计算机内存的基本构成块
字节(byte):常用的计算机存储单位,字节是位的集合,一个字节可以储存8 位。这是字节的标准定义,至少在衡量存储单位时是这样
字(word):是设计计算机时给定的自然存储单位,对于 8 位的微型计算机,一个字长只有 8 位。从那以后,个人计算机字节增至 16 位、32 位,直至目前的 64 位。计算机的字长越大,数据转移越快,允许的内存访问也更多存储单元换算
1 TB=1024 GB
1 GB=1024 MB
1 MB=1024 KB
1 KB=1024 Bytes(字节)
1 Byte(字节)=8 bits(位)
1 Word(字)=2 Bytes(字节)整数
- 和数学概念一样,整数是没有小数部分的数,例如 2、-23、2456 都是整数
- 计算机以二进制数字存储整数,如整数 7 二进制写为 111,因此要在8 位字节中存储该数字,需要前 5 位设置为0,后 3 位设置为1

浮点数
- 带有小数点的数就是浮点数,例如 2.75、3.16E7、7.00、2e-8 都是浮点数
- 注意,在一个值后面加上小数点,该值就成为一个浮点数,所以7 是整数,7.00 是浮点数
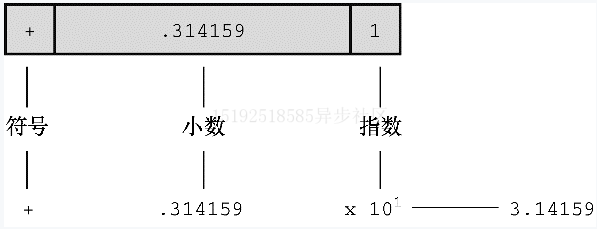
- 此处简要介绍 e/E 计数法(科学计数法):3.16E7 或 3.16e7 表示 3.16 * 107
- 这里关键要理解浮点数与整数的储存方案不同,计算机把浮点数分成小数部分和指数部分表示,而且分开存储这两部分。7.0写成0.7E1,这里,0.7 是小数部分,1 是指数部分。计算机在内部使用二进制和2 的幂进行储存,后续探讨(此处图例以十进制下理解为例)
数据类型关键字
| 最初 K&R 给出的关键字 | C90 标准添加的关键字 | C99 标准添加的关键字 |
|---|---|---|
| int | signed | _Bool |
| long | void | _Complex |
| short | _Imaginary | |
| unsigned | ||
| char | ||
| float | ||
| double |
C 语言基本数据类型
int类型1、C 语言中的整数类型可表示不同的取值范围和正负值,一般情况下使用
int能应付绝大多数情况
2、int类型是有符号整型,即int的值必须是整数,可以是正整数、负整数、0
3、int类型的取值范围因计算机系统而异,一般而言,储存一个int要占用一个机器字长
4、早期16 位的取值范围为-215 ~ 215-1,即-32768 ~ 32767,ISO C 规定int最小范围为-32768 ~ 32767
5、一般来说,系统会用一个特殊位的值(未使用的第 16 位)表示有符号整数的正负号
6、使用%d打印整数类型,%d称为转换说明,他指定应该用什么格式显示一个值
7、显示不同进制:使用%d显示十进制,%o显示八进制,%x显示十六进制。显示前缀使用%#o、%#x、%#X#include <stdio.h> int main(void) { int x = 100; printf("dec=%d ; octal=%o ; hex=%x \n", x, x, x); printf("dec=%#d ; octal=%#o ; hex=%#X", x, x, x); return 0; }其他整数类型
1、
short类型:占用空间可能比int少,有符号类型
2、long类型:占用空间可能比int多,有符号类型
3、long long类型(C99 加入):占用空间可能比long多,至少 64 位,有符号类型
4、unsigned类型:非负整型,16 位取值范围 0 ~ 216-1,即0 ~ 65535
5、C90 后,新增unsigned short、unsigned long;C99 后,新增unsigned long long
6、在任何有符号类型前添加关键字signed,可强调使用有符号类型的意图
7、空间“可能”多与少是因为 C只规定了short不能多于int,long不能少于int
8、现在个人计算机常见设置是,long long占64 位,long占32 位,int占16 位或32 位,short占16 位
9、打印时,使用%u打印unsigned类型,使用%ld打印long类型,使用%lld打印long long类型,使用%hd打印short类型浮点数类型
1、浮点类型能表示包括小数在内更大范围的数,浮点数的表示类似科学计数法。在计算机中,科学计数法中的 10 的指数,跟写在字母
e后面,如 1.02 * 103记作1.02e3
2、单精度浮点数float,C 语言规定其至少能表示6 位有效数字,且取值范围至少是 10-37 ~ 1037。通常,系统储存一个浮点数要占用 32 位,其中 8 位用于表示指数的值和符号,剩下 24 位用于表示非指数部分及其符号
3、双精度浮点数double,其与float类型的最小取值范围相同,但必须至少能表示10 位有效数字,一般来说,double占用 64 位而非 32 位。一些系统将多出来的 32 位全用来表示非指数部分,不仅增加有效数字位数(即精度),还减少了舍入误差;另一些系统把其中一些位分配给指数部分,以容纳更大的指数,增加可表示数的范围。无论哪种类型,double类型的值至少有 13 位有效数字
4、long double,可以满足比double更高的精度要求,不过,C 只保证long double类型至少与double类型的精度相同
5、浮点数后面加上f或F后缀可覆盖默认设置,编译器会将浮点型常量看做float类型,如2.3f,9.11E9F;使用l或L后缀使数字成为long double类型;没有后缀的浮点型常量是double类型
6、打印浮点值时,使用%f打印float类型,用%e打印指数计数法的浮点值,如果系统支持十六进制的浮点数,使用%a打印十六进制的浮点值,打印double或long double要使用%Lf、%Le和%La的转换说明char字符类型1、
char类型用来储存字符,如字母或标点符号
2、从技术层面来看,char是整数类型,因为char类型实际储存的是整数而不是字符。计算机使用数字编码来处理字符,即用特定整数代表特定字符
3、C 常用编码为ASCII编码,其中如整数 65代表大写字母 A,整数 97代表小写字母 a,整数 48代表数字 0
4、标准ASCII 码范围为0~127,只需 7 位二进制数即可表示。通常,char被定义为8 位的存储单元
5、C 语言把1 字节定义为char类型占用的位(bit)数
6、char赋值时,需要传入char 字符类型的数据,即单引号''包裹的字符,如char set = 'A'。此外也可使用ASCII 码进行赋值,如char set = 65
7、有一些代表行为的非打印字符,如换行、退格、回车、蜂鸣等,这些字符打印不出来。如需要表示这些字符,可以使用ASCII 码,比如蜂鸣:char beep = 7。此外也可以使用转义字符,如char beep = '\a'
8、使用%c打印char类型字符,如果使用%d打印,则会打印字符对应 ACSII 码的整数转义序列 含义 \a 警报(ANSI C) \b 退格 \f 换页 \n 换行 \r 回车 \t 水平制表符 \v 垂直制表符 \\ 反斜杠() \‘ 单引号(‘) \0oo 八进制值( oo必须是有效的八进制数,即每个o可表示0~7中的一个数)\xhh 十六进制值( hh必须是有效的十六进制数,即每个h可表示0~f中的一个数)_Bool布尔类型1、C99标准新增了
_Bool类型,用于表示布尔值,即逻辑值true和false
2、因为 C 语言用值 1表示true,值 0表示false,所以_Bool类型实质上也是一种整数类型
3、原则上它仅占用1 位存储空间,因为对与0 和 1而言,一位的存储空间足够了可移植类型:
stdint.h和inttypes.h1、C99新增两个头文件
stdint.h和inttypes.h,以确保 C 语言各类型在各系统中功能正常
2、C 语言为现有类型创建了更多类型名,这些新类型名被定义在stdint.h中
3、如在精确宽度整数类型中,int32_t表示 32 位的有符号整数类型。在使用32 位系统时,头文件会把int32_t当做int的别名;而在int为16 位,long为32 位的系统中,系统会把int32_t当做long的别名。然后,使用int32_t类型编写程序并包含stdint.h头文件时,编译器会把int或long替换成与当前系统匹配的类型
4、如果系统不支持精确宽度整数类型,可以使用最小宽度类型,例如int_least8_t是可容纳 8 位有符号整数值的类型中宽度最小的类型的一个别名
5、如果更关心速度而非空间,则可使用最快最小宽度类型,如int_fast8_t被定义为系统中对8 位有符号值而言运算最快的整数类型
6、如果需要最大整数类型,最大的有符号整数类型intmax_t可储存任何有效的有符号整数值。类似的,uintmax_t表示最大的无符号整数类型,这种类型可能比long long和unsigned long long更大
7、C 标准针对这种输入和输出,提供了一些字符串宏来显示可移植类型,例如inttypes.h中定义了PRId32字符串宏,代表打印32 位有符号值的合适转换说明(如 d 或 l)#include <stdio.h> #include <inttypes.h> int main(void) { int32_t me32; me32 = 45933945; printf("me32 = %" PRId32 "\n", me32); return 0; }复数和虚数
1、许多科学和工程计算都要用到复数和虚数,C99支持复数和虚数,但是有所保留
2、复数类型:有float_Complex、double_Complex和long double_Complex。例如float_Complex变量应包含两个float类型的值,分别表示复数的实部和虚部
3、虚数类型:有float_Imaginary、double_Imaginary和long double_Imaginary
4、如果包含complex.h头文件,便可用complex代替_Complex,用imaginary代替_Imaginary,还可以用 1 代替-1 的平方根其他类型
1、C 语言中没有字符串类型,却也能很好的处理字符串,详见后续
2、C 语言还有一些基本类型衍生的其他类型,如数组、指针、结构、联合,详见后续
3、本章程序案例简单使用到了指针,如scanf()函数用到的&前缀,便创建了一个指针,告诉scanf()把数据放在何处
获取类型大小
可以使用
sizeof()获取以字节为单位的类型大小,C99和C11提供%zd匹配sizeof()返回值,其余不支持的编译器可用%u或%lu代替#include <stdio.h> int main(void) { printf("Type int has a size of %zd bytes.\n", sizeof(int)); printf("Type char has a size of %zd bytes.\n", sizeof(char)); printf("Type float has a size of %zd bytes.\n", sizeof(float)); return 0; }
字符串和格式化输入输出
章节概要:字符串简介;char 类型数组与 null 字符;
strlen()函数;常量与 C 预处理器;明示常量;printf()函数;参数传递;scanf()函数;scanf多个输入与返回值
引入示例
示例程序
#include <stdio.h> #include <string.h> #define DENSITY 62.4 // 定义人体密度 int main(void) { float weight, volume; int size, letters; char name[40]; printf("Hi! What's your first name?\n"); scanf("%s", name); printf("%s,whats's your weight in pounds?\n", name); scanf("%f", &weight); size = sizeof(name); letters = strlen(name); volume = weight / DENSITY; printf("well, %s, your volume is %2.2f cubic feet\n", name, volume); printf("Also, your first name has %d letters,\n", letters); printf("and we have %d bytes to store it.\n", size); return 0; }新元素简单分析
- 用数组储存字符串。在该程序中,用户输入的名被储存在数组中,该数组占用内存中40 个连续的字节,每个字节储存一个字符值
- 使用
%s转换说明来处理字符串的输入和输出。注意,在scanf中,name没有&前缀,而weight有(稍后解释,&weight和name都是地址) - 用 C预处理器把字符常量
DENSITY定义为 62.4 - 用 C 函数
strlen()获取字符串的长度
字符串简介
1、字符串是一个或多个字符的序列,如
"I came from America"
2、双引号"不是字符串的一部分,仅是告知编译器它括起来的是字符串,就如单引号'用于标识单个字符一样
char 类型数组与 null 字符
1、C 语言没有专门用于存储字符串的变量类型,字符都被储存在
char类型数组中。数组由连续的存储单元组成,字符串的字符被储存在相邻的存储单元中,每个单元储存一个字符
2、数组末尾位置有一个空字符(\0),C 语言用空字符(null)标记字符串结束。这意味着数组容量必须比存储字符数多 1
3、数组是同类型数据元素的有序序列,方括号[]表示这是一个数组
4、使用%s来转换打印一个字符串
5、字符串与字符char不是同一种类型,因为字符串最后有空字符标识,而char只存储该字符
6、使用strlen()函数可以得到字符串的字符长度,且strlen()并不会计入空字符
常量与 C 预处理器
为什么要使用常量
1、使用常量名比数字表达的信息更多,如
area = PI * d与area = 3.14 * d相比更加直观
2、对于程序中多次使用同一个常量时,如果常量的值需要修改,只需要修改常量值即可如何创建符号常量
- 可以定义变量,将其值定义为所需的值,但这样程序可能会无意间改变它的值
- 使用C 预处理器定义,格式为
#define 常量名 值,编译程序时,所有的常量名都会被替换为它们的值- 定义常量时,习惯上建议全用大写,以此告知他人这是一个常量,提高程序可读性;此外也有小众习惯使用
c_变量名或k_变量名表示常量 - 注意:
define常量名后的内容用于替换符号常量,不要将#define NUM 20写成#define NUM = 20,这样定义的WORD值为=20而非20
- 定义常量时,习惯上建议全用大写,以此告知他人这是一个常量,提高程序可读性;此外也有小众习惯使用
- C90标准新增限定词
const,表示只读,也可用此作为常量使用(其只表明只读变量),如const float PI=3.14
明示常量
C 头文件
limits.h与float.h分别提供与整数与浮点数类型大小限制相关的说明,如limits.h中有类似以下代码:#define INT_MAX +32767 #define INT_MIN -32768这些明示常量代表
int类型可表示的最大值和最小值,该头文件会为这些明示常量提供不同的值,如果系统使用32 位的 int且程序包含limits.h头文件,则可以使用printf()与%d转换输出该常量 32 位 int 的值如果系统使用4 字节的 int,该头文件将提供符合 4 字节的对应值
下为
limits.h中的一些明示常量:明示常量 含义 CHAR_BIT char 类型的位数 CHAR_MAX char 类型的最大值 CHAR_MIN char 类型的最小值 SCHAR_MAX signed char 类型最大值 SCHAR_MIN signed char 类型最小值 UCHAR_MAX unsigned char 类型的最大值 SHRT_MAX short 类型的最大值 USHRT_MAX unsigned short 类型的最大值 INT_MAX int 类型的最大值 UINT_MAX unsigned int 类型的最大值 LONG_MAX long 类型的最大值 ULONG_MAX unsigned long 类型的最大值 LLONG_MAX long long 类型的最大值 ULLONG_MAX unsigned long long 类型的最大值 相似的,
float.h头文件下也有一些明示常量:明示常量 含义 FLT_MANT_DIG float 类型的尾数位数 FLT_DIG float 类型的最小有效数字位数(十进制) FLT_MIN_10_EXP 带全部有效数字的 float 类型的最小负指数(以 10 为底) FLT_MAX_10_EXP float 类型的最大正指数(以 10 为底) FLT_MIN 保留全部精度的 float 类型最小正数 FLT_MAX float 类型的最大正数 FLT_EPSILON 1.00 和比 1.00 大的最小 float 类型值之间的差值
printf()函数
请求
printf()打印数据的指令要与待打印数据类型相匹配。例如,打印整数使用%d,打印字符使用%c。这些符号称为转换说明,它们指定如何把数据转换成可显示的形式。ANSI C标准为
printf()提供的转换说明转换说明 输出 %a 浮点数、十六进制数和 p 计数法 %A 浮点数、十六进制数和 p 计数法 %c 单个字符 %d 有符号十进制整数 %e 浮点数,e 计数法 %E 浮点数,e 计数法 %f 浮点数,十进制计数法 %g 根据值的不同,自动选择%f 或%e。%e 格式用于指数小于-4 或者大于等于精度时 %G 根据值的不同,自动选择%f 或%E。%E 格式用于指数小于-4 或者大于等于精度时 %i 有符号十进制整数(与%d 相同) %o 无符号八进制整数 %p 指针 %s 字符串 %u 无符号十进制整数 %x 无符号十六进制整数,使用十六进制数 0f %X 无符号十六进制整数,使用十六进制数 0F %% 打印一个百分号 prinft()的转换说明修饰符,在%与转换字符之间插入修饰符可修饰基本转换说明修饰符 含义 标记 本表格下一张表格描述了 5 种标记(-、+、空格、#、0),可以不使用标记或使用多个标记,如 %-10d数字 最小字段宽度,如果该字段不能容纳待打印内容则会使用更宽的字段,如 %4d.数字 精度。对于 %e和%f转换,表示小数点右边数字位数 ; 对于%g转换,表示有效数字的最大位数 ; 对于%s转换,表示待打印字符最大数量 ; 对于整型转换,表示待打印数字的最小位数。如有必要,使用前导 0 达到这个位数,只使用.表示其后跟随一个 0,所以%.f与%.0f相同。如%5.2f表示打印一个字段宽度为 5,小数点后有 2 位数字的浮点数h 和整型转换说明一起使用,表示 short int 或 unsigned short int 类型的值,如 %hu、%hx、%6.4hdhh 和整型转换说明一起使用,表示 signed char 或 unsigned char 类型的值,如 %hhu、%hhx、%6.4hhdj 和整型转换说明一起使用,表示 intmax_t 或 uintmax_t 的值,这些类型定义在 stdint.h中l 和整型转换说明一起使用,表示 long int 或 unsigned long int 类型的值 ll 和整型转换说明一起使用,表示 long long int 或 unsigned long long int 类型的值 L 和浮点转换说明一起使用,表示 long double 的值 t 和整型转换说明一起使用,表示 ptrdiff_t 类型的值,ptrdiff_t 是两个指针差值的类型(C99) z 和整型转换说明一起使用,表示 size_t 类型的值,size_t 是 sizeof 返回的类型(C99) 注:
%u标记不能把数字和符号分开,会报错!!printf()中的标记标记 含义 - 待打印项左对齐,即从字段左侧开始打印该项,如 %-20s+ 有符号值若为正,则在值前面显示加号(正号),若为负则显示减号(负号),如 %+6.2f空格 有符号值若为正,则在值前面显示前导空格(不显示任何符号),若为负则显示减号(负号)覆盖前导空格,如 % 6.2f# 把结果转换成另一种形式。如果是 %o格式,则从 0 开始 ; 如果是%x格式,则从 0x 开始 ; 如果是浮点格式,#则保证了即使后面没有任何数字也打印一个小数点 ; 如果是%g格式,#防止结果后面的 0 被删除0 对于数值格式,使用前导 0 代替空格填充字段宽度 ; 对于整数格式,如果出现-标记或指定精度,则忽略该标记
参数传递
参数传递机制因实现而异,下面以本机系统中的本程序分析参数传递。该调用告诉计算机把变量 n1、n2、n3、n4的值传递给程序,是一种常见的传参方式
#include <stdio.h> int main(void) { float n1 = 3.0; double n2 = 3.0; long n3 = 2000000000; long n4 = 1234567890; printf("%ld %ld %ld %ld", n1, n2, n3, n4); return 0; }1、程序把传入的值放入被称为栈的内存区域,计算机根据变量类型(不是转换说明)把值放入栈中。
2、因此,n1被储存在栈中,占 8 字节(float 被转换成 double 类型)。同样,n2在栈中也占8 字节,而n3、n4分别占4 字节
3、然后,控制转到printf(),其根据转换说明从栈中读取值。%ld转换说明表明应读取 4 字节,所以printf()读取前 4 字节作为第 1 个值。这是n1 前半部分,将被解释成long 类型整数,根据下一个转换说明,printf()再读取 4 字节,这是n1 后半部分,将被解释为第 2 个 long 类型整数
4、类似的,继续读取第 3、4 个%ld,读取为n2 的前、后半部分,并解释成两个 long 类型整数
5、因此,对于n3、n4虽然用对了转换说明,但还是读错了字节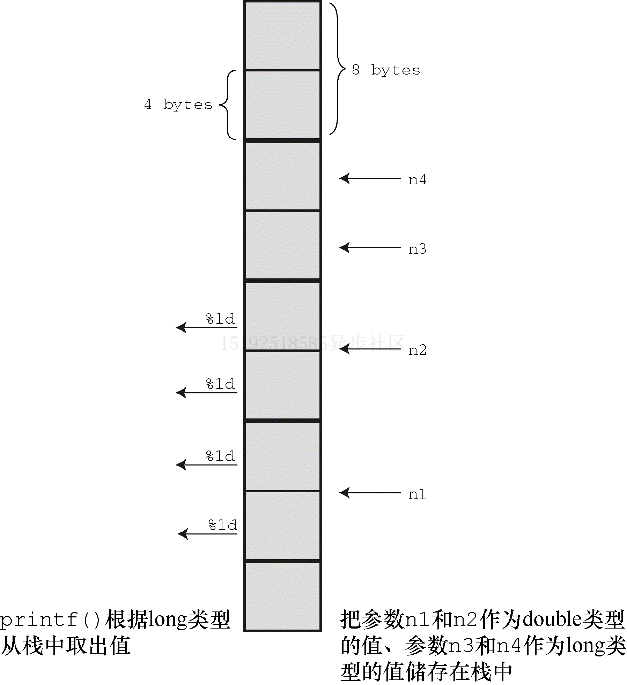
scanf()函数
scanf()是最通用的输入函数,因为它可以读取不同格式的数据,其将输入的字符串转换成整数、浮点数、字符或字符串scanf()使用指向变量的指针,而printf()使用变量、常量、表达式scanf()的多个输入1、可以通过
scanf("%d%d",&n,&m)的格式输入多个数据
2、scanf()函数允许把普通字符放在格式字符串中,除空格外的字符必须与输入字符串严格匹配
3、如scanf("%d,%d",&n,&m),用户必须输入两个整数,并以逗号分隔
4、除了%c,其他转换说明都会自动跳过待输入值前面的所有空白scanf()的返回值scanf()函数返回成功读取的项数
如果没有成功读取任何项,且需要读取一个数字而用户输入一个数值字符串,其便返回0
当scanf()检测到“文件结尾”时,会返回EOF。这是stdio.h中定义的特殊值,通常会用#define将其定义为-1ANSI C标准为
scanf()准备的转换说明和转换说明修饰符scanf的转换说明与修饰符与printf的基本一致,但过程上从转换输出变成了解释输入,具体使用方法参考printf的表格
运算符、表达式和语句
章节概要:
while循环简述;运算符;赋值术语;sizeof运算符和size_t类型;表达式、语句和块;语句术语;类型转换;强制类型转换;带参数的函数;形参实参
while 循环简述
示例程序
#include <stdio.h> #define ADJUST 6.37 int main(void) { const double SCALE = 0.333; double shoe, foot; printf("Shoe size (men's) foot length\n"); shoe = 3.0; while (shoe < 10.5) { foot = SCALE * shoe + ADJUST; printf("%10.1f %15.2f inches\n", shoe, foot); shoe = shoe +1; } printf("If the shoe fits , wear it.\n"); return 0; }while 循环
1、当条件语句为真时,执行循环体。圆括号内为关系表达式,花括号内为循环体
2、该程序中,程序判断shoe < 18.5是否为真,执行循环体内的代码,到达花括号时再次判断表达式,为真则继续执行,当条件语句为假时,结束循环
运算符
赋值运算符: =
1、C 语言中,等号
=意为赋值而非相等。赋值运算符将右侧的值赋给左侧
2、当赋值运算符连用时,如a=b=c=10,仍按照从右向左方式链式赋值,即c=10,b=c,a=b几个术语:数据对象、左值、右值、项
数据对象:赋值表达式语句的目的是把值储存到内存位置上,用于储存值的数据存储区域统称为数据对象
左值:是 C 语言的术语,用于标识特定数据对象的名称或表达式。因此,对象指的是实际的数据储存,而左值是用于标识或定位储存位置的标签
右值:指的是赋值给可修改左值的量,且本身不是左值
项:学习名称时,被称为项的就是运算对象(如,赋值运算符左侧的项)。运算对象是运算符操作的对象
基本算术运算符
1、加法运算符
+、减法运算符-、乘法运算符*、除法运算符/
2、加和减都被称为二元运算符
3、C 语言中的除法,若变量类型为整数,则除法的商的小数部分会被舍弃符号运算符: +和-
1、
+和-还可以做符号运算符,用作正负号
2、用作正负号时,为一元运算符取模(余)运算符
1、用于整数运算,得到相除的余数,如
9 % 2 = 1
2、负数求模,C99后,若第一个运算对象为负数,那么取模的结果为负数,反之亦然。如11 % -5 = 1,-11 % 5 = -1,-11 % -5 = -1递增/减运算符: ++和--
1、下文以
++为例
2、两种形式:++出现在变量前,为前缀模式;++出现在变量后,为后缀模式
3、该运算符作用为变量自加一,如a++意为a = a + 1
4、当单独使用递增运算符时,使用哪种形式都没关系
5、当使用较为复杂时,则会不同。如q = 2*++a;,意为a 递增 1,后 2*a,再将结果赋给 q;而q = 2*a++;,意为2*a,后将结果赋给 q,再 a 递增 1
6、由于前后缀模式的以上特性会对代码产生不同的影响,因此最好单独使用(如需复合使用时,可以先单独自增再使用)sizeof 运算符和 size_t 类型
1、第 3 章已介绍,
sizeof运算符用于以字节为单位返回运算对象的大小
2、C 语言规定,sizeof返回size_t类型数值,这是一个无符号整数类型,其为语言定义的标准类型
3、C99后使用%zd用于转换显示size_t类型,如不支持可以使用%u或%lu代替
表达式、语句和块
表达式
1、表达式由运算符和运算对象组成。最简单的表达式是单个运算对象,以此为基础可以建立复杂的表达式
2、运算对象可以是常量、变量或二者的组合
3、每个表达式都有一个值,如q=5*2作为一个整体的值为 10;表达式q>3的值为布尔值,为true或false,即值为 1 或 0语句
1、语句是 C 程序的基本构建块,一条语句相当于一条完整的计算机指令,C 中大部分语句都以分号
;结尾
2、最简单的语句为空语句,只有一个分号构成;C 把末尾加上一个分号的表达式也看做语句,因此8;,3+4;这些语句也没问题,只是在程序中什么都不做副作用、序列点、完整表达式
1、副作用:副作用是对数据对象或文件的修改。例如语句
states=50;,其副作用为修改变量 states 的值为 50。这似乎是主要目的,而在C 语言的角度看,主要目的是对表达式求值,如表达式4+6求值得10,给出表达式states=50求值得50
2、序列点:是程序执行的点,在该点上,所有的副作用都在进入下一步之前发生。语句中的分号标记了一个序列点,另外,任何完整表达式的结束也是一个序列点
3、完整表达式:指这个表达式不是另一个更大表达式的子表达式
复合语句(块)
复合语句:是用花括号括起来的一条或多条语句,复合语句也称为块
类型转换
通常,在语句和表达式中,应使用类型相同的变量和常量。但是,如果使用混合类型,C 会采用一套规则进行自动类型转换,虽然这很便利,但有一定危险性,尤其是在无意间混合使用类型的情况下
基本的类型转换规则
1、当类型转换出现在表达式时,无论是
unsigned还是signed的char和short都会被自动转换成int,如有必要会被自动转换成unsigned int(如果short和int大小相同,unsigned short就比int大,此时unsigned short会被转换成unsigned int)。由于都是较小类型转换为较大类型,所以这些转换被称为升级
2、涉及两种类型的运算,两个值会被分别转换成两种类型的更高级别
3、类型的级别从高至低依次是:long double、double、float、unsigned long long、long long、unsigned long、long、unsigned int、int。例外的情况是,当long和int大小相同时,unsigned int级别比long的级别高。之所以short和char没有列出,是因为它们已经被升级成了int或unsigned int
4、在赋值表达式语句中,计算的最终结果会被转换成被赋值变量的类型,因此该过程可能导致类型升级或降级
5、当作为函数参数传递时,char和short被转换成int,float被转换成double。第九章将介绍,函数原型会覆盖自动升级强制类型转换
- 通常,应该避免自动类型转换,尤其是类型降级,但如果能小心使用,类型转换也很方便
- 当需要进行精确的类型转换,或者在程序中表明类型转换的意图,此时要用到强制类型转换
- 强制类型转换:在某个量前面放置用圆括号
()括起来的类型名,该类型名即是希望转换成的目标类型。圆括号和它括起来的类型名构成了强制类型转换运算符,其通用形式为(type),例子为score = (int)1.6 + (int)1.7
带参数的函数
示例程序
#include <stdio.h> void pound(int n) // 定义函数 { while (n-- > 0) { printf("#"); } printf("\n"); } int main(void) { int times = 5; char ch = '!'; float f = 6.0; pound(times); pound(ch); pound(f); return 0; }参数-形参、实参
- 首先,看函数头
void pound(int n),如果函数不接受任何参数,那么圆括号中应写上void。由于该函数接受一个int类型的参数,所以其中包含一个int类型的变量 n的声明。参数名应遵循 C 语言的命名规则 - 声明参数就创建了被称为形式参数的变量(简称形参),该例中,形式参数是 int 类型的变量 n;像
pound(10)这样的函数调用会把 10 赋给 n ,我们称函数调用传递的值为实际参数(简称实参) - 函数调用
pound(10)把实参 10传递给函数,函数将 10 赋给形参 - 变量名是函数私有的,即在函数中定义的变量名不会和别处的相同名称发生冲突
- 首先,看函数头
函数调用
- 现在,来学习函数调用,如第一次调用
pound(times),times的值5被赋给n,因此函数打印了5 个井号和一个换行符 - 第二次调用
pound(ch),此时ch是char类型变量,被初始化为!,其ASCII 码为33。由于函数形参类型为int,与char不匹配,所以程序开头的函数原型发挥了作用;原型即函数声明,描述函数返回值和参数,pound原型说明了两点:1、函数没有返回值(函数名前关键字为
void)
2、函数有一个int类型的形参 - 函数原型告诉编译器,函数接受一个
int类型的参数,当编译器执行到pound(n)时,参数ch被自动转换成int类型,于是从1 字节的 33变成了4 字节的 33。于此类型,第三次调用pound(f)也使得float类型转换成合适的int类型
- 现在,来学习函数调用,如第一次调用
C 控制语句:循环
章节概要:再探
while循环;while循环语句;迭代;关系运算符与关系表达式;真(true)与假(false);bool布尔变量;for循环;for的几种使用示例;复合赋值运算符;出口条件循环do-while;循环嵌套;数组简介;函数返回值的使用
再探 while 循环
示例程序
#include <stdio.h> int main(void) { long num; long sum = 0L; int status; printf("Please enter an integer to be summed"); printf("(q to quit):"); status = scanf("%ld", &num); while (status == 1) { sum = sum + num; printf("Please enter next integer (q to quit):"); status = scanf("%ld", &num); } printf("Those integer sum to %ld.\n", sum); return 0; }新元素分析
- sum初始值为
0L,为long类型的0,而非int类型的0 ==为相等运算符,用于判断前后值是否相等,不要与=赋值运算符混淆scanf()函数的返回值,返回成功读取项的数量,因此此处读取1 个整数,则成功后返回1
- sum初始值为
while 循环语句
while 循环语句格式
while(关系表达式){ 循环体; }迭代:在循环的关系表达式为假(0)之前,循环的判断和执行一直重复进行,每一次循环都被称为一次迭代
循环条件
- 在构建循环时,必须让测试表达式的值有变化,表达式最终要为假(0),否则循环就不会停止
- 可以使用
while(1)来构建简单的死循环,之后会将到如何破除循环 - 注意循环终止的时间,只有大括号内的语句会循环执行,注意哪些语句需要循环执行,哪些不需要
关系运算符与关系表达式
关系运算符
==:相等运算符,用于判断前后值是否相等,不要与=赋值运算符混淆!=:不等运算符,用于判断前后值是否不相等<:小于运算符,用于判断前值是否小于后值>:大于运算符,用于判断前值是否大于后值<=:小于等于运算符,用于判断前值是否小于等于后值>=:大于等于运算符,用于判断前值是否大于等于后值真(true)与假(false)
1、关系表达式会产生真(true)和假(false)的值,真(true)值通过打印会得到为1,假(false)值通过打印会得到为0
2、因此while循环判断的实际为表达式的真假值
3、而在 C 语言中,一般所有非 0 的值都可以被识别为真(true),只有0被识别为假(false)_Bool 布尔变量
1、C99新增了
_Bool布尔类型变量,其只能储存真(true)和假(false),所有其他非零数值都会被转换为真(true)
2、stdbool.h头文件让bool成为了_Bool的别名,还把true和false分别定义为1和0的符号常量
3、且使用该头文件的代码可以与C++兼容,因为C++把bool、true、false定义为关键字
for 循环
示例程序
#include <stdio.h> int main(void) { const int NUMBER = 22; int count; for (count = 1; count <= NUMBER; count++) { printf("Be my Valentine\n"); } return 0; }for 循环格式
for(初始化;测试条件;执行更新){ 循环体 }1、
for后面的括号中有三个表达式,分别用两个分号;隔开
2、第 1 个表达式是初始化,只会在for循环开始时执行一次
3、第 2 个表达式是测试条件,测试条件为真(true)时执行循环体,测试条件为假(false)时结束循环
4、第 3 个表达式是执行更新,每次循环结束时求值for 的灵活性
for循环十分灵活,可以利用三个表达式完成几乎所有需要的条件判断,使用for循环能更轻松清楚地完成遍历逗号运算符
,使得循环头可以包含更多表达式,如for(i=0,a=10; i<a; i=i+2,a++)for循环的其他几种妙用#include <stdio.h> int main(void) { //输出20内平方表 printf("数字 平方\n"); for (int i = 1; i <= 20; i++) { printf("%-11d %-11d\n", i, i * i); } return 0; }#include <stdio.h> int main(void) { //输出ASCII码表 printf("字符 ASCII码\n"); for (char i = 'A'; i <= 'z'; i++) { printf("%-11c %-11d\n", i, i); } return 0; }#include <stdio.h> int main(void) { //输出20内的、平方小于350的偶数 //注: &&为“与”,表示两者皆满足;i+=2同i=i+2 for (int i = 0; i <= 20 && i * i < 350; i += 2) { printf("%d\n", i); } return 0; }
复合赋值运算符
复合赋值运算符:
+=、-=、*=、/=、%=符号赋值运算符:
+=表示加法赋值,如a+=2意义等同于a=a+2,其余以此类推
出口条件循环 do-while
是
while循环的一种变种,while为入口处判断,do-while为出口处判断特点为第一次执行,无论如何
do-while的循环体至少执行一次,出口处再判断是否下次循环。如下程序即使count 初始值大于 22,也会执行一次do 内循环体示例程序
#include <stdio.h> int main(void) { int count=1; do { printf("Be my Valentine\n"); count++; } while (count < 22); return 0; }
循环嵌套
示例程序
#include <stdio.h> int main(void) { //输出乘法表 for (int i = 1; i <= 9; i++) { for (int j = 1; j <= i; j++) { printf("%d*%d=%-2d ", j, i, i*j); } printf("\n"); } return 0; }循环嵌套
1、循环嵌套指在循环内包含另一个循环,执行顺序为外层循环过程中执行多次内层循环,两个循环的大括号分别标识自己的循环体部分
2、如上述示例程序乘法表,通过最内层printf能得知,使用j表示乘法表第一个数字,使用i表示第二个数字,使用i*j表示乘法的积
3、通过j<=i的循环条件防止出现2*3后再次出现3*2重复
4、建议自己运行一次程序,感受循环的顺序,也可以改变几个数值,看看程序的变化
数组简介
在许多程序中,数组很重要。数组可以作为一种储存多个相关元素的便利方式,将在第十章详细介绍
数组
1、数组是按顺序存储的一系列类型相同的值,如 10 个
char类型数值或 10 个int类型数值
2、整个数组有一个数组名,通过整数下标访问数组中单独的项或元素数组声明与使用
数组声明:示例
int a[15],表示声明一个内涵 15 个元素的整数数组
数组使用:通过下标访问指定元素。数组的第一个元素为a[0],第二个元素为a[1],以此类推。实际上数组元素的使用与同类型变量相同
陷阱:考虑到 C 执行速度,C 编译器不会检查数组下标是否正常,注意数组元素不要超出定义的范围
下标:用于标识数组元素的数字叫做下标、索引或偏移量。下标必须是整数且要从 0 开始计数for 循环中使用数组
for循环的数组使用,可以通过利用循环变量的变化来切换数组的元素,示例如下:#include <stdio.h> int main(void) { int a[10]; //循环输入 for (int i = 0; i < 10; i++) { scanf("%d", &a[i]); } //循环输出 for (int i = 0; i < 10; i++) { printf("%-5d ", a[i]); } return 0; }
函数返回值的使用
对于有返回值的函数,函数最后的
return语句表示函数的返回值,即执行完函数后,函数返回的值编写一个有返回值的函数,需要注意以下几点:
1、定义函数时,确定函数的返回类型
2、使用return表明待返回的值示例程序
#include <stdio.h> // double 函数名 表明函数返回一个double类型的值 double power(double n, int p) { double pow = 1; for (int i = 1; i <= p; i++) { pow *= n; } // 返回pow的值 return pow; } int main(void) { // a^b double a; int b; printf("输入底数:"); scanf("%lf", &a); printf("输入指数:"); scanf("%d", &b); // 调用函数 printf("乘方结果:%lf", power(a, b)); return 0; }
C 控制语句:分支和跳转
章节概要:
if语句;if-else语句与else-if语句;if与else的配对和嵌套if;getchar()与putchar()函数;ctype.h系列的字符函数;逻辑运算符;备选拼写:iso646.h头文件;条件(三目)运算符;循环辅助:continue和break;switch语句;goto语句
if 语句
示例程序
#include <stdio.h> int main(void) { int a, b; scanf("%d%d", &a, &b); if (a > b) { printf("Sure,A>B!\n"); } printf("Over!"); return 0; }if 语句
1、
if语句被称为分支语句或选择语句,因为它相当于一个交叉点,程序要在两条分支中选择一条执行
2、程序如果对分支表达式求值为真,则执行执行语句,否则跳过执行语句
3、if语句的通用形式如下if (分支表达式){ 执行语句; }
if-else 语句与 else-if 语句
if-else 语句
1、简单的
if语句可以让程序选择执行一条语句或跳过,而if-else语句可以在两条语句之间做选择
2、程序如果对分支表达式求值为真,则执行执行语句 1,否则执行执行语句 2
3、if-else语句的通用形式如下if (分支表达式){ 执行语句1; } else{ 执行语句2; }else-if 语句
1、
else-if语句为多重选择语句,可以在多个分支之间做选择
2、程序会根据表达式是否为真逐步判断,特别注意,如果第一个表达式为真,则不会继续向下执行
3、else-if语句的通用形式如下if (分支表达式1){ 执行语句1; } else if (分支表达式2){ 执行语句2; } else{ 执行语句3; }
if 与 else 的配对和嵌套 if
当一个程序有多个
if和else,如果没有花括号,else将与离它最近的if配对,除非最近的 if 被花括号括起来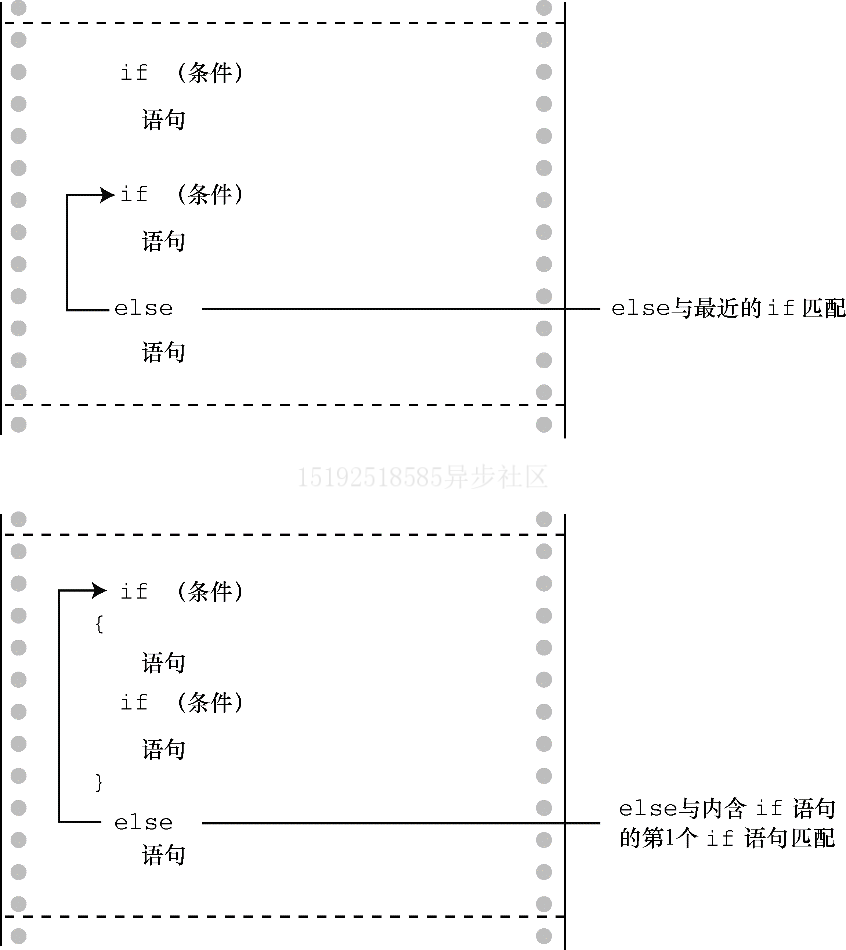
有关
if的嵌套,与for的嵌套基本雷同,只需要注意不同嵌套的花括号包括的范围即可
getchar()与 putchar()函数
getchar()与 putchar()的使用
1、
getchar()函数用于从标准输入流中读取一个字符,并将其存储在变量中
2、如把字符储存进变量ch,则写为ch = getchar(),其等效于scanf("%c", &ch)
3、putchar()函数用于打印它的参数
4、如打印ch的值,则写为putchar(ch),其等效于printf("%c",ch)
5、由于这些函数只处理字符,所以比scanf与printf更快更轻量,而且不需要转换说明探索如何工作的程序示例
#include <stdio.h> int main(void) { char ch; ch = getchar(); // 读取第一个字符 while (ch != '\n') // 当不为换行符时循环,即一行字符未结束时 { if (ch == ' ') // 留下空格不变 { putchar(ch); } else { putchar(ch + 1); //其他字符改变+1 } ch = getchar(); //获取下一个字符 } putchar(ch); //打印换行符 return 0; }该程序可以进行优化,将如下形式的循环替换为后者
ch = getchar(); while (ch != '\n'){ ... ch = getchar(); }while ( (ch=getchar()) != '\n'){ ... }这样的写法体现了C 特有的编程风格——把两个行为合并成一个表达式
程序中的
putchar(ch+1);语句,再次演示了字符实际上是作为整数储存的
ctype.h 系列的字符函数
C 有一系列专门用于处理字符的函数,
ctype.h头文件包含了这些函数的原型。这些函数接受一个字符作为参数,如果该字符属于某特殊的类别,则返回true,否则返回falsectype.h的字符测试函数函数名 如果是下列参数,返回值为 true isalnum() 字母或数字 isalpha() 字母 isblank() 标准的空白字符(空格、换行、水平制表符)或其他本地指定为空白的字符 iscntrl() 控制字符,如 Ctrl+Bisdigit() 数字 isxdigit() 十六进制数字符 isgraph() 除空格以外的任意可打印字符 islower() 小写字母 isupper() 大写字母 isprint() 可打印字符 ispunct() 标点符号(除空格和字母数字以外的任何可打印字符) isspace() 空白符(空格、换行、换页、回车、垂直或水平制表符、其他本地定义的空白符) ctype.h的字符映射函数函数名 行为 tolower() 如果参数是大写字符,则函数返回小写,否则返回原始参数 toupper() 如果参数是小写字符,则函数返回大写,否则返回原始参数
逻辑运算符
C 语言的
if和while语句通常需要使用关系表达式作为测试条件。有时需要多个关系表达式组合,来判断多个条件的逻辑关系,逻辑运算符便可满足这一需求3 种逻辑运算符
1、
&&逻辑与:如果连接的两个表达式都为 true,则返回 true
2、||逻辑或:如果连接的两个表达式至少有一个为 true,则返回 true
3、!逻辑非:如果表达式为 true,则返回 false;如果表达式为 false,则返回 true逻辑运算符优先级
1、
!优先级最高、&&优先级次之、||优先级最低
2、!的优先级仅次于圆括号,比乘法运算符还高。&&、||的优先级都比关系运算符低,比赋值运算符高
3、因此,表达式a>b && b>c || b>d相当于((a>b) && (b>c)) || (b>d)备选拼写:iso646.h 头文件
- 由于 C 使用标准美式键盘开发,部分键盘并没有美式键盘的符号。使用
iso646.h头文件,可以使用and、or、not分别代替&&、||、!
- 由于 C 使用标准美式键盘开发,部分键盘并没有美式键盘的符号。使用
条件(三目)运算符
C 提供条件(三目)运算符作为表达
if-else的一种便捷方式,常用于为一个变量判断赋值或输出的值时使用三目运算符的使用
- 基本语法:
测试条件 ? 结果true执行表达式 : 结果false执行表达式 - 例如
a = (num<0) ? -y : y;等效于如下语句:if (num < 0) { a = -y; } else { a = y; } - 三目运算符也可以嵌套使用,使用小括号表明不同层级部分
- 基本语法:
循环辅助:continue 和 break
语句功能
continue语句:在循环过程中,如果执行到continue语句,则会从continue执行处跳过本层本次循环的剩余内容,继续执行下一次循环break语句:在循环过程中,如果执行到break语句,则会从break执行处终止本层循环且跳过未执行内容,不再进行下一次本层循环语句优势
1、可以更加灵活的控制循环的执行
2、能够减少不必要的if-else层级缩进,提高代码的可读性
3、使代码语句结构更清晰紧凑
switch 语句
使用条件运算符和
if-else语句很容易编写二选一的程序,然而有时程序需要从多个选项中选择,尽管可以使用else if实现,但大多情况下switch更加方便基本语法
switch (表达式){ case 表达式的可能值1: 语句; break; case 表达式的可能值2: 语句; break; ... default: 语句; break; }注意事项
1、
break语句使程序离开switch语句,直接执行switch后的下一条语句,如果没有break,则会按顺序将条件成立处向后所有case内语句执行完毕,直到default语句后退出
2、C 语言的case一般都指定一个值,不能使用一个范围
3、关于switch不使用break会向后执行的特性,可以在特定的地方设定break,来利用这个特性,如下设计统计字母出现次数的程序#include <stdio.h> int main(void) { char ch; // 输入字母 int a_ct, b_ct, c_ct, d_ct, e_ct; // 统计abcde的次数 a_ct = b_ct = c_ct = d_ct = e_ct = 0; // 初始化为0 printf("enter some text;enter # to quit"); while ((ch = getchar()) != '#') { switch (ch) { case 'a': // 检测a时执行,并会向下执行'A'的语句 case 'A': // 不论大写小写a,都会执行语句计入统计 a_ct++; break; // break终止继续执行 // 以此类推,此处省略bcde的case } } printf("A B C D E\n"); printf("%-4d%-4d%-4d%-4d%-4d", a_ct, b_ct, c_ct, d_ct, e_ct); return 0; }swith 与 if-else
1、通常而言,
switch能干的if-else都能实现,但switch的运行速度更快
2、当需要判断一个范围或浮点变量或表达式时,switch无法实现
3、switch通常只是if-else的优化,对比之下,仍是if-else泛用性更强
goto 语句
早期版本的BASIC和FORTRAN所依赖的
goto语句,在 C 中仍然可用,但非常不建议使用,即使没有goto语句 C 语言也仍能运行良好,且逻辑更加清晰基本语法
语句标签(如:part1):语句 goto 语句标签;
字符输入输出与输入验证
章节概要:单字符 I/O:
getchar与putchar;缓冲区;完全缓冲 I/O 与行缓冲 I/O;结束键盘输入(C 处理文件的方式);文件;流;检测文件结尾;C 语言的EOF;重定向和文件;UNIX、Linux 和 DOS 重定向(流的输送)、重定向注意事项;创建更友好的用户界面;处理缓冲输入的换行符;处理混合数值字符输入的错误;输入验证
单字符 I/O:getchar 与 putchar
在第七章中提到过,
getchar()和putchar()每次只处理一个字符。可能这种方法过于笨拙,但这种方法很适合计算机。而且,这是绝大多数文本处理程序所用的核心方法详细用法请参照前一章
为何输入的字符能直接显示在屏幕上?如果用一个特殊字符(如
#)来结束输入,就无法在文本中使用这个字符。是否有更好的办法结束输入?首先要了解C 程序如何处理键盘输入,尤其是缓冲和标准输入文件的概念
缓冲区
缓冲输入与缓冲区
缓冲输入:对于程序输入,大部分系统在用户按下
Enter之前不会重复打印刚输入的字符,即在重复输入字符时,不会在终端出现H(输入)H(输入后处理输出的字符)e(第二格输入的字符)elllloo这样的情况。这种输入形式称为缓冲输入
缓冲区:用户输入的字符会先被收集并储存在一个被称为缓冲区的临时储存区,按下Enter时,程序才可使用用户输入的字符
为什么要有缓冲区
1、把若干字符作为一个块传输比逐个发送这些字符节约时间
2、如果用户打错字符,可以直接通过键盘修正,当最后按下Enter时,传输的是正确的输入
3、虽然缓冲输入好处很多,但某些交互式程序也需要无缓冲输入,比如在游戏中,希望按下一个按键就立刻执行相应的指令。因此缓冲输入和无缓冲输入都有用武之地完全缓冲 I/O 与行缓冲 I/O
完全缓冲输入:指当缓冲区被填满时才刷新缓冲区(内容被发送至目的地),通常出现在文件输入中。缓冲区大小取决于系统,常见512 字节和4096 字节
行缓冲输入:指在出现换行时刷新缓冲区。键盘输入通常是行缓冲输入,所以在按下Enter时才刷新缓冲区使用缓冲输入还是无缓冲输入
1、ANSI C和后续的 C 标准都规定输入是缓冲的,不过最初 K&R 把这个决定权交给了编译器的编写者
2、ANSI C决定把缓冲输入作为标准输入的原因是:一些计算机不允许无缓冲输入
3、ANSI C没有提供调用无缓冲输入的标准方式,这意味着能否进行无缓冲输入取决于计算机系统
结束键盘输入(C 处理文件的方式)
文件、流和键盘输入
文件
1、文件是储存器中储存信息的区域。通常,文件都保存在某种永久储存器中(如硬盘、U 盘、DVD 等)。
2、毫无疑问,文件对于计算机系统相当重要。例如你编写的C 程序就保存在文件中,用来编译 C 程序的程序也保存在文件中
3、某些程序需要访问指定的文件。当编译储存在名为echo.c文件中的程序时,编译器打开echo.c文件并读取其中的内容,当编译器处理完后,会关闭该文件
4、其他程序,例如文字处理器,不仅要打开、读取、关闭文件,还要把数据写入文件C 语言与文件
1、C 是一门强大、灵活的语言,有许多用于打开、读取、写入、关闭文件的库函数
2、从较低层面上,C 可以使用主机操作系统的基本文件工具直接处理文件,这些直接调用操作系统的函数被称为底层 I/O。但计算机系统各不相同,所以不可能为普通的底层 I/O函数创建标准库
3、从较高层面上,C 还可以通过标准 I/O 包来处理文件。这涉及创建用于处理文件的标准模型和一套标准 I/O 函数。这一层面上,具体的C 实现负责处理不同系统的差异,以便用户使用统一的界面流(stream)
1、从概念上看,C 程序处理的是流,而不是直接处理文件
2、流是一个实际输入或输出映射的理想化数据流。这意味着不同属性和不同种类的输入,由属性更统一的流来表示
3、于是,打开文件的过程就是把流与文件关联,而且读写都通过流来完成
文件结尾
操作系统检测文件结尾
1、计算机操作系统要以某种方式判断文件的开始和结束,其中一种方法是,在文件末尾放一个特殊的字符标记文件结尾
2、CP/M,IBM-DOS,MS-DOS的文本文件曾经都用过这种方法。如今这些操作系统可以使用内嵌的Ctrl+Z字符来标记文件结尾
3、这曾经是操作系统使用的唯一标记,不过现在有一些其他选择,如记录文件的大小。所以现代的文本文件不一定有嵌入的Ctrl+Z,但如果有,操作系统会将其视为一个文件结尾的标记,如后附图
4、操作系统使用的另一种方法是储存文件大小的信息。如果文件有3000 字节,那么读到 3000 字节时便达到文件的末尾
5、MS-DOS及其相关系统使用这种方法处理二进制文件,因为用这种方法可以在文件中储存所有的字符。新版的DOS也使用这种方式处理文本文件。UNIX使用这种方式处理所有的文件
C 语言检测文件结尾
1、在 C 语言中,用
getchar()读取文件检测到文件结尾时,会返回特殊值EOF(End Of Line 缩写)。scanf()检测到文件结尾时也返回EOF
2、通常,EOF被定义在stdio.h文件中:#define EOF (-1)关于 EOF
1、为什么是选用-1?因为
getchar()函数的返回值介于0~127,这些值对应标准字符集。但是如果系统能识别拓展字符集,则返回值可能在0~255。但无论哪种情况,-1都不对应任何字符,所以选用-1 标记文章结尾
2、某些系统也许把EOF定义为-1 以外的值,但是定义的值一定与输入字符所产生的返回值会不同。如果包含stdio.h文件,并使用EOF符号,就不必担心值不同的问题。这里关键要理解EOF是一个值,标志着检测到文件结尾,并不是在文件中找得到的符号
3、如何在程序中使用?把getchar()的返回值和EOF比较,如果不同则没有到达文件结尾,即如下:while((ch = getchar()) != EOF)键盘模拟文件结尾条件
#include <stdio.h> int main(void) { int ch; while ((ch = getchar()) != EOF) { putchar(ch); } return 0; }1、不用定义
EOF,因为stdio.h已经定义过了
2、不用担心EOF的实际值,因为EOF在stdio.h中用#define预处理指令定义,可直接使用
3、变量ch的类型从char变成了int,因为char的变量只能表示0~255的无符号整数,但EOF的值是-1。还好getchar()函数实际返回值类型是int,所以它可以读取EOF字符。如果实现使用有符号的char类型,也可以把ch声明为char,但最好还是用更通用的形式
4、由于getchar()返回类型是int,如果把getchar()的返回值赋给char变量,一些编译器可能会警告甚至丢失数据
5、ch是整数不会影响putchar(),该函数仍然会打印等价字符
6、使用该程序进行键盘输入,要设法输入EOF字符,不能只输入字符 EOF,也不能只输入数值-1(会被当做一个连字符和一个数字 1)。正确的方法是找出当前系统的要求,如大多数UNIX和Linux系统中在一行开始使用Ctrl+Z会传输文件结尾信号,而Windows系统中在一行开始使用Ctrl+Z会传输文件结尾信号,所以在程序中需要设立不同的提示语提醒用户
重定向和文件
默认情况下,C 程序使用标准 I/O包查找标准输入作为输入源,这就是前面介绍过的stdin 流,它是把数据读入计算机的常用方式
程序使用文件的两种方式
1、显式使用特定的函数打开、关闭、读取、写入文件,将在第 13 章介绍
2、设计能与键盘和屏幕互动的程序,通过不同的渠道重定向输入至文件和从文件输出,下面主要介绍此类重定向UNIX、Linux 和 DOS 重定向
UNIX(运行命令行模式)、Linux(ditto)和 Windows 命令行(注意使用cmd而不是终端)提示都能重定向输入输出。重定向输入让程序使用文件而不是键盘输入,重定向输出让程序输出至文件而不是屏幕
重定向输入
1、假设已经编译了echo.c程序,并生成了一个名为echo的可执行文件(Windows 中为echo.exe,注意后续命令注意使用带有文件后缀的名字)。想要运行该程序,在命令行的对应目录中输入可执行文件名:
./echo,Windows下输入echo.exe,即可执行可运行文件
2、现在,假设要用该程序处理名为 passage的文本文件(.txt),文件中储存的是可识别的字符。此处由于操作对象是字符,所以使用文本文件。使用此命令代替上面的命令:./echo < passage,Windows下输入echo.exe < passage.txt
3、<符号是 UNIX 和 DOS/Windows 的重定向运算符。该运算符使passage 文件与stdin 流相关联,把文件中的内容导入 echo 可执行程序重定向输出
1、类似的,假设要用echo 可执行程序把程序输出的内容发送到名为 passage 的新文件,便可以使用
./echo > passage,Windows 下输入echo.exe > passage.txt
2、>符号是第二个重定向运算符,创建了一个名为passage 的新文件,然后把 echo 的输出写入该文件。通常会擦除该文件的内容,然后替换新的内容,在下一行开始处按下Ctrl+D(UNIX)或Ctrl+Z(DOS)即可结束该程序组合重定向
1、现在假设你希望制作一份mywords 文件的副本,并命名为 savewords,输入
./echo < mywords > savewords,Windows 下输入echo.exe < mywords.txt > savewords.txt
2、下面的命令也起作用,因为命令与重定向运算符的顺序无关,如:./echo > savewords < mywords
3、在一条命令中,输入文件名和输出文件名不能相同,如:./echo < mywords > mywords <==错误,原因是> mywords在输入之前已导致原 mywords 长度被截断为 0其他重定向注意事项
1、重定向运算符连接一个可执行程序和一个数据文件,不能直接连接两个可执行文件或连接两个数据文件
2、使用重定向运算符不能读取多个文件的输入,也不能把输出定向至多个文件
3、文件名和运算符之间空格不是必须的,且有些系统不能使用空格
4、UNIX、Linux 或 Windows/DOS 还有>>运算符,该运算符可以把数据添加到现有文件的末尾且不覆盖原内容,而|运算符能把一个文件的输出连接到另一个文件的输入
创建更友好的用户界面
使用缓冲输入
示例程序(待优化程序)
#include <stdio.h> int main(void) { int guess = 1; printf("在1-100想一个数,输入y或n表示当前显示的数是否是你想的数\n"); printf("数字是1吗\n"); while (getchar() != 'y') { printf("那么,是%d吗\n", ++guess); } printf("好的,这便是你想的数字"); return 0; }该示例程序有以下问题,对于用户的体验有影响
1、缓冲输入要求用户按下
Enter发送,这一动作也传递了换行符,程序必须妥善处理这个换行符
2、用户的输入可能并不会按照人为约定只输入y 或 n,仍有其他输入的可能,也需要对应进行处理
处理缓冲输入的换行符
该程序每次输入 n 时,程序便打印了两条消息。这是由于程序读取 n作为用户否定了数字 1,另外读取了一个换行符作为用户否定了数字 2。此外输入 no,会打印三条语句,程序将 n 和 o 分别当做了一次响应,外加换行符的一次响应
优化 1:跳过剩余输入
1、使用
while循环,循环丢弃输入行最后剩余的内容,包括换行符
2、这种方法还能把no、no way都视为简单的n(因为只使用第一个字符,其余字符被丢弃)while(getchar() != 'y') { printf("那么,是%d吗\n", ++guess); while(getchar() != '\n') { continue; //跳过剩余输入行 } }优化 2:使用变量储存响应以进行判断
1、上述方法 1虽然解决了换行符的问题,但程序仍会将f视为n
2、可以添加一个char类型变量储存响应,再用if判断筛选其他响应char response; while((response = getchar()) != 'y') { if (response == 'n') { printf("那么,是%d吗\n", ++guess); } else { printf("未知输入\n"); } while(getchar() != '\n') { continue; //跳过剩余输入行 } }
混合数值和字符输入
示例程序(待优化程序)
#include <stdio.h> void display(char cr, int lines, int width) { // 该函数用于输出 int row, col; for (row = 1; row <= lines; row++) { for (col = 1; col <= width; col++) { putchar(cr); } printf("\n"); } } int main(void) { int ch, rows, cols; printf("输入要打印的字符、行数、每行个数\n"); while ((ch = getchar()) != '\n') { scanf("%d%d", &rows, &cols); display(ch, rows, cols); printf("输入另一组数据继续,输入换行退出\n"); } printf("Bye!"); return 0; }该示例程序有以下问题,对于用户的体验有影响
1、
getchar()与scanf()各自使用都能完成各自的任务,但尽可能不要将它们混用。getchar()读取每个字符,包括空格换行制表符,scanf()会跳过空格换行制表符,上述程序便因此出错
2、当程序输出完第一组数据,就直接退出了,无法输入第二组数据
3、在第一次输入的最后一个数字后的换行符,scanf()将其留在了输入队列里,而getchar()不会跳过换行符。所以进入下一次迭代时,getchar()便读取了该换行符,将其赋给ch
处理混合数值字符输入的错误
优化:跳过一轮输入结束与下一轮输出开始之间所有的换行符和空格
/*修改主函数的while循环*/ while ((ch = getchar()) != '\n') { if((scanf("%d%d", &rows, &cols)) != 2) { break; } display(ch, rows, cols); while(getchar() != '\n') { continue; } printf("输入另一组数据继续,输入换行退出\n"); }
输入验证
在实际应用中,用户不一定会按照程序的指令行事,用户的输入和程序期望的输入不匹配时常发生。因此需要输入验证,预料一些可能的输入错误,并提前编写处理错误的程序
假设编写了一个处理非负整数的循环,提前推演可能出现的错误,便可以按如下方式处理:
防止出现负数,使用关系表达式排除此种情况:
long n; scanf("%ld", &n); // 获取第一个值 while (n >= 0) // 判断是否为非负数 { // 处理n(此处省略处理语句) scanf("%ld", &n); // 继续获取下一个值 }防止输入错误类型的值,判断
scanf()返回值排除,并结合上处错误改进:long n; while (scanf("%ld", &n)==1 && n>=0) { // 处理n(此处省略处理语句) }对于上处程序,当用户输入错误的值,会直接结束程序。此外还可以提示用户再次输入正确的值,但这种情况下,需要处理有问题的输入。因为
scanf()的错误输入仍会留在输入队列,可以使用getchar()函数逐字读取输入,还可以将其结合在一个函数内,按如下改进:long get_long(void) { long input; char ch; while (scanf("%ld", &input) != 1) { while ((ch = getchar()) != '\n') { putchar(); // 处理错误的输入 } printf("输入有误,请重新输入\n"); } return input; }
函数
章节概要:复习函数;函数概述;函数创建与使用;函数参数与返回值;ANSI C 函数原型;旧式声明问题及解决;递归;递归演示;递归的基本原理;尾递归;递归和倒序计算;递归的优缺点;编译多源代码文件的程序;使用(自建)头文件;查找地址:&运算符;更改主调函数中的变量;指针简介;指针基本概念;间接运算符:*;声明指针;使用指针在函数间通信
复习函数
函数概述
函数:完成特定任务的独立程序代码单元。语法规则定义了函数的结构和使用方式
功能
1、执行某些动作:如
printf()把数据打印到屏幕
2、找出一个值供程序使用:如strlen()把指定字符串的长度返回给程序优点
1、可以省去编写重复代码的苦差
2、让程序更加模块化
3、提高代码的可读性
4、方便后期修改、完善
函数创建与使用
示例程序
/*定义并使用starbar函数打印40个星号*/ #include <stdio.h> void starbar(void); // 函数原型 int main() // 主函数 { starbar(); // 调用函数 printf("hello world\n"); starbar(); return 0; } void starbar(void) // 定义函数 { for (int i=1;i<=40;i++){ putchar('*'); } putchar('\n'); }函数基础
基本术语
1、函数原型:告诉编译器函数
starbar()的相关信息。其指明了函数的返回值类型和函数接收的参数类型,这些信息称为函数的签名
2、函数调用:表明在此执行函数
3、函数定义:指定函数具体要做什么工作
4、补充:函数原型与函数定义可以在同一步完成,即函数原型void starbar(void)后可以直接跟花括号进行定义。此外函数原型可以置于main()主函数内声明变量处函数类型
1、函数和变量一样有多种类型,任何程序在使用函数前都要声明函数类型
2、void starbar(void);中第一个void表明函数返回类型是void,即没有返回值;starbar为函数名;第二个void表明函数没有参数;分号表明仅在声明函数,不是在定义函数
3、因此,函数名前的类型仅表明函数返回值类型,而不是参数类型函数的跨文件调用
1、程序把
starbar()和main()放在一个文件中,也可以将它们分别放在两个文件下
2、把函数都放在一个文件中的单文件形式比较容易编译,而使用多个文件方便在不同程序中使用同一个函数
3、如果把函数放在单独的文件中,要把#define和include指令也放入该文件,稍后会讨论如何跨文件调用函数
函数参数与返回值
示例程序
#include <stdio.h> int plus_multiply(int num1, int num2, int num3) { int result; result = (num1 + num2) * num3; return result; } int main(void) { int a, b, c; printf("计算(a+b)*c的结果,请分别输入a,b,c的值:\n"); scanf("%d%d%d", &a, &b, &c); printf("%d", plus_multiply(a, b, c)); return 0; }形参与实参
1、形式参数:函数定义的函数头中声明的变量,称为形参
2、实际参数:出现在函数调用的圆括号内的表达式,称为实参函数参数的定义与使用
1、在函数原型的圆括号里,写入需要传入的参数的类型,以及参数名,即定义形参。语法为
void def (类型 形参1, 类型 形参2, ...),实例如void def (int a, float b)
2、使用形参,需要先传入实参。在调用函数时,按顺序传入指定类型的值(即传入实参)返回值
1、如果说参数是方便值从主调函数前往被调函数,那返回值便是方便值从被调函数前往主调函数。函数中为
return语句后的值
2、返回值的类型即为函数原型中定义的函数类型
ANSI C 函数原型
旧式声明
1、在ANSI C标准之前,声明函数的方案有缺陷,因为只需要声明函数类型,不用声明任何参数
2、如int imin()这个函数声明,只需要告知编译器init()返回 int 类型的值
3、然而,以上函数声明并未给出imin()函数的参数个数和类型。因此,如果调用imin()时使用的参数个数不对或类型不匹配,编译器根本不会察觉问题所在
示例程序
#include <stdio.h> int imax(); // 旧式声明 int main(void) { printf("%d和%d的最大值是%d\n", 3, 5, imax(3)); printf("%d和%d的最大值是%d\n", 3, 5, imax(3.0, 5.0)); return 0; } int imax(n, m) int n, m; { return (n > m ? n : m); }3和5的最大值是1606416656 3和5的最大值是3886问题分析
1、由于不同系统的内部机制不同,所以出现问题的具体情况也不同,下面介绍PC和VAX的情况
2、主调函数把它的参数储存在被称为栈的临时储存区,被调函数从栈中读取这些参数,而这两个过程并未互相协调
3、主调函数根据函数调用中的实际参数决定传递的类型,被调函数根据它的形式参数来读取值。因此,函数调用imax(3)把一个整数放在栈中,当函数开始执行时,它从栈中读取两个整数,而实际只存放了一个待读取的整数,所以读取的第二个值是当时恰好在栈中的其他值
4、第二次使用imax()函数时,它传递的是float类型的值。这次把两个double类型的值放在栈中(当 float 作为参数传递会被升级成 double)。两个 double的值就是两个 64 位的值,所以弓128 位的数据被存放在栈中。当imax()读取两个 int值时,即读取前 64 位,于是出现错误
解决方案
针对参数不匹配的问题,ANSI C标准要求在声明函数时还要声明变量的类型,即使用函数原型来声明函数的返回类型、参数数量、参数类型
未标明
imax()函数有两个int类型的参数,可以使用下面两种函数原型来声明int imax(int, int); int imax(int a, int b);第一种形式使用以逗号分隔的类型列表,第二种形式在类型后面添加了变量名。注意,这里的变量名是假名,不必与函数定义的形式参数名一致
递归
递归:C 函数允许调用它自己,这种调用称为递归。递归有时难以捉摸,有时却很方便实用
递归演示
示例程序
#include <stdio.h> void up_and_down(int n) { printf("Level %d: n location %p\n", n, &n); // #1 if (n < 4) { up_and_down(n + 1); } printf("Level %d: n location %p\n", n, &n); // #2 } int main(void) { up_and_down(1); // 调用递归函数 return 0; }Level 1: n location 000000000061FE00 Level 2: n location 000000000061FDD0 Level 3: n location 000000000061FDA0 Level 4: n location 000000000061FD70 Level 4: n location 000000000061FD70 Level 3: n location 000000000061FDA0 Level 2: n location 000000000061FDD0 Level 1: n location 000000000061FE00程序分析
1、
main()函数调用up_and_down(),称为第 1 级递归,然后up_and_down()调用自己,这次调用称为第 2 级递归,第 2 级再次调用,称为第 3 级递归,以此类推
2、%p、&用于显示变量的内存地址,稍后解释
3、首先,main()函数调用带参数 1的up_and_down()函数,此时n=1,语句#1打印Level 1,由于n<4,执行调用实际参数为n+1(即 2)的up_and_down()(第 2 级)
4、第 2 级中n=2,所以语句#1打印Level 2,以此类推继续递归调用
5、当执行到第 4 级时n=4,if语句n<4为false,所以跳过执行不再调用自己,第 4 级继续执行语句#2,打印Level 4
6、此时第 4 级调用结束,控制返回它的主调函数(即第 3 级),第 3 级继续执行语句#2,打印Level 3,以此类推,直到第 1 级返回main()函数
7、注意,每级递归的变量 n都属于每级递归私有,这点从程序输出的地址可以得出
递归的基本原理
1、每级递归调用都有自己的变量。也就是说,第 1 级的 n和第 2 级的 n是完全不同的
2、每次函数调用都会返回一次。当函数执行完毕,控制权将返回到上一级递归,程序必须按顺序逐级返回递归
3、递归函数中位于递归调用之前的语句,均按被调函数的顺序执行。例如上例按序Level 1、Level 2、Level 3、Level 4
4、递归函数中位于递归调用之后的语句,均按被调函数相反的顺序执行。例如上例按序Level 4、Level 3、Level 2、Level 1
5、虽然每级递归都有自己的变量,但是并没有拷贝函数的代码。程序按顺序执行函数中的代码,递归调用相当于又从头开始按序执行函数的代码。除了为每次递归调用创建变量外,递归调用非常类似一个循环语句
6、递归函数必须包含能让递归调用停止的语句。通常都使用if语句或其他等价的测试条件在函数形参等于某特定值时终止递归。因此,每次递归调用的形参都要使用不同的值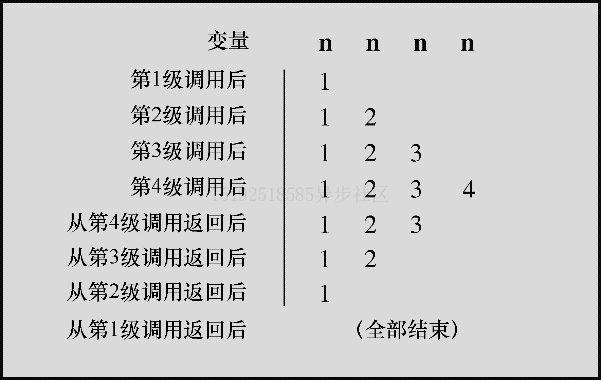
尾递归
尾递归:把递归调用置于函数末尾。是最简单的递归形式,因为它相当于循环
阶乘计算示例(5 的阶乘:1*2*3*4*5;0 的阶乘=1)
#include <stdio.h> long fact(int n) // 直接使用for循环的函数 { long ans; for (ans = 1; n > 1; n--) // 此处顺带初始化ans为1 { ans *= n; } return ans; } long rfact(int n) // 使用递归的函数 { long ans; if (n > 0) { ans = n * rfact(n - 1); } else { ans = 1; } return ans; } int main(void) { int num; do { printf("请输入一个0~12之间的整数:\n"); scanf("%d", &num); } while (num < 0 || num > 12); printf("循环得到的结果:%ld\n", fact(num)); printf("递归得到的结果:%ld\n", rfact(num)); return 0; }递归和倒序计算
递归在处理倒序时非常方便,比循环更便捷
示例程序:打印整数二进制
#include <stdio.h> // 递归函数 void to_binary(unsigned long n) { int r; r = n % 2; if (n >= 2) to_binary(n / 2); putchar(r == 0 ? '0' : '1'); } int main(void) { unsigned long number; printf("输入整数:\n"); scanf("%lu", &number); to_binary(number); return 0; }
递归的优缺点
1、递归既有优点也有缺点
2、优点是递归对于某些编程问题提供了最简单的解决方案
3、缺点是一些递归算法会快速消耗计算机的内存资源,此外不便于阅读和维护
编译多源代码文件的程序
使用多个函数最简单的方法是把它们都放在同一个文件中,然后像编译只有一个函数的文件那样编译该文件即可。其他方法因操作系统而异,下面举例说明
UNIX
1、假定UNIX 系统中安装了UNIX C 编译器 cc,假设file1.c和file2.c是两个内涵 C 函数的文件
2、使用cc file1.c file2.c可以将两个文件编译成一个名为a.out的可执行文件,并生成两个名为file1.o和file2.o的目标文件
3、如果后来改动了file1.c而没有改动file2.c,可以使用cc file1.c file2.o来编译(如果file2.o文件还存在)Linux
1、假定Linux 系统中安装了GNU C 编译器 GCC,假设file1.c和file2.c是两个内涵 C 函数的文件
2、使用gcc file1.c file2.c可以将两个文件编译成一个名为a.out的可执行文件,并生成两个名为file1.o和file2.o的目标文件
3、如果后来改动了file1.c而没有改动file2.c,可以使用gcc file1.c file2.o来编译(如果file2.o文件还存在)DOS 命令行编译器
1、绝大多数DOS 命令行编译器的工作原理和UNIX 的 cc 命令类似,只不过使用不同名称而已
2、一个区别是,对象文件的拓展名是.obj而不是.oWindows 和 Mac 的 IDE 编译器
1、Windows和Mac使用的集成开发环境 IDE的编译器是面向项目的,这种 IDE 的编译器要创建项目来运行单文件程序
2、对于多文件程序,需要使用相应的菜单命令,把源代码加入一个项目中。要确保所有源代码文件都在项目列表中列出使用头文件
1、如果把
main()放在第一个文件中,函数定义放在第二个文件中,那么第一个文件仍然要使用函数原型
2、而把函数原型放在头文件中,就不用每次使用函数文件都写出函数的原型
3、此外,我们常常使用C 预处理器(#define)定义符号常量,也可以将其写入头文件,使用时只需要包含(#include)该头文件即可。这样更有利于维护修改,也利于对常量的管理
4、因此,将函数原型和字符常量放在头文件,是一个十分良好的编程习惯
5、#include "xxx.h"命令可以引入自定义的头文件,使用双引号"",且引号内如果是同目录可以直接写文件名,不同目录也可以使用相对路径和绝对路径如下案例,编写一个模拟酒店收费管理的程序,注意标注的文件名来区分文件,请使用多源代码文件编译方法编译文件(程序运行仍会从
usehotel.c的main()主函数开始)/* hotel.h */ #define QUIT 5 #define HOTEL1 180.00 #define HOTEL2 225.00 #define HOTEL3 225.00 #define HOTEL4 355.00 #define DISCOUNT 0.95 #define STARS "**************************************************" // 显示选择列表 int menu(void); // 返回预定天数 int getnights(void); // 计算费用并显示结果 void showprice(double rate, int nights);/* hotel.c */ #include <stdio.h> #include "hotel.h" int menu(void) { int code, status; printf("\n%s\n", STARS); printf("enter the number to desired hotel:\n"); printf("1) XXX Hotel1 2) XXX Hotel2\n"); printf("3) XXX Hotel3 4) XXX Hotel4\n"); printf("5) Quit\n"); printf("%s\n", STARS); while ((status = scanf("%d", &code)) != 1 || (code < 1 || code > 5)) { if (status != 1) scanf("%*s"); //处理非整数输入 printf("Enter an integer from 1 to 5:\n"); } return code; } int getnights(void) { int nights; printf("How many nights are you needed?\n"); while (scanf("%d", &nights) != 1) { scanf("%*s"); //处理非整数输入 printf("Enter an integer, such as 2\n"); } return nights; } void showprice(double rate, int nights) { int n; double total = 0.0; double factor = 1.0; for (n = 1; n <= nights; n++, factor *= DISCOUNT) total += rate * factor; printf("The total cost will be &%0.2f.\n", total); }/* usehotel.c */ #include <stdio.h> #include "hotel.h" int main(void) { int nights; double hotel_rate; int code; while ((code = menu()) != QUIT) { switch (code) { case 1: hotel_rate = HOTEL1; break; case 2: hotel_rate = HOTEL2; break; case 3: hotel_rate = HOTEL3; break; case 4: hotel_rate = HOTEL4; break; default: printf("Oops!\n"); break; } nights = getnights(); showprice(hotel_rate,nights); } printf("Thank you and goodbye\n"); return 0; }此外,函数也可以直接定义在头文件内,因此上述程序写为单源代码文件的方式可以精简如下:
/* hotel.h */ #include <stdio.h> // 注意引入头文件 #define QUIT 5 #define HOTEL1 180.00 #define HOTEL2 225.00 #define HOTEL3 225.00 #define HOTEL4 355.00 #define DISCOUNT 0.95 #define STARS "**************************************************" // 显示选择列表 int menu(void) { int code, status; printf("\n%s\n", STARS); printf("enter the number to desired hotel:\n"); printf("1) XXX Hotel1 2) XXX Hotel2\n"); printf("3) XXX Hotel3 4) XXX Hotel4\n"); printf("5) Quit\n"); printf("%s\n", STARS); while ((status = scanf("%d", &code)) != 1 || (code < 1 || code > 5)) { if (status != 1) scanf("%*s"); //处理非整数输入 printf("Enter an integer from 1 to 5:\n"); } return code; } // 返回预定天数 int getnights(void) { int nights; printf("How many nights are you needed?\n"); while (scanf("%d", &nights) != 1) { scanf("%*s"); //处理非整数输入 printf("Enter an integer, such as 2\n"); } return nights; } // 计算费用并显示结果 void showprice(double rate, int nights) { int n; double total = 0.0; double factor = 1.0; for (n = 1; n <= nights; n++, factor *= DISCOUNT) total += rate * factor; printf("The total cost will be &%0.2f.\n", total); }/* usehotel.c */ 同上例文件,写法不变 此外由于hotel.h中引入了stdio.h,而本文件又调用了hotel.h,所以可以不再调用stdio.h,即删除本文件的#include <stdio.h>
查找地址:&运算符
指针是 C 语言中最重要的(有时也是最复杂的)概念之一,用于存储变量的地址。前面使用的
scanf()函数中就使用地址作为参数如果主调函数不使用
return返回的值,则必须通过地址才能修改主调函数中的值一元
&运算符的用法一元
&运算符给出变量的储存地址,如果pooh是变量名,那么&pooh是变量的地址。可以把地址看做是变量在内存中的位置PC 地址通常使用十六进制表示,
%p是输出地址的转换说明示例程序:查看不同函数中同名变量分别储存在什么位置
#include <stdio.h> void mikado(int bah) { int pooh = 10; printf("In mikado(), pooh= %d and &pooh= %p\n", pooh, &pooh); printf("In mikado(), bah= %d and &bah= %p\n", bah, &bah); } int main(void) { int pooh = 2, bah = 5; printf("In main(), pooh= %d and &pooh= %p\n", pooh, &pooh); printf("In main(), bah= %d and &bah= %p\n", bah, &bah); mikado(pooh); return 0; }In main(), pooh= 2 and &pooh= 000000000061FE1C In main(), bah= 5 and &bah= 000000000061FE18 In mikado(), pooh= 10 and &pooh= 000000000061FDDC In mikado(), bah= 2 and &bah= 000000000061FDF0输出解析
1、两个pooh地址不同,两个bah的地址也不同,因此证实计算机把它们看做4 个独立的变量
2、函数调用mikado(pooh)把实参 pooh=2传递给了形参 bah。注意这种传递只传递了值,涉及的两个变量并未改变
3、注意第 2 点并非在所有语言都成立。如FORTRAN中,子例程会影响主调例程的原始变量。子例程变量名可能与原始变量不同,但它们的地址相同。但在 C 中不是这样,每个C 函数都有自己的变量,这样可以防止原始变量被被调函数的副作用意外修改,但也带来了一些麻烦
更改主调函数中的变量
有时需要在一个函数中改变其他函数的变量,则需要使用指针
程序示例(错误的方式使用函数交换两个变量的值)
#include <stdio.h> void change(int u, int v) { int temp; temp = u; u = v; v = temp; printf("u:%d v:%d\n",u,v); } int main(void) { int x = 5, y = 10; printf("before: %d %d\n", x, y); change(x, y); printf("after: %d %d\n", x, y); return 0; }问题解析
1、但显然该程序
main()中x和y的值并未交换,而交换函数change()内的u和v的值是交换的。问题出现在把结果传回main()时。
2、change()的变量并不是main()的变量,因此交换的值并不会影响main()中的值。
3、能否使用return将值传回main()?当然可以,但return只能把被调函数中的一个值传回,但现在要传回两个值,因此需要使用指针
指针简介
基本概念
指针:一个值为内存地址的变量(或数据对象)。正如char类型变量值是字符,int类型变量值是整数,指针变量的值是地址
假设一个指针变量名是ptr,则可以编写
ptr = &pooh这条语句1、对于这条语句,我们说ptr 指向 pooh
2、指针 ptr和地址 &pooh的区别是,指针 ptr是变量,地址 &pooh是常量。或者说,指针 ptr是可修改的左值,地址 &pooh是右值
3、我们当然还可以把 ptr 指向别处,如ptr = &bah,现在ptr 指向 bah,值为bah 的地址要创建指针变量,要先声明指针变量的类型。假设想把ptr声明为储存 int 类型变量地址的指针,就要使用下面介绍的新运算符
间接运算符:
*1、假设已知
ptr = &bah;,即ptr 指向 bah
2、使用间接运算符*,可以找出储存在 bah 中的值,语句为:val = *ptr;,意为找出 ptr 指向的值
3、该运算符有时也称为解引用运算符。但注意不要将其与二元乘法运算符混淆,虽然符号相同,但语法功能不同
4、将语句ptr = &bah和val = *ptr放在一起,其功能作用相当于此赋值语句:val = bah;
5、由此可见,使用地址和间接运算符可以间接完成上面赋值语句的功能,这也是其名称的由来声明指针
声明指针变量示例
int * pi; // 指向int类型变量的指针 char * pc; // 指向char类型变量的指针 float * pf, * pg; // 指向float类型变量的指针声明解析
1、类型说明符表明了指针所指向对象的类型,星号表明声明的变量是一个指针
2、*和指针名之间的空格可有可无,通常在声明时使用空格,在解引用时省略空格
3、pc 指向的值(即*pc)是char类型,而pc 本身的类型描述为”指向 char 类型的指针“
4、在大部分系统内部,该地址由一个无符号整数表示。但不要把指针认为是整数类型,为此,ANSI C专门为指针提供了%p的格式转换说明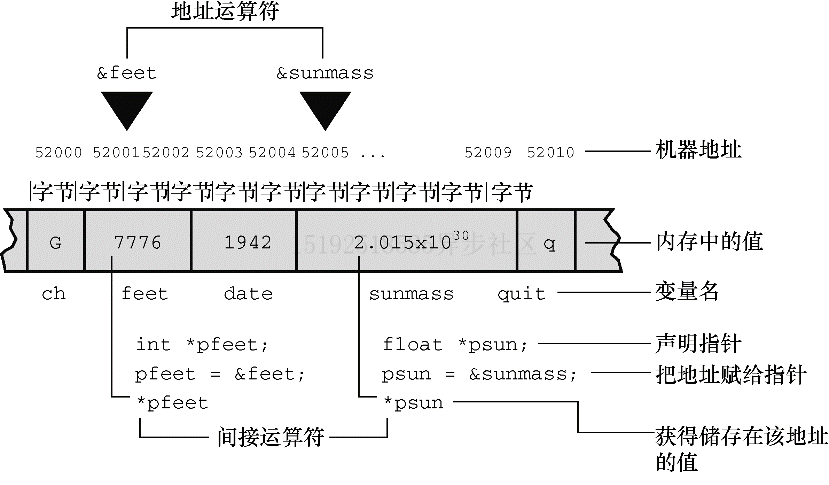
使用指针在函数间通信
在上节改变主调函数中的变量中的程序,通过函数调换两个变量的值不能成功,在此可以通过指针实现
示例程序
#include <stdio.h> void change(int *u, int *v) { int temp; temp = *u; *u = *v; *v = temp; } int main(void) { int x = 5, y = 10; printf("before: %d %d\n", x, y); change(&x, &y); printf("after: %d %d\n", x, y); return 0; }程序解析
1、该函数传递的不是x 和 y的值,而是他们的地址。这意味着出现在
change()原型和定义中的形参 u 和 v将地址作为它们的值。因此应把他们声明为指针。由于x 和 y是整数,所以u 和 v是指向整数的指针
2、在函数体中声明了一个交换值时必需的临时变量 temp,通过temp = *u;把x 的值存储在temp中
3、注意,u 的值是&x,这意味着可以用*u表示x 的值,这正是我们需要的。不要写成temp = u;,该语句意为把x 的地址赋给temp(u 的值就是 x 的地址),而不是 x 的值
4、于是,通过这种形式进行交换,就可以做到修改主调函数的值的需求了
数组与指针
章节概要:数组;数组复习;初始化数组;只读数组;指定初始化器;指定初始化器的特性;数组元素赋值;数组边界;多维数组;二维数组;二维数组的声明;其他多维数组;指针和数组;指针处理数组;函数、数组与指针(声明数组形参);使用指针形参;指针操作;不要解引用未初始化的指针;保护数组中的数据;对形参使用
const;其他const内容;指针和多维数组;通过指针表示二维数组的值;数组指针与指针、多维数组深入;指向多维数组的指针;指针的兼容性;C const和C++ const;函数和多维数组指针;变长数组(VLA);复合字面量
数组
数组复习
声明示例
int main(void) { float candy[365]; // 内含365个float类型元素的数组 char code[12]; // 内含12个char类型元素的数组 int states[50]; // 内含50个int类型元素的数组 ... }数组使用规则
1、前面介绍过,数组由数据类型相同的一系列元素组成。需要使用数组时,通过声明数组告诉编译器数组内含有多少元素和元素类型。编译器根据这些信息正确的创建数组
2、普通变量可以使用的类型,数组元素都可以用
3、方括号[]表示candy、code、states都是数组,方括号中的数字表示数组中的元素个数
4、要访问数组中的元素,通过使用数组下标数(也称为索引)表示数组中的各个元素。数组元素编号从0开始,所以candy[0]表示candy的第 1 个元素,candy[364]表示第 365 个元素,即最后一个元素
初始化数组
数组通常被用来储存程序需要的数据。例如,一个内涵12 个整数元素的数组可以储存 12 个月的天数。这种情况下,在程序一开始就初始化数组比较好
初始化数组的方法
只存储单个值的变量有时也称为标量变量,我们已经很熟悉如何初始化这种变量(代码中PI已被定义为宏):
int fix = 1; float flax = PI * 2;而 C 使用新的语法来初始化数组:
int power[8] = {1, 2, 4, 6, 8, 16, 32, 64}; // ANSI C开始支持这种初始化语法解析
1、如上所示,用以逗号分隔的值列表(用花括号括起来)来初始化数组,各值之间用逗号分隔(逗号和值之间可以使用空格)
2、根据上面的初始化,把1赋给数组首元素 power[0],2赋给power[1],按序以此类推(注意 64 赋给的末元素是 power[7])
3、不支持ANSI C的编译器会把这种初始化识别为错误,在数组声明前加上关键字static即可解决(12 章将讨论此关键字)
使用 const 声明数组
1、有时需要把数组设置为只读,这样只能从数组中检索值,不能把新值写入
2、要创建只读数组,应该用const声明和初始化数组,即const int days[12] = {..., ..., ...}
3、这样修改后,程序在运行过程中就不能修改数组的内容。一旦声明为const,便不能再给它赋值自动适配数组大小
#include <stdio.h> int main(void) { const int days[] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31}; for (int index = 0; index < sizeof(days) / sizeof(days[0]); index++) { printf("Month %2d has %d days.\n", index + 1, days[index]); } return 0; }注意事项
1、 使用数组前必须先初始化。与普通变量类似,在使用数组元素前必须先给它们赋初值,否则编译器使用的值是内存相应位置上的现有值(即都是垃圾值,会干扰程序运行)。只要初始化至少1 个元素的值,其余未初始化的值也会被初始化为 0
2、如果初始化数组时省略方括号中的数字,编译器会根据初始化列表中的项数来确定数组大小(如上”自动适配数组大小”)
3、使用sizeof()计算数组大小(字节)时,sizeof(days)是整个数组的大小,sizeof(days[0])是数组中一个元素的大小
指定初始化器
C99新增加了一个新特性:指定初始化器。利用该特性可以初始化指定的数组元素。例如只初始化最后一个元素
1、传统 C 初始化:
int arr[6] = {0, 0, 0, 0, 0, 212};
2、C99规定,可以在初始化列表中使用带方括号的下标指明待初始化的元素:int arr[6] = { [5] = 212 };复杂示例
#include <stdio.h> int main(void) { int arr[12] = {31, 28, [4] = 31, 30, 31, [1] = 29}; for (int i = 0; i < 12; i++) { printf("index:%-3d value:%d\n", i, arr[i]); } return 0; }index:0 value:31 index:1 value:29 index:2 value:0 index:3 value:0 index:4 value:31 index:5 value:30 index:6 value:31 index:7 value:0 index:8 value:0 index:9 value:0 index:10 value:0 index:11 value:0特性解析
1、以上输出揭示了指定初始化器的两个重要特性
2、如果指定初始化器后面有更多值,如该例[4] = 31, 30, 31,那么后面的值将被用于初始化指定元素后面的元素(即 arr[5]和 arr[6]被初始化为 30 和 31)
3、如果再次初始化指定元素,那么最后的初始化将会取代之前的初始化(如 arr[1]先被初始化为 28,后被指定初始化[1] = 29初始化为 29)
4、如果未指定元素大小,如int arr[] = {1, [6]=4, 9, 10};,编译器将会把数组大小设置为足够装得下初始化的值(即该例下标应为 0~8,共 9 个元素)
数组元素赋值
示例程序
#include <stdio.h> int main(void) { int arr[50]; for (int i = 0; i < 50; i++) { arr[i] = i*2; } arr[6] = 10; return 0; }示例解析
1、声明数组后,可以借助数组下标给数组元素赋值,如已定义
int arr[20];则可使用arr[6] = 10;来赋值对应元素
2、注意多个元素赋值应通过循环遍历依次赋值。C不允许把数组作为一个单元赋给另一个数组,初始化外也不允许使用花括号列表赋值
数组边界
1、在使用数组时,要防止数组下标越界,必须确保下标是有效的值
2、假设有int doofi[20];的声明,则使用时数组下标应在0~19 的范围内
3、编译器不会检查这种错误,但是一些编译器会发出警告,然后继续编译程序
4、在 C 标准中,使用越界下标的结果是未定义的。这意味着程序可能看上去可以运行,但是运行结果很奇怪,或异常终止
5、C 语言为什么会允许这种事发生?这要归功于C 信任程序员的原则。编译器没必要捕获所有的下标错误,这会降低运行速度;C 相信程序员能编写正确的代码,不检查边界,这样程序运行速度更快
多维数组
概念引入与分析
1、假如需要记录5 年内每个月的降水量,应该如何更方便的储存数据?
2、第一种方案,创建60 个变量,分别储存每个月的数据。但显然十分麻烦
3、第二种方案,使用内涵 60 个元素的数组,每个元素恰好表示每月的数据。这种更加可行,但无法分辨年份
4、第三种方案,创建5 个分别内涵 12 个元素的数组,以此分辨年份。但这种方案也很麻烦,且不能满足更多年份的需求
5、第四种方案,使用二维数组,下面介绍此种方案二维数组
- 结合上例,可以将二维数组理解为数组的数组。主数组有5 个元素(表示 5 年),这 5 个元素每个元素都是内涵 12 个元素的数组(表示每年 12 个月)
二维数组的声明
1、使用
float rain[5][12]声明符合本需求的二维数组
2、分开来看,rain[5]表示数组rain 有 5 个元素,至于每个元素的情况,要看声明的其余部分
3、float和[12]说明每个元素的类型是float[12]。即rain 的每个元素本身都是一个内含 12 个 float 类型值的数组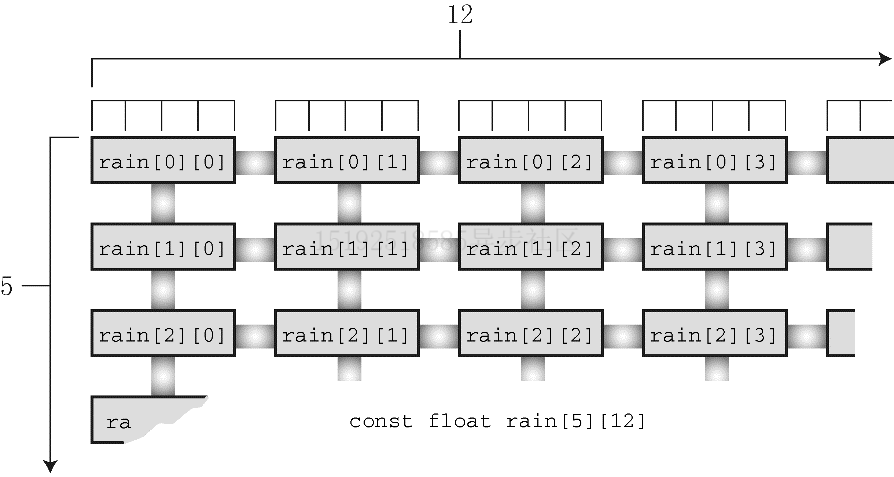
示例程序(十分重要,请理解代码,教程夹杂在代码中)
#include <stdio.h> #define MONTHS 12 #define YEARS 5 #define LINE "=========================================================" int main(void) { // 声明二维数组并初始化(这样初始化换行为了方便查看,也可以按规定格式写在一行) float rain[YEARS][MONTHS] = { {4.3, 4.3, 4.3, 3.0, 2.0, 1.2, 0.2, 0.2, 0.4, 2.4, 3.5, 6.6}, {8.5, 8.2, 1.2, 1.6, 2.4, 0.0, 5.2, 0.9, 0.3, 0.9, 1.4, 7.3}, {9.1, 8.5, 6.7, 4.3, 2.1, 0.8, 0.2, 0.2, 1.1, 2.3, 6.1, 8.4}, {7.2, 9.9, 8.4, 3.3, 1.2, 0.8, 0.4, 0.0, 0.6, 1.7, 4.3, 6.2}, {7.6, 5.6, 3.8, 2.8, 3.8, 0.2, 0.0, 0.0, 0.0, 1.3, 2.6, 5.2}}; int year, month; float subtot, total; /* 输出年总降水与年均降水 */ printf("%s\n", LINE); printf("年份 降水量(英尺)\n"); // year遍历年份,total计算所有年份(5年)总降水量 for (year = 0, total = 0; year < YEARS; year++) { // month遍历月份,subtot计算每年总降水量 for (month = 0, subtot = 0; month < MONTHS; month++) { subtot += rain[year][month]; } printf("%4d %20.1f\n", 2018 + year, subtot); total += subtot; } printf("年均降水:%.1f\n", total / YEARS); printf("%s\n", LINE); /* 输出降水详情 */ printf(" Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec\n"); for (year = 0; year < YEARS; year++) { printf("%d ", 2018 + year); for (month = 0; month < MONTHS; month++) { printf("%.1f ", rain[year][month]); } printf("\n"); } printf("%s", LINE); return 0; }========================================================= 年份 降水量(英尺) 2018 32.4 2019 37.9 2020 49.8 2021 44.0 2022 32.9 年均降水:39.4 ========================================================= Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2018 4.3 4.3 4.3 3.0 2.0 1.2 0.2 0.2 0.4 2.4 3.5 6.6 2019 8.5 8.2 1.2 1.6 2.4 0.0 5.2 0.9 0.3 0.9 1.4 7.3 2020 9.1 8.5 6.7 4.3 2.1 0.8 0.2 0.2 1.1 2.3 6.1 8.4 2021 7.2 9.9 8.4 3.3 1.2 0.8 0.4 0.0 0.6 1.7 4.3 6.2 2022 7.6 5.6 3.8 2.8 3.8 0.2 0.0 0.0 0.0 1.3 2.6 5.2 =========================================================其他多维数组
- 前面讨论的二维数组相关内容都适用于三维数组或更多维的数组。例如可以通过
int box[10][20][30];声明一个三维数组 - 同样面对更多维的数组,需要更多的循环嵌套来遍历,理解好每层循环所控制的元素,才能够准确地操控数组
- 实际使用中,更多维的数组出现概率不高,通常只需要二维数组就能完成大多数需求
- 前面讨论的二维数组相关内容都适用于三维数组或更多维的数组。例如可以通过
指针和数组
第 9 章介绍过指针,指针提供一种以符号形式使用地址的方法。因为计算机的硬件指令非常依赖地址,指针在某种程度上把程序员想要传达的指令以更接近机器的方式表达,因此使用指针的程序很有效率。
指针处理数组
引入
1、指针能有效地处理数组,数组表示法其实是在变相地使用指针
2、举个简单的例子,数组名是数组的首元素地址,即arr == &arr[0]成立
3、两者都是常量,运行过程中不会改变。但是可以将它们赋值给指针变量,然后可以修改指针变量的值示例程序
#include <stdio.h> #define SIZE 4 int main(void) { short dates[SIZE]; short *pti; double bills[SIZE]; double *ptf; pti = dates; // 把数组地址赋给指针,数组名是数组首元素地址 ptf = bills; printf("%23s %15s\n", "short", "double"); for (int index = 0; index < SIZE; index++) printf("pointers + %d: %10p %10p\n", index, pti + index, ptf + index); return 0; }short double pointers + 0: 000000000061FE00 000000000061FDE0 pointers + 1: 000000000061FE02 000000000061FDE8 pointers + 2: 000000000061FE04 000000000061FDF0 pointers + 3: 000000000061FE06 000000000061FDF8程序解析
1、第 2 行起打印两个数组的地址,下一行打印的是指针+1 后的地址。地址为十六进制,因此DF比DE大
2、系统中,地址按字节编址。short占2 字节,double占8 字节。在 C 中,地址+1指的是增加一个存储单元。对数组而言,这意味着地址+1 后是下一个元素的地址,而不是下一个字节的地址
3、这便是为何必须声明指针所指向的对象类型的原因之一。只知道地址不够,还需要知道储存对象需要多少字节,否则指针无法正确取回地址上的值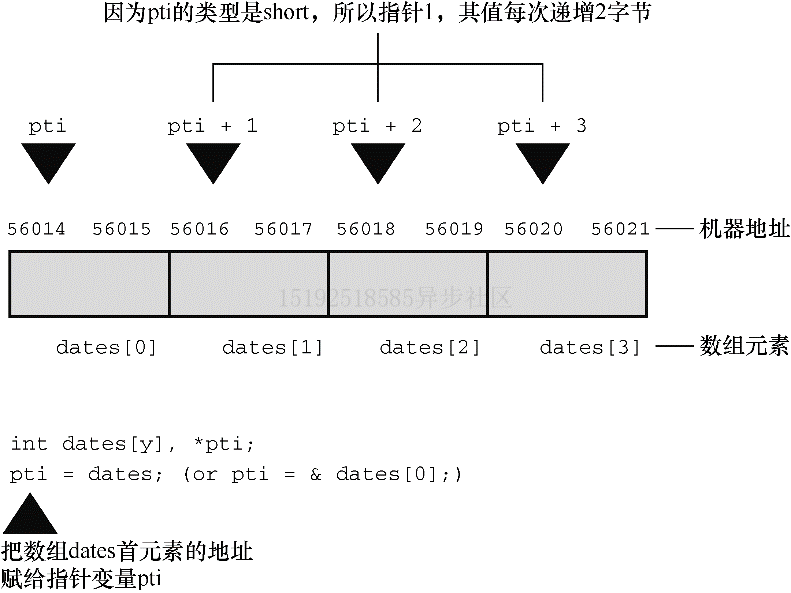
特性总结补充
1、指针的值是它所指向对象的地址。地址的表示方式依赖于计算机内部的硬件,大部分都是按字节编址,即内存中每个字节都按顺序编号。一个较大对象(如 double 的 8 字节)的地址通常是第一个字节的地址
2、在指针前面使用*运算符可以得到该指针所指向对象的值
3、指针+1,指针的值递增它所指向类型的大小(字节为单位)
函数、数组与指针(声明数组形参)
引入
1、假设要编写一个处理数组的函数,该函数返回数组中所有元素之和
2、此时注意,由于数组名是数组首元素地址,所以实参是一个存储对应类型值的地址而不是数值,因此传参时应把它赋给一个指针形式参数,即形参应为指向对应类型的指针
3、此时函数获得了该数组首元素的地址,且知道需要找出的值的数据类型,但并未获得数组元素个数,有两种方法:一种方式可以在函数中需要时直接人为写入数组元素个数(比如for遍历时的条件直接写入元素个数)来告知此信息,但这样不利于维护;另一种方式是创建形参,将元素个数也传入函数中示例程序
#include <stdio.h> #define SIZE 10 // 此处也可写为: // int def(int * ar, int n) int def(int ar[], int n) { int sum = 0; for (int i = 0; i < n; i++) sum += ar[i]; printf("ar的大小是 %zd bytes\n", sizeof(ar)); return sum; } int main(void) { int arr[SIZE] = {20, 10, 5, 39, 4, 16, 19, 26, 31, 20}; long answer; answer = def(arr, SIZE); printf("数值相加为 %d\n", answer); printf("arr的大小是 %zd bytes\n", sizeof(arr)); return 0; }ar的大小是 8 bytes 数值相加为 190 arr的大小是 40 bytes程序解析
1、函数第 1 个形参告诉函数数组地址与数据类型,第 2 个形参告诉函数数组的元素个数
2、只有在函数原型或函数定义头时,才可以用int ar[]代替int * ar(某些编译器可能对于前者会报警报 warning)。在这种情况下,int * ar与int ar[]都表示ar是一个指向 int 的指针,但是int ar[]只能用于声明形参。int ar[]提醒读者,不仅是一个int 类型值,还是一个int 类型数组的元素
3、arr大小是40 字节,因为其内含 10 个 int 类型值。ar只有8 字节,因为其是指向arr数组首元素的指针,我们的系统使用8 字节存储地址(其他系统可能不同),所以指针变量大小是8 字节声明数组形参
因为数组名是该数组首元素的地址,作为实参的数组名要求形参是一个与之相配的指针。只有这种情况下,C 才会把
int ar[]和int * ar解释成一样注意上方示例程序的函数原型与函数定义写在一起,因此对于下方的解释,应按照函数定义标准,而非函数原型标准
由于函数原型可以省略参数名,所以下面 4 种原型等价:
int def(int * ar, int n); int def(int *, int); int def(int ar[], int n); int def(int [], int);函数定义中不能省略参数名,因此只有下面 2 种的定义等价:
int def(int * ar, int n){ // 省略函数内代码 } int def(int ar[], int n){ // 省略函数内代码 }
使用指针形参
函数要处理数组必须知道何时开始、何时结束。上节已展示一种方式标识函数开始与元素个数,而这并非唯一途径。第二种方式是传递两个指针,一个表明数组开始处,一个表明数组结束处
程序示例
#include <stdio.h> #define SIZE 10 int def(int *start, int *end) { int sum = 0; while (start < end) { sum += *start; start++; } return sum; } int main(void) { int arr[SIZE] = {20, 10, 5, 39, 4, 16, 19, 26, 31, 20}; long answer; answer = def(arr, arr + SIZE); printf("数值相加为 %d", answer); return 0; }程序解析
1、指针start开始指向arr数组的首元素地址,所以赋值表达式
sum += *start把首元素的值加给sum(前面讲过*指针变量表示获取对应地址的值)
2、表达式start++递增指针变量start,使其指向数组下一个元素(前面讲过指针递增 1相当于递增对应类型的大小,此处即为递增 int 类型的大小)
3、程序的while循环,使用第二个指针 end来设定范围,告知函数数组的大小
4、while循环的条件使用了小于,即循环处理的最后一个元素是end所指向位置的前一个元素。这是由于end(arr + SIZE)指向的位置实际是数组最后一个元素(arr[9])的后面(并不存在的 arr[10]),本机测试时arr[9]地址尾缀fe14,end尾缀fe18。C 保证在给数组分配空间时,指向数组后面第一个位置的指针仍是有效的指针
5、因此结合第 4 条,如果按照常规逻辑,end应被传入arr + SIZE -1以正确指向最后的元素arr[9]。只是这种写法既不简洁也不好记,于是使用了上面的写法
指针操作
可以对指针进行哪些操作?C 提供一些基本的指针操作,下面的程序演示一些不同的操作
程序示例
#include <stdio.h> int main(void) { int urn[5] = {100, 200, 300, 400, 500}; int *ptr1, *ptr2, *ptr3; ptr1 = urn; // 把一个地址赋给指针 ptr2 = &urn[2]; // 把第一个地址赋给指针 // 1.解引用指针,以及获得指针的地址 printf("1. ptr1 = %p, *ptr1 = %d, &ptr1 = %p\n", ptr1, *ptr1, &ptr1); // 2.指针加法 ptr3 = ptr1 + 4; printf("2. ptr1+4 = %p, *(ptr1+4) = %d\n", ptr1 + 4, *(ptr1 + 4)); // 3.指针递增 ptr1++; printf("3. ptr1 = %p, *ptr1 = %d, &ptr1 = %p\n", ptr1, *ptr1, &ptr1); // 4.指针递减 ptr2--; printf("4. ptr2 = %p, *ptr2 = %d, &ptr2 = %p\n", ptr2, *ptr2, &ptr2); --ptr1; // 恢复初始值 ++ptr2; // 恢复初始值 // 5.指针减另一个指针 printf("5. ptr2 = %p, ptr1 = %p, ptr2-ptr1 = %td\n", ptr2, ptr1, ptr2 - ptr1); // 6.指针减一个整数 printf("6 .ptr3 = %p, ptr3-2 = %p\n", ptr3, ptr3 - 2); return 0; }1. ptr1 = 000000000061FE00, *ptr1 = 100, &ptr1 = 000000000061FDF8 2. ptr1+4 = 000000000061FE10, *(ptr1+4) = 500 3. ptr1 = 000000000061FE04, *ptr1 = 200, &ptr1 = 000000000061FDF8 4. ptr2 = 000000000061FE04, *ptr2 = 200, &ptr2 = 000000000061FDF0 5. ptr2 = 000000000061FE08, ptr1 = 000000000061FE00, ptr2-ptr1 = 2 6. ptr3 = 000000000061FE10, ptr3-2 = 000000000061FE08指针变量的基本操作
赋值
1、可以把地址赋给指针。例如,用数组名、带地址运算符的变量名(&a)、另一个指针等进行赋值
2、该例中,urn 数组的首地址赋给ptr1,其地址编号尾号FE00,变量ptr2获得数组 urn 的第 3 个元素的地址,即urn[2]的地址解引用
1、
*运算符给出指针指向地址上储存的值
2、因此,*ptr的初值是100,该值储存在编号尾号FE00的地址上取址
1、和所有变量一样,指针变量也有自己的地址和值。对指针而言,
&运算符给出指针本身的地址
2、该例中,ptr1储存在内存编号尾号FDF8的地址上,其值为编号尾号FE00的地址(即 urn 的地址)
3、因此,&ptr1是指向ptr1的指针,ptr1是指向urn[0]的指针指针和整数相加
1、可以使用
+运算符把指针和整数相加,或者整数和指针相加
2、无论哪种情况,整数都会和指针所指向类型的大小(字节为单位)相乘,再与初始地址相加
3、因此ptr1 + 4与&urn[4]等价。如果结果超出数组范围,计算结果是未定义的,除非超出数组末尾第一个位置(前面讲过,C 保证该指针有效)指针减去一个整数
1、可以使用
-运算符从一个指针减去一个整数。指针必须是第 1 个运算对象,整数是第 2 个运算对象
2、其运算规则与指针+整数相同递增指针
1、递增指向数组的元素的指针可以让该指针移动到数组下一元素
2、因此,ptr1++相当于把 ptr1 的值+4(因为本系统 int 为 4 字节),ptr1指向urn[1]
3、注意程序中还输出了ptr1 的地址,其并未发生变化。,因为指针变量也是变量,变量不会因为值发生变化就移动位置递减指针
1、当然,除了递增指针,还可以递减指针
2、其使用方法与递增指针相同指针求差
1、可以计算两个指针的差值。通常,求差的两个指针分别指向同一个数组的不同元素,通过计算求出两元素之间的距离。差值的单位与数组类型单位相同
2、该例中,ptr2 - ptr1 = 2意为这两个指针所指向的两个元素相隔2 个 int,而不是 2 字节
3、只要两个指针都指向相同的数组,C 都能保证运算有效。如果指向不同数组,求差运算可能会得出一个值,或者导致运行时错误比较
1、使用关系运算符可以比较两个指针的值,前提是它们指向相同类型的对象
不要解引用未初始化的指针
注意事项:千万不要解引用未初始化的指针,如下:
int *pt; // 未初始化的指针 *pt = 5; // 严重的错误原因说明
1、为何不行?第 2 行的意思是把 5 存储在 pt 指向的位置。但pt 未初始化,其值是一个随机值,所以不知道 5 将存储在何处
2、这可能不会出什么错,也可能会擦写数据或代码,或者导致程序崩溃
3、创建一个指针时,系统只分配了储存指针本身的内存,并未分配存储数据的内存。因此使用指针前,必须先用已分配的地址初始化它
保护数组中的数据
引入
1、编写一个处理基本类型的函数时,需要选择是传递值还是指针。通常都是传递数值,只有程序需要在函数内改变该值时,才会传递指针
2、对于数组别无选择,必须传递指针。因为这样效率更高,如果按值传递,则必须分配足够空间将值拷贝到新数组中
3、C 通常按值传递数据,这样可以保证数据的完整性,使用的是原始数据的副本而非原始数据本身,这样便可以保护原数据。但对于数组,我们需要一种方式来保护数组中的数据对形参使用 const
1、如果函数的意图不是修改数组中的数据内容,那么函数原型和函数定义可以使用只读——
const关键字
2、const告诉编译器,函数不能修改指针指向的数组的内容。如若使用arr[i]++这样的表达式会生成错误信息
3、函数声明例如void def(const int ar[]),这样便可以保护数组的数据其他 const 内容
其他 const 的使用
1、之前我们使用
const创建过变量。虽然使用#define也能创建符号常量,但const更为灵活,可以创建const数组、const指针和指向const的指针。
2、下面举例(默认已声明int arr[5];)
3、如指向const的指针:const int *ptr = arr;,将不允许通过 ptr 修改指向数据的值。但注意arr并未被声明为const,所以仍可通过 arr 修改元素的值:arr[0] = 10;。此外也可以让 ptr 指向别处:ptr++; // 指向arr[1]
4、此外可以声明并初始化一个不能指向别处的const指针,特别注意const的位置:int * const ptr = arr;。可以用这种指针修改指向的值,但不能更改它指向的地址
5、如果创建指针时使用两次const,这样便既不能修改指向地址的数据也不能修改指向的地址:const int * const ptr = arr;其他 const 的规则
1、把
const或非const数据的地址初始化为指向const的指针是合法的,但const数据的地址只能赋给指向const的指针,赋值给普通指针是非法的
2、这个规则非常合理,否则通过普通指针就能修改const数组的数据
3、因此,对函数的形参使用const不仅能保护数据,还能让函数处理const数组int arr[5] = {}; const int locked[5] = {}; const int *ptr1; int *ptr2; ptr1 = arr; // 有效(指向非const数据的地址) ptr1 = locked; // 有效(只是不能通过ptr1改变指向的值,但可以更改ptr1指向的对象。指向const数据的地址) ptr1 = &arr[3]; // 有效(指向非const数据的地址) ptr2 = arr; // 有效(普通指针指向普通地址) ptr2 = locked; // 无效(普通指针不能指向const数据的地址,只能通过指向const的指针指向此数据)
指针和多维数组
引入
- 假设有
int arr[4][2];的声明。数组名 arr是该数组的首元素地址。在本例中,arr的首元素是一个内含两个 int 值的数组(由 arr 声明时第二维为[2]表明),所以arr是这个数组(即内含两个 int 值的数组)的地址
- 假设有
从指针属性进一步分析(可结合下方辅助理解示例来理解)
1、因为arr是首元素地址(即第一维首元素
arr[0]的地址),所以在地址上arr = &arr[0],其值相同。而arr[0]本身是一个内含两个整数的数组,所以arr[0]的值和它的首元素(一个整数)地址(即&arr[0][0])相同,即在地址上arr[0] = &arr[0][0](此处可以像第一维一样,假设将二维数组的arr[0]看做一维的arr,将二维数组的arr[0]的元素arr[0][0]和arr[0][1]分别看做一维的arr[0]和arr[1],方便理解)
2、简而言之,arr是一个占用两个 int 大小对象的地址(因为其一个元素(arr[0])内含两个 int 值),而arr[0]是一个占用一个 int 大小对象的地址。但由于内含两个整数的数组(arr[0])和这个整数(arr[0][0])起始于同一个地址,所以arr和arr[0]地址相同。综上,在地址上arr = arr[0] = &arr[0] = &arr[0][0],因为都指向整个二维数组的起始地址(即最根本的第一个数值的位置arr[0][0])
3、给指针或地址+1,其值会增加对应类型大小的数值。在这方面,arr和arr[0]不同,因为如上所言arr指向的对象占两个 int 大小,而arr[0]指向对象占一个 int 大小。因此arr + 1和arr[0] + 1的值不同
4、解引用(使用*符)指针或通过数组下标[],可以得到引用对象的值。因为arr[0]作为数组名是数组首元素(即arr[0][0])的地址,所以解引用*(arr[0])得到的是存储在arr[0][0]上的值。与此类似,arr作为数组名代表首元素(即arr[0])的地址,但arr[0]本身还是一个地址,其地址是&arr[0][0],所以解引用*arr就是&arr[0][0](注意这里解引用后*arr的值就是地址,而不是数值),此时再次解引用**arr就相当于*&arr[0][0],即取得arr[0][0]指向的值
5、简而言之,arr作为数组名(首元素地址),是地址的地址,必须解引用两次才能获得原始值。此处地址的地址或者指针的指针就是双重间接的例子针对上述 1、2 条的辅助理解示例
#include <stdio.h> int main(void) { int arr[4][2]; printf("%p\n", arr); // 数组名为首元素地址,起始首元素为arr[0],即指向&arr[0] printf("%p\n", &arr[0]); // 与上者相等 printf("%p\n", arr[0]); // 数组名为首元素地址,起始首元素为arr[0][0],即指向&arr[0][0] printf("%p\n", &arr[0][0]); // 与上者相等 printf("%p\n", &arr[0][1]); // 从第二维递增一个下标,证明arr[0]是一个占用一个 int 大小对象的地址 printf("%p\n", &arr[1]); // 从第一维递增一个下标,证明arr是一个占用两个 int 大小对象的地址 return 0; }000000000061FE00 000000000061FE00 000000000061FE00 000000000061FE00 000000000061FE04 000000000061FE08针对上述 3、4、5 条的辅助理解示例
#include <stdio.h> int main(void) { int arr[4][2] = {{2, 4}, {6, 8}, {1, 3}, {5, 7}}; printf("%p\n", arr); printf("%p\n", arr + 1); // 增加对应元素类型的大小(两个int类型大小) printf("%p\n", arr[0]); printf("%p\n", arr[0] + 1); // 增加对应元素类型的大小(一个int类型大小) printf("=================\n"); printf("%d\n", arr[0][0]); // 直接通过数组下标获取值 printf("%d\n", *arr[0]); // 解引用arr[0] printf("%p\n", *arr); // 解引用一次arr,其值仍为地址,即arr[0][0]的地址 printf("%d\n", **arr); // 解引用两次,获得指向的值 return 0; }000000000061FE00 000000000061FE08 000000000061FE00 000000000061FE04 ================= 2 2 000000000061FE00 2通过指针表示二维数组的值
前面我们了解过,对于
int arr[4][2]该例:arr + 1,其值+8(两个 int),而arr[0] + 1,其值+4(一个 int)但要注意,与
arr[2][1]数值等价的指针表示法是*(*(arr+2) + 1),理解如下表达式 相对上一步的含义 arr 二维数组首元素地址,(每个元素都是内含两个 int 的一维数组),即第一维首元素 arr[0]的地址arr +2 二维数组第 3 个元素的地址,即第一维从第一个元素 arr[0]变为第三个元素arr[2],值为其地址*(arr+2) 二维数组第 3 个元素的首元素地址,即第二维首元素 arr[2][0]的地址*(arr+2) + 1 二维数组第 3 个元素的第 2 个元素的地址,即第二维从第一个元素 arr[2][0]变为第二个元素arr[2][1],值为其地址*(*(arr+2) + 1) 解引用该地址,取得 arr[2][1]的值图片演示指针表示法
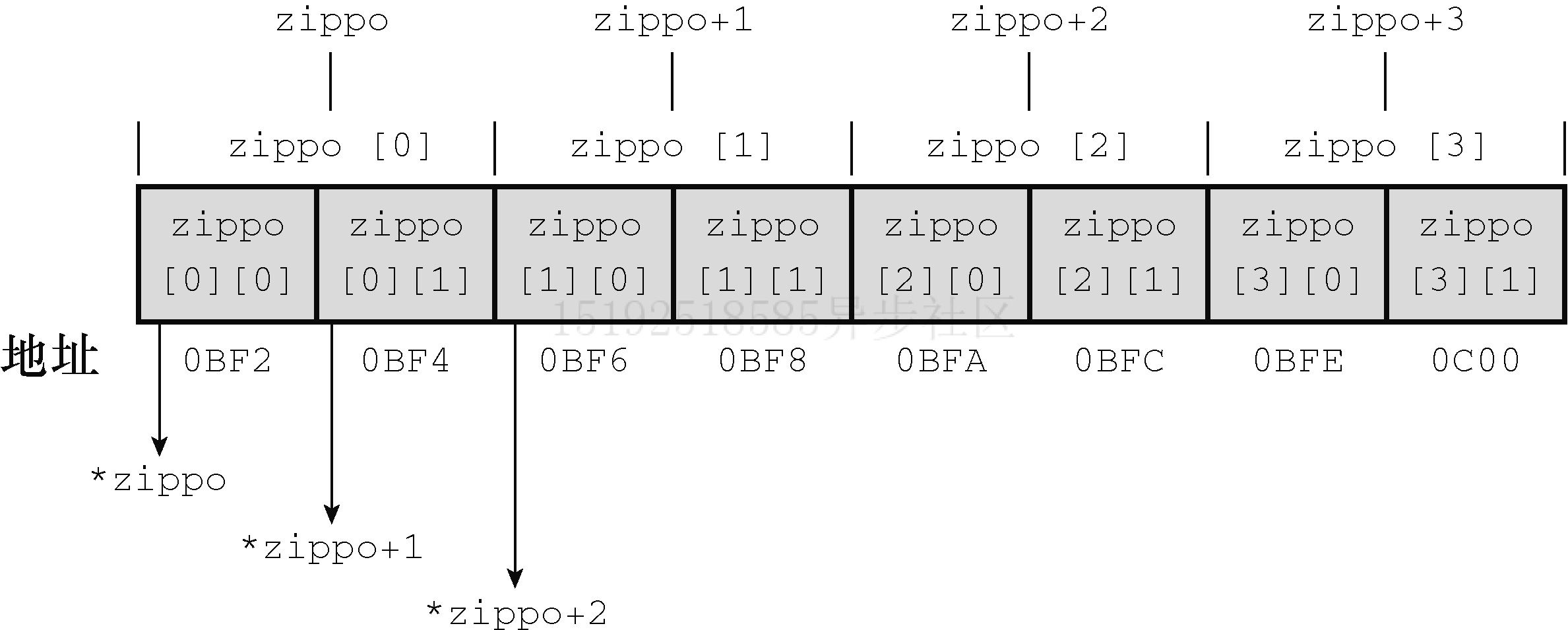
以上分析并不是为了说明用指针表示法来代替常用的数组表示法(即下标直接引用),而是表述程序恰巧使用一个指向二维数组的指针,而且要通过该指针获取值,最好用简单的数组表示法
数组指针与指针、多维数组深入
指向多维数组的指针
如何声明一个指针变量 pz指向一个二维数组(如
int arr[4][2]的第一层的arr或arr[1])?声明方法
1、对于声明指向arr和
arr[1]这样的数组,只声明为指向 int 类型还不够,因为这种指针指向一个 int 类型的值,但需要指向的元素为内含两个 int 类型的值的数组
2、因此应按照int (*pz)[2]这种格式声明,这种声明的pz便指向一个内含两个 int 类型的值的数组,将其声明为指向数组的指针。为什么使用圆括号(),因为[]的优先级高于*,考虑下条声明
3、对于int *pax[2]这条声明。按照优先级pax先与[2]结合成为一个内含两个元素的数组,然后*表示pax 数组内含两个指针。因此这条代码声明了两个指向 int 的指针
4、补充解释,int (*pz)[2]的pz是一个储存一个地址的指针,其储存的地址指向内含两个 int 类型的值的数组;而int *pax[2]的pax是一个储存两个地址的指针数组,其储存的地址指向一个 int 类型的值辅助理解示例
#include <stdio.h> int main(void) { int arr[4][2] = {{2, 4}, {6, 8}, {1, 3}, {5, 7}}; int(*pz)[2]; pz = arr; // 指向&arr[0],其为内含两个int类型值的数组 printf("%p\n", &arr[0]); printf("%p\n", pz); printf("%p\n", pz + 1); // +1直接增加了两个int类型值的大小 printf("%p\n", &arr[1]); // 证明了pz+1 相当于从arr[0]指向了arr[1] printf("%p\n", pz[0]); // 因为pz指向arr[0],所以相当于&arr[0][0] (具体还需结合下方“数组指针的[]使用来理解”) printf("%p\n", pz[0] + 1); // 相当于从arr[0][0] +1后指向arr[0][1],所以增加了一个int类型值的大小 printf("%p\n", &arr[0][1]); // 证明了pz[0]+1 指向 arr[0][1] printf("%p\n", *pz); // 使用 * 解运算pz,相当于解运算arr[0],即 *arr[0],arr[0]指向其首元素地址,于是便得到 &arr[0][0] printf("%p\n", *pz + 1); // 相当于arr[0][0] +1后指向arr[0][1],增加一个int类型值大小 printf("=================\n"); printf("%d\n", *pz[0]); // pz[0]即指向 &arr[0][0],解运算得到arr[0][0]的值 printf("%d\n", **pz); // 第一次解运算 *pz得到指向arr[0][0]的地址 &arr[0][0],解运算得到值 printf("%d\n", pz[2][1]); // 关于数组指针加[]的事宜,下方将详细讨论 printf("%d\n", *(*(pz + 2) + 1)); // 按前节方法解释,相当于得到arr[3][1]的值 return 0; }000000000061FDF0 000000000061FDF0 000000000061FDF8 000000000061FDF8 000000000061FDF0 000000000061FDF4 000000000061FDF4 000000000061FDF0 000000000061FDF4 ================= 2 2 3 3数组指针的[]使用
1、如前所述,虽然pz 是一个指针,不是数组名,但仍可以使用
pz[2][1]这种写法
2、可以用数组表示法或指针表示法表示一个数组元素,既可以使用数组名,也可以使用指针名
3、三者的等价关系如下陈述。需要注意数组名[m][n]调用到的数值与arr[m][n]的值是对应的,pz 调用时,如果 pz不指向数组首元素地址,则对应的值是arr[指向元素 + m][指向元素 + n]arr[m][n] == *(*(arr+m) + n) pz[m][n] == *(*(pz+m) + n)
指针的兼容性
指针之间的赋值比数值类型之间的赋值要严格。例如,不用类型转换就可以把int 类型值赋给double 类型变量,但两个类型的指针就不能这样做,如下两例:
int n=5; double x; int *pl = &n; double *pd = &x; /*-------------------------------*/ x = n; // 数值类型,隐式类型转换 pd = pl; // 指针,编译时错误int *pt; int (*pa)[3]; int arr1[2][3]; int arr2[3][2]; int **p2; // 一个指向指针的指针 /*--------------------------------*/ pt = &arr1[0][0]; // 都是指向int的指针 pt = arr1[0]; // 数组名是首元素地址,都是指向int的指针 pt = arr1; // 无效,首元素地址指向&arr[0],是一个指向三个int类型值的数组 pa = arr1; // 相当于&arr[0],都是指向内含三个int类型元素数组的指针 pa = arr2; // 无效,arr2为指向两个int类型值的数组 pa = &pt; // 都是指向int *的指针,&pt为指向指针pt的地址 *p2 = arr2[0]; // 都是指向int的指针,p2此处进行了一次解运算,指向int类型而非指向指针 p2 = arr2; // 无效,p2为指向指针的指针多重解引用注意事项:
示例程序
int x=20; const int y=23; int *p1 = &x; const int *p2 = &y; const int **pp2; p1 = p2; // 不安全,把const指针赋给非const指针 p2 = p1; // 有效,把非const指针赋给const指针 pp2 = &p1; // 不安全,嵌套指针类型赋值示例解析
1、前面提到过,把
const指针赋给非const指针是不安全的,因为这样可以使用新的指针改变const指针指向的数据。编译器在编译时,可能会给出警告,执行这样的代码是未定义的
2、但把非const指针赋给const指针没问题,前提是只进行一级解引用。但当进行两级解引用时,这样的赋值也不安全,如下描述非 const 赋值 const 时的两级解引用
const int **pp2; int *p1; const int n=13; pp2 = &p1; // 允许,但是这会导致const限定符失效(根据第一行代码,不能通过**pp2修改它所指向的内容) *pp2 = &n; // 有效,两者都声明为const,但是这将导致p1指向n(*pp2已被修改) *p1 = 10; // 有效,但是这将改变n的值(但是根据第三行代码,不能修改n的值)示例解析
1、发生了什么?如前所示,标准规定了通过非
const指针更改const数据是未定义的
2、例如使用gcc编译包含以上代码的程序,导致n最终值为13(未更改)。但是在相同系统下使用clang来编译,n最终的值是10(已更改)。两个编译器都给出指针类型不兼容的警告
3、当然您可以忽略这些警告,但最好不要相信程序运行的结果,因为这些结果都是未定义的
C const 和 C++ const
1、C 和 C++中
const用法很相似,但并不完全相同
2、区别之一是,C++允许声明数组大小时使用const整数,而 C不允许
3、区别之二是,C++的指针赋值检查更严格。C++不允许把const指针赋给非const指针,而 C 允许。如下例,但如果通过 p1 更改 y,其行为是未定义的const int y; const int *p2 = &y; int *p1; p1 = p2; // C++不允许这样做,C可能只发出警告函数和多维数组指针
示例程序
#include <stdio.h> #define ROWS 3 #define COLS 4 void sum_rows(int ar[][COLS], int rows) { int r, c, tot; for (r = 0; r < rows; r++) { tot = 0; for (c = 0; c < COLS; c++) tot += ar[r][c]; printf("row %d: sum = %d\n", r, tot); } } void sum_cols(int ar[][COLS], int rows) { int r, c, tot; for (c = 0; c < COLS; c++) { tot = 0; for (r = 0; r < rows; r++) tot += ar[r][c]; printf("col %d: sum = %d\n", c, tot); } } int sum2d(int ar[][COLS], int rows) { int r, c, tot = 0; for (r = 0; r < rows; r++) for (c = 0; c < COLS; c++) tot += ar[r][c]; return tot; } int main(void) { int junk[ROWS][COLS] = {{2, 4, 6, 8}, {3, 5, 7, 9}, {12, 10, 8, 6}}; sum_rows(junk, ROWS); sum_cols(junk, ROWS); printf("Sum of all elements = %d\n", sum2d(junk, ROWS)); return 0; }row 0: sum = 20 row 1: sum = 24 row 2: sum = 36 col 0: sum = 17 col 1: sum = 19 col 2: sum = 21 col 3: sum = 23 Sum of all elements = 80程序解析
1、在函数声明中
int ar[][COLS],第 1 个方括号[]是空的,空的方括号表明 ar 是一个指针。所以该语句等效于int (*ar)[COLS],如前面数组指针提到的,后面的COLS用于告知指针指向的元素(子数组)内含多少个对应数据类型的大小
2、该程序把数组名 junk(即首元素地址,即子数组)和符号常量 ROWS作为参数传递给函数。由于int ar[][COLS]的声明,每个函数都把ar视为内含数组元素的数组
3、注意,ar和main中的junk都使用数组表示法。因为 ar 和 junk类型相同,都是指向内含 4 个 int 值的数组的指针
4、一般而言,声明一个指向 N 维数组的指针时,只能省略最左边的方括号中的值,因为其只用于表明这是一个指针,其他方括号则用于描述指针指向的数据对象的类型(内含多少个对应什么数据类型的大小)
变长数组(VLA)
引入
/*如上节的函数示例*/ int sum2d(int ar[][COLS], int rows) { int r, c, tot = 0; for (r = 0; r < rows; r++) for (c = 0; c < COLS; c++) tot += ar[r][c]; return tot; }1、为什么使用函数操作二维数组时,只将行数(ROWS)作为函数的形参,而列数(COLS)内置在函数体内?
2、我们可以使用sum2d()函数对int arr1[5][4]、int arr2[100][4]、int arr3[2][4]等数组求各元素之和,是因为这些数组的列数固定为 4,行数被传递给形参 rows,rows是一个变量。但如果要对int arr4[6][5]计算,则不能使用这个函数,必须新建一个COLS 为 5的函数,因为C 规定,数组的维数必须是常量,不能用变量代替
3、要创建一个能处理任意大小二维数组的函数,比较繁琐(必须把数组作为一位数组传递,然后让函数计算每行的开始处)。鉴于此,C99新增了变长数组,允许使用变量表示数组的维度变长数组
声明示例
int quarters = 4; int regions = 5; double arr[regions][quarters]; // 一个变长数组变长数组的特性
1、变长数组有一些限制:变长数组必须是自动储存类别,这意味着无论在函数中声明还是作为函数形参声明都不能使用
static或extern储存类别说明符(第 12 章介绍)。而且不能在声明中初始化它们
2、变长数组不能改变大小:变长数组的“变”不是指可以修改已创建数组的大小。一旦创建了变长数组,其大小保持不变。这里的“变”指的是在创建数组时,可以使用变量指定数组的维度
3、由于变长数组是 C 语言的新特性,目前完全支持这一特性的编译器不多示例程序(程序要求编译器支持变长数组)
#include <stdio.h> #define ROWS 3 #define COLS 4 // 带变长数组形参的函数 int sum2d(int rows, int cols, int ar[rows][cols]) { int r, c, tot = 0; for (r = 0; r < rows; r++) for (c = 0; c < cols; c++) tot += ar[r][c]; return tot; } int main(void) { int i, j; int rs = 3, cs = 10; int junk[ROWS][COLS] = {{2, 4, 6, 8}, {3, 5, 7, 9}, {12, 10, 8, 6}}; // 3*4数组 int morejunk[ROWS - 1][COLS + 2] = {{20, 30, 40, 50, 60, 70}, {5, 6, 7, 8, 9, 10}}; // 2*6数组 int varr[rs][cs]; // 3*10变长数组 // 为变长数组赋值 for (i = 0; i < rs; i++) for (j = 0; j < cs; j++) varr[i][j] = i * j + i; printf("3*4 array: sum = %d\n", sum2d(ROWS, COLS, junk)); printf("2*6 array: sum = %d\n", sum2d(ROWS - 1, COLS + 2, morejunk)); printf("3*10 VLA: sum = %d\n", sum2d(rs, cs, varr)); return 0; }3*4 array: sum = 80 2*6 array: sum = 315 3*10 VLA: sum = 165示例解析
1、声明一个带二维变长数组参数的函数,需要注意前两个形参
rows和cols用作第三个形参二维数组ar[rows][cols]的两个维度。参数数组 ar的声明需要使用前两个参数,因此必须先声明前两个参数,使用int sum2d(int ar[rows][cols], int rows, int cols)这种无效的顺序声明函数原型是错误的
2、前面提到过 C 标准规定,可以省略函数原型中的形参名,但这种情况下必须用星号*代替省略的维度:int sum2d(int, int, int ar[*][*])。(注意是函数原型不是函数定义,如果是函数定义仍必须完整写出类型、变量名等信息)
3、需要注意的是,在函数定义时的形参列表中声明的变长数组,并非实际创建数组。和传统的语法类似,变长数组名实际上是一个指针。这说明函数实际上还是在原始数组中处理数组,因此可以更改传入的数据
4、变长数组还允许动态内存分配,这说明可以在程序运行时指定数组的大小。普通数组都是静态内存分配,即在编译时确定数组大小(12 章将详细讨论)
复合字面量
引入
1、假设给带int 类型形参的函数传递一个值,应传递int 类型的变量,但也可以传递int 类型的常量,比如5
2、C99 之前,对于带数组形参的函数,可以传递数组,但没有等价的数组常量,于是 C99 新增了复合字面量
3、字面量是除符号常量以外的常量。如:5是int的字面量;81.3是double的字面量;Y是char的字面量;hello是字符串字面量
4、于是,C99 认为如果有代表数组和结构内容的复合字面量,会更方便复合字面量
1、对于数组,复合字面量类似数组初始化列表(实际可以看做常量数组,类似我们给普通变量赋值时写的5、81.3这样的字面量常量),前面是用括号
()括起来的类型名。如(int [2]){10,20};,括号内的int [2]便是复合字面量的类型名
2、初始化有数组名的数组时可以省略数组大小,复合字面量也可以省略大小,编译器会自动计算数组当前元素个数:(int []){50,20,90}
3、因为复合字面量是匿名的,所以不能先创建再使用,必须在创建的同时使用它。使用指针记录地址就是一种用法,即如果有int *pt;,则可以通过pt = (int [2]){10,20};让pt指针记录地址,后通过pt使用这个常量数组(匿名只是无法通过名称调用,但仍储存在固定的内存地址上,因此可以使用指针调用)。复合字面量的类型名也代表首元素地址,因此和数组规则相同,*pt是10,pt[1]是20
4、还可以把复合字面量作为实参传给带有匹配形参的函数。这也是复合字面量的典型用法,其好处是把信息传入函数前不必先创建数组
5、注意,复合字面量是提供只临时需要的值的一种手段。复合字面量具有块作用域(12 章详细介绍),一旦离开定义复合字面量的块,程序无法保证该字面量是否存在。也就是说,复合字面量定义在最内层的花括号内综合应用示例
#include <stdio.h> #define COLS 4 // 计算一维数组各元素的和 int sum(const int ar[], int n) { int i, total = 0; for (i = 0; i < n; i++) total += ar[i]; return total; } // 计算二维数组各元素的和 int sum2d(const int ar[][COLS], int rows) { int r, c, tot = 0; for (r = 0; r < rows; r++) for (c = 0; c < COLS; c++) tot += ar[r][c]; return tot; } int main(void) { int total1, total2, total3; int *pt1; int(*pt2)[COLS]; // 使用指针记录匿名的复合字面量的地址,以后续调用 pt1 = (int[2]){10, 20}; pt2 = (int[2][COLS]){{1, 2, 3, -9}, {4, 5, 6, -8}}; total1 = sum(pt1, 2); total2 = sum2d(pt2, 2); // 将复合字面量作为实参传入函数形参 total3 = sum((int[]){4, 4, 4, 5, 5, 5}, 6); printf("total1 = %d\n", total1); printf("total2 = %d\n", total2); printf("total3 = %d\n", total3); return 0; }
字符串和字符串函数
章节概要:表示字符串和字符串 I/O;在程序中定义字符串;数组表示法与指针表示法;字符串数组;字符串输入;分配空间;
gets()函数;fgets()函数;gets_s()函数;scanf()函数;字符串输出;puts()函数;fputs()函数;printf()函数;自定义输入/输出函数;字符串函数;strlen()函数;strcat()函数;strncat()函数;strcmp()函数;strncmp()函数;strcpy()函数;strncpy()函数;其他字符串函数;ctype.h字符函数和字符串;字符串示例:字符串排序;排序指针而非字符串;选择排序算法;命令行参数;字符串转换为数字;atoi()与其类别函数;strtol()与其类别函数
表示字符串和字符串 I/O
第四章介绍过,字符串是以空字符(
\0)结尾的char 类型数组。因此,可以把上一章学到的数组和指针的知识应用于字符串在程序中定义字符串
字符串字面量(字符串常量)
1、用双引号
""括起来的内容称为字符串字面量,也叫做字符串常量。双引号中的字符和编译器自动加入末尾的\0字符,都作为字符串储存在内存中
2、从ANSI C起如果字符串字面量之间没有间隔,或者用空白字符分隔,C 会将其视为串联起来的字符串字面量。如char word[50] = "hello,"" how are" " you?"等价于char word[50] = "hello, how are you?"。如果要在字符串内部使用双引号,则必须通过反斜杠\进行转义。如printf("\"Hello\", Jimmy said");
3、字符串常量属于静态存储类别,这说明如果在函数中使用字符串,该字符串只会被储存一次,并在整个程序的生命周期内存在,即使函数被调用多次
4、用双引号括起来的内容被视为指向该字符串存储位置的指针(该字符串首字符地址),这类似于把数组名作为指向该数组位置的指针
5、因此,如果使用printf()打印"hello",使用%s将打印整个字符串,使用%p将打印该字符串首字符地址。既然整个字符串表示首字符地址,那么使用%c输出解引用的*"hello",结果便是首字符 h而不是整个字符串字符串数组和初始化
1、定义字符串数组时,必须让编译器知道需要多少空间
2、声明示例:const char word[10] = "hello",其中const表明不会更改这个字符串(可省略)。这种形式初始化比标准的数组初始化简单的多:const char word[10] = {'h', 'e', 'l', 'l', 'o', '\0'},注意最后的空字符,如果没有这个空字符,这就不是一个字符串,而是一个字符数组
3、在指定数组大小时,要确保数组的元素个数要至少比字符串长度多 1(为了容纳空字符)。所有未被使用的元素都会被自动初始化为 0(这里的 0 是 char 形式的空字符,不是数字字符 0)
4、通常,让编译器确定数组大小很方便。对于字符串(字符数组)也一样,省略数组初始化声明中的大小,编译器会自动计算数组的大小
5、字符数组名和其他数组名一样,是该数组首元素的地址数组表示法与指针表示法
前面介绍的声明为数组表示法,如
const char arr[] = "hello";(const可省略),此外还可以用指针表示法创建字符串,如const char * pt = "hello";(const不可省略)pt和arr都是该字符串的地址,且字符串本身决定预留的存储空间,尽管如此,这两种形式并不完全相同
数组表示法
1、数组形式(
arr[])在计算机的内存中分配为一个内含 6 个元素的数组(预留出空字符),每个元素被初始化为字符串字面量对应的字符
2、通常字符串都作为可执行文件的一部分存储在数据段中,当把程序载入内存时,也载入了字符串。字符串存储在静态存储区中,但是程序在开始运行时才会为数组分配内存,此时才将字符串拷贝到数组中。这时字符串有两个副本,一个是静态内存中的字符串字面量,另一个是arr 数组中的字符串
3、随后,编译器将数组名 arr识别为数组的首元素地址的别名。在数组形式中,arr是地址常量,不能更改 arr,否则更改意味着改变了数组的存储位置。所以可以进行类似arr+1这样的操作,标识数组的下一个元素,但不能进行类似++arr这样的操作,递增运算符只可以用于可修改的左值,不能用于常量指针表示法
1、指针形式(
*pt)也使得编译器为字符串在静态存储区预留 6 个元素的空间。另外一旦开始执行程序,他会为指针变量 pt留出一个储存位置,并把字符串的地址存储在指针变量中
2、该指针变量最初指向该字符串首字母,但是它的值可以改变。因此可以使用递增运算符,如++pt;将指向第二个字符(即 e)
3、字符串字面量被视为const数据,由于pt 指向这个数据,所以应该把pt声明为指向const数据的指针。这意味着不能用 pt 改变它所指向的数据,但可以改变 pt 的值(即指向的地址)
4、如果把一个字符串拷贝给一个数组(即使用数组表示法),则可以随意改变数据,除非把数组声明为const
字符串数组
创建一个字符串数组通常很方便,可以通过数组下标访问多个不同的字符串
字符串数组-数组表示法
const words[5][40] = { "Hello, my name is Lisa.", "I'm 16 years old.", "How about you?" };字符串数组-指针表示法
const *words[5] = { "Hello, my name is Lisa.", "I'm 16 years old.", "How about you?" };
字符串输入
想把一个字符串读入程序,首先必须预留储存该字符串的空间,然后用输入函数获取该字符串
分配空间
第一件事便是分配空间,以储存后续读入的字符串。这意味着要为字符串分配足够的空间,不要指望计算机在读取时顺便计算它的长度,再分配空间(计算机不会这样做)
错误示例
char *name; scanf("%s",name);1、虽然可能通过编译(大概率会报警报),但在读取name时,name很可能会擦写程序中的数据或代码,导致程序异常终止
2、因为scanf()要把信息拷贝到参数的指定地址,而name是个未初始化的指针,所以可能指向任何地方正确分配空间
1、最简单的方法是,在声明时显式指明数组的大小:
char name[81];
2、还有一种方法是使用C 库函数来分配内存,第 12 章介绍
gets()函数
gets()的使用char word[81]; gets(word); puts(word);1、在读取字符时,
scanf()配合%s只能读取一个单词(遇到空格就停止),但程序经常要读取一整行输入
2、gets()函数就用于读取整行输入,直至遇到换行符。然后丢弃换行符,储存其他字符,并在这些字符末尾添加一个空字符使其成为一个字符串
3、gets()常常与puts()函数配对使用,该函数用于显示字符串,并在末尾添加换行符gets()的危险性1、某些编译器对于使用
gets()的程序报出警告,但并非全部编译器都会这样做。其他编译器可能在编译过程中给出警告,但不会引起你的注意
2、问题出现在gets()的唯一参数是字符串名(word),它无法检查数组是否装得下输入行
3、如果输入的字符串过长,会导致缓冲区溢出,即多余的字符超出了指定的目标空间。如果这些多余字符只是占用了尚未使用的内存,就不会立刻出现问题;如果它们擦写掉了程序中的其他数据,会导致程序异常终止,或者还有其他情况
4、如果出现上述情况,会报出Segmentation fault(分段错误),这条消息说明该程序试图访问未分配的内存。该函数的不安全行为造成了安全隐患,过去有些人通过系统编程,利用gets()插入和运行一些破坏系统安全的代码gets()被遗弃1、由于
gets()的不安全性,不久C 社区许多人都建议编程时摒弃gets()。制定C99标准的委员会将这些建议放入了标准,承认gets()的大量问题并建议不要再使用它
2、尽管如此,在标准中保留gets()也合情合理,因为现有程序中含有大量使用该函数的代码。而且只要使用得当,其的确是一个很方便的函数
3、好景不长,C11采取了更强硬的手段,直接从标准中废除了gets()函数。既然标准已经发布,那么编译器就必须调整支持。然而实际使用中,编译器为了兼容以前的代码,大部分仍继续支持gets()函数,但部分编译器已按标准废除gets()
fgets()函数
fgets()函数可以作为gets()的替代品,其通过第二个参数限制读入的字符数来解决溢出问题。但该函数设计用于处理文件输入,一般情况可能不那么好用fgets()和gets()的区别1、
fgets()函数的第二个参数指定了读入字符的最大数量。如果该参数值为n,那么fgets()将读取n-1个字符,或者读到遇到的第一个换行符
2、如果fgets()读到一个换行符,会把它保存在字符串中。而gets()函数会舍弃换行符
3、fgets()的第三个参数指明要读入的文件。如果读入从键盘输入的数据,则以stdin(标准输入)作为参数,该标识符定义在stdio.h中fgets()的使用char word[14]; fgets(word, 14, stdin); fputs(word, stdout);1、假设输入 17 个字符,该程序输出仅会输出前 13 个字符(
fgets只读入第二个参数-1个字符)
2、假设输入 6 个字符,fgets()函数会将末尾的换行符也储存起来,如果使用puts()函数打印则会附带一个换行符,如果使用fputs()则不会
3、fgets()由于储存换行符的特性常常与fputs()配对使用。fputs()第二个参数指明它要写入的文件,如果要显示在屏幕上,则应使用stdout(标准输出)作为参数
4、fgets()函数返回指向 char的指针。如果一切顺利,该函数返回地址与传入的第一个参数相同。但是,如果函数读到文件结尾,它将返回一个空指针(null pointer),该指针保证不会指向有效数据,在代码中可以用数字 0 代替,不过 C 语言中用宏NULL代替更常见示例程序
#include <stdio.h> int main(void) { char word[10]; puts("输入字符串(单独换行结束):"); // fgets输入,返回值不等于空指针(文件结尾)且判断第一个字符不为换行符 while (fgets(word, 10, stdin) != NULL && word[0] != '\n') fputs(word, stdout); puts("Done."); return 0; }by the way, the gets() function by the way, the gets() function hello, world hello, world how about you? how about you? Done.示例解析
1、虽然word的长度被设置为10(即实际读入 9 个字符),但处理更长的字符串时貌似并没有问题,原理如下
2、之前提到过,程序的输入使用了缓冲区,所以输入更长的字符串被储存在缓冲区内等待处理。第一轮while迭代按fgets()函数要求只读入 9 个字符(即by the wa,储存为by the wa\0),然后处理(即输出)该字符串,fputs()打印且不换行
3、随后进入第二轮迭代,从缓冲区中读取剩余未读取的字符y, the ge并存储,再次输出,由于fputs()的输出未换行,所以与上次输入拼接在了一起。以此类推特殊处理(需要对应操作时可参考处理思路)
处理换行符(查找换行符,将其替换为空字符)
while (word[i] != '\n') // 假设 \n 在 word 中,while循环检测跳过非换行符的部分 i++; word[i] = '\0'; // 将换行符替换为空字符处理留在缓冲区中的多余字符(丢弃多余字符)
while (getchar() != '\n') // 读取但不存储输入,包括\n continue;
gets_s()函数
C11新增的
gets_s()函数和fgets()类似,用一个参数限制读入的字符数,其语法为gets_s(字符串名, 字符数),但由于是可选标准,所以某些编译器可能不支持gets_s与fgets()的区别1、
gets_s只从stdin标准输入中读取数据,所以不需要第三个参数
2、如果gets_s读到换行符,会舍弃换行符而不是储存它
3、如果gets_s读到最大字符数都没有读到换行符,将会执行以下几步。首先把目标数组的首字符设置为空字符,读取并丢弃随后的输入直至换行符或文件结尾,然后返回空指针。接着调用依赖实现的处理函数(或你选择的其他函数),可能会终止或退出程序
4、第二个特性说明,只要不超过最大值,这两个函数几乎完全一样;第三个特性说明,要使用gets_s函数还需进一步学习
scanf()函数
scanf()与gets()、fgets()的区别1、最主要的区别在于它们如何确定字符串的末尾。
scanf()更像获取单词函数,而非获取字符串函数
2、如果预留的储存区装得下输入行,gets()和fgets()会读取第一个换行符前所有的字符
3、scnaf()有两种方式确定输入结束,无论哪种方式,都从第一个非空白字符作为字符串开始。如果使用%s转换说明,则以下一个空白字符作为字符串结束;如果指定了字段宽度,如%10s,那么将读取 10 个字符或读到第一个空白符停止
字符串输出
puts()函数
puts()的使用char word[81] = "hello world"; puts(word);1、
puts()函数很容易使用,只需要把字符串地址传递给它即可。puts()只能用来打印字符串
2、puts()在显示字符串时会自动在其末尾添加一个换行符
3、puts()如何知道在哪停止?其在检测到空字符(\0)时就停止输出,所以必须确保有空字符。典型错误为打印字符数组char word[81] = {'h','e','l','l','o'},字符数组是没有空字符的
fputs()函数
fputs()与puts()的区别1、
fputs()与puts()就如同fgets()与gets()相似,前者是后者的针对文件定制的版本
2、fputs()函数的第二个参数指明要写入数据的文件,如果打印在屏幕上,可以用stdout(标准输出)作为参数
3、与puts()不同,fputs()不会在末尾添加换行符
printf()函数
和
puts()等函数一样,printf()也把字符串地址作为参数。printf()输出字符串虽然用起来不如puts()方便,但其更加全能和可控printf()不会在每个字符串末尾添加换行符,所以必须人为指定(使用\n)在哪里使用换行符
自定义输入/输出函数
不一定非要使用 C 库的标准函数,当然我们也可以自己通过
getchar()和putchar()这两个功能更简单的函数写一个我们自己需求的函数打印字符串,不添加\n
#include <stdio.h> // 因为不需要改变字符串值,所以使用const保护数据 void put1(const char *str) { while (*str != '\0') // str++指的是指针指向地址递增,而不是指向的数值递增 putchar(*str++); }一个能统计打印字符个数的 puts()函数
#include <stdio.h> int put2(const char *str) { int count = 0; // 当str指向空字符时,*str值为0,即false,循环结束 while (*str) { putchar(*str++); count++; } putchar('\n'); // puts额外添加的换行符,单独输出 }优化的 fgets()函数,读取整行输入并用空字符代替换行符(即不存储换行符),或读取一部分输入舍弃其余部分(即越界部分不存储)
#include <stdio.h> // 函数的返回值是字符串(char *s_gets) char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; }
字符串函数
C 库提供了多个处理字符串的函数,ANSI C把这些函数原型放在
string.h头文件中(即使用需要调用string.h头文件)strlen()函数
strlen()函数用于统计字符串有效字符的个数(不含空字符)使用
strlen()截断字符串#include <stdio.h> #include <string.h> // 特别注意需要头文件 void fit(char *str, int size) { if (strlen(str) > size) // 判断字符串是否比截断位置长 str[size] = '\0'; // 将第size+1位置的字符替换成空字符 }1、由于
puts()函数检测到空字符停止输出的特性,所以将第size+1位置替换为空字符,便可实现在此处停止输出
2、若size传入40,则意味着输出显示 40 个字符,因为str[size]的size作为下标,实际修改的是第 41 位的值
3、可以使用puts(arr + (size+1))(arr 代指主函数中原字符串名)输出剩余字符,但被替换为空字符的字符已被修改无法输出。arr + (size+1)实际就是被替换字符的下一个字符的地址,即跳过被修改的\0位置向后输出
strcat()函数
1、
strcat()函数用于拼接字符串
2、strcat()接收两个字符串作为参数。将第二个字符串的备份,拼接在第一个字符串末尾,并把拼接后的新字符串作为第一个字符串,第二个字符串不变
3、strcat()返回第一个参数,即拼接后的第一个字符串的地址
4、注意,该函数无法检测拼接第二个字符串后,第一个字符串是否越界,需要小心使用strncat()函数
1、
strncat()函数也用于拼接字符串,其为strcat()的更优选,可以预防越界
2、相比strcat(),strncat()多了第三个参数用于指定最大添加字符数。其在拼接时,拼接到指定大小或遇到空字符时停止strcmp()函数
strcmp介绍1、
strcmp()函数用于检测字符串的内容是否相等
2、一般程序中,直接比对两个字符串名,比对的是他们的地址是否相同,而非值是否相同,strcmp()便用于检测值是否相同。比如作为循环条件判断时arr != "Quit"就是典型错误,因为比对地址永远会得到false
3、strcmp()比较的是字符串,而不是整个数组。例如一个数组占用40 字节,但其仅储存5 个字符+1 个空字符共计6 字节。此时strcmp()函数只会比较该数组第一个空字符前面的部分。所以可以用strcmp()比较存储在不同大小数组中的字符串strcmp()返回值1、当两个字符串比对完全相同,则返回 0,不同则返回非零值
2、strcmp()按照顺序依次比对字符,如果比对字符(ASCII 码值)前者比后者大(C 和 A),则返回 1;如果后者比前者大(A 和 C),则返回 -1
3、有些系统对于上面的结果可能为2 与 -2,这些系统的返回值为两者的ASCII 码值的差。但无论如何,正负的规律不变
4、注意ASCII 码中大写字母与小写字母比对,相差 32,即小写 = 大写 + 32
strncmp()函数
1、
strncmp()函数也用于检测字符串的内容是否相等
2、strncmp()相比strcmp()多了第三个参数,用于限定最大对比到第多少位
3、strncmp()可以限制只比对多少位,例如需要查找以 astro 开头的单词,strncmp(arr, "astro", 5)则表示只比对前五位是不是astro。而strcmp()会一直比对,直至发现不同,这一过程可能会持续到字符串末尾,且比对全部字符strcpy()函数
1、
strcpy()函数用于拷贝字符串
2、前面提到过,如果pts1和pts2都是指向字符串的指针,那么pts2 = pts1这个语句拷贝的是字符串的地址而不是字符串本身
3、strcpy()函数接受两个参数strcpy(str1, str2),其将后者(地址)指向的字符串拷贝至前者(地址)。拷贝出来的字符串(前者)被称为目标字符串,最初的字符串(后者)被称为源字符串。实际过程中,strcpy()函数先创建源字符串内容的副本,再让目标字符串指向该副本。如果其第一个参数是数组,不必指向数组的开始。须注意拷贝至的目标字符串需要保证有足够空间容纳源字符串副本
4、strcpy()的返回类型是指向 char 的指针,其返回值是第一个参数的值,即一个字符地址strncpy()函数
1、
strncpy()函数也用于拷贝字符串
2、strncpy()相比strcpy()多了第三个参数,用于指定可拷贝的最大字符数sprintf()函数
1、
sprintf()函数声明在stdio.h头文件中,其用于将数据写入字符串
2、sprintf()可以把多个元素组合成一个字符串,其接受的第一个参数是目标字符串的地址,其余参数和printf()相同,即格式字符串和待写入项的列表
3、示例:sprintf(str, "%s, %6.2f %s", "there are", prize, "yuan.");其他字符串函数
函数 作用 char *strchr(const char *str, char c) 如果 str 字符串包含 c 字符,返回指向 str 中首次出现 c 字符位置的指针,如果未找到 c 字符,返回空指针(末尾的空字符也在查找范围内) char *strrchr(const char *str, char c) 如果 str 字符串包含 c 字符,返回指向 str 中最后一次出现 c 字符位置的指针,如果未找到 c 字符,返回空指针(末尾的空字符也在查找范围内) char *strpbrk(const char *s1, const char *s2) 如果 s1 字符串中包含 s2 字符串中的任意字符,返回指向 s1 字符串首位置的指针,否则返回空指针 char *strstr(const char *s1, const char *s2) 该函数返回指向 s1 字符串中 s2 字符串出现的首位置,如果没有找到,返回空指针 ctype.h 字符函数和字符串
第 7 章中介绍了
ctype.h系列与字符相关的函数,这些函数虽然不能处理整个字符串,但可以通过自定义编写,处理字符串中的字符例如可以自己编写
for循环遍历字符串中的字符,然后对这些字符使用ctype.h中的函数来实现一些功能
字符串示例:字符串排序
示例程序
#include <stdio.h> #include <string.h> #define SIZE 81 // 限制字符串长度 #define LIM 20 //可读入最多行数 #define HALT "" //空字符串停止输入 // 字符串-指针-排序函数 void stsrt(char *strings[], int num) { char *temp; int top, seek; // 选择排序 for (top = 0; top < num - 1; top++) for (seek = top + 1; seek < num; seek++) if (strcmp(strings[top], strings[seek]) > 0) { // 交换指针 temp = strings[top]; strings[top] = strings[seek]; strings[seek] = temp; } } // 前面“自定义函数”中提到过的自定义 s_gets()函数 char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; } int main(void) { char input[LIM][SIZE]; // 储存输入的数组 char *ptstr[LIM]; // 内含指针变量的数组 int ct = 0; // 输入计数 int k; //输出计数 printf("最多输入%d行,我将会对它们排序,在一行开始处回车以停止输入\n", LIM); // 输入行数在范围内 && 输入数据正常 && 第一个字符不是空字符 while (ct < LIM && s_gets(input[ct], SIZE) != NULL && input[ct][0] != '\0') { ptstr[ct] = input[ct]; //设置指针指向字符串 ct++; } // 函数排序 stsrt(ptstr, ct); printf("排序后:\n"); for (k = 0; k < ct; k++) puts(ptstr[k]); return 0; }最多输入20行,我将会对它们排序,在一行开始处回车以停止输入 O that I was where I would be, Then would I be where I an not; But there I an I must be, And where I would be I can not. 排序后: And where I would be I can not. But there I an I must be, O that I was where I would be, Then would I be where I an not;排序指针而非字符串
1、该程序的巧妙之处,在于排序的是指向字符串的指针,而不是字符串本身
2、最初,ptrst[0]指针被设置为input[0],ptrst[1]指针被设置为input[1],以此类推,这意味着指针ptrst[i]指向数组input[i]的首字符。每个input[i]都是内含 81 个元素的数组,每个ptrst[i]都是一个单独的指针变量
3、排序过程中,将ptrst重新排列,并未改变input。例如按字母顺序input[1]应在input[0]前面,程序便交换它们的指针(即ptrst[0]指向input[1]的开始,而ptrst[1]指向input[0]的开始)。这样做比strcpy()函数交换字符串内容要简易快速的多,且还保留了input的原始顺序选择排序算法
1、上例中排序函数使用的排序算法为选择排序,具体通过两层循环处理以下操作(简称内层循环变量为 j,外层循环变量为 i)
2、内层循环负责依次把每个未排序的元素(第 j 个元素)与所排序位置元素(第 i 个元素)比较。如果第 j 个元素在第 i 个元素前面,则交换两者
3、内层循环结束时,第 i 个元素便是这一轮排序中的最值,然后外层循环将 i 加 1(比对下一位置),继续重复这一过程
命令行参数
命令行简介
1、在图形界面普及之前都是用命令行界面,UNIX和DOS就是例子。命令行是在命令行环境中,用户为运行程序输入命令的行
2、假设一个文件中有一个名为fuss的程序,在UNIX环境中运行该程序的命令行是$ fuss,或者Windows命令提示模式下是C> fuss($ 和 C> 都是命令行自带的的行首标识)
3、命令行参数是同一行的附加项,比如$ fuss -r Ginger,一个C 程序可以读取并使用这些附加项示例程序
/*test.c*/ #include <stdio.h> int main(int argc, char *argv[]) { int count; printf("The command line has %d arguments:\n", argc - 1); for (count = 1; count < argc; count++) printf("%d: %s\n", count, argv[count]); printf("\n"); return 0; }编译后使用终端 cmd运行命令行及输出结果
C> test.exe resistance is futile The command line has 3 arguments: 1: resistance 2: is 3: futile程序解析
1、C 编译器允许
main()没有参数或者有两个参数(一些实现会允许更多参数,属于对标准的扩展)
2、main()有两个参数时,第一个参数表示命令行中字符串数量。过去,这个int 类型的参数称为argc(参数计数 argument count)
3、系统用空格表示一个字符串的结束和下一个字符串的开始。因此test.exe resistance is futile中一共 4 个字符串,其中后 3 个供test.exe使用
4、该程序把命令行字符串储存在内存中,并把每个字符串的地址存储在指针数组中,而该数组的地址则被存储在main()的第二个参数中。按照惯例,这个指向指针的指针称为argv(参数值 argument value)
5、如果系统允许,就把程序本身的名称赋给argv[0],把随后的第一个字符串赋给argv[1],以此类推。在我们的例子中,argv[0]指向test.exe,argv[1]指向resistance,argv[2]指向is,argv[3]指向futile
6、main()中的形式参数与其他带形参的函数相同,许多程序员用不同的形式声明argv。如int main(int argc, char **argv),其中**argv与*argv[]等价,argv也是一个指向指针的指针
字符串转换为数字
引入
1、数字(如 213)既能以字符串形式(‘2’,’1’,’3’,’\0’)存储,也能以数值形式(int 类型值 213)存储
2、C 进行数值运算要求用数值形式,但在屏幕上显示数字要求用字符串形式,因为屏幕显示的是字符。printf()和sprintf()函数通过转换说明将数字从数值形式转换成字符串形式,而scanf()可以把输入的字符串转换成数值形式
3、假设你编写的程序需要使用数值命令形参,但是命令形参数被读取为字符串。因此要使用数值必须先把字符串转换成数字。C 的stdlib.h中有一些函数专门用于处理这类问题atoi()示例程序
#include <stdio.h> #include <stdlib.h> int main(int argc, char *argv[]) { int i, times; // 使用atoi()函数转换为数值比对 if (argc < 2 || (times = atoi(argv[1])) < 1) printf("Usage:%s, positive-number\n", argv[0]); // 提示语句 else for (i = 0; i < times; i++) puts("Hello, good looking!"); return 0; }atoi()与其类别函数
1、
atoi()函数用于将字符串转换为int 数值形式
2、atoi()函数能处理字符串开头的数字部分,例如123、123hello都会被转换成123。但如果开头不是整数,如hello123、hello这种字符串,在我们的C 实现中会返回 0,但C 标准规定这种行为是未定义的
3、因此,使用有错误检测功能的strtol()函数(马上介绍)会更安全
4、除了stoi()外,stdlib.h还包含了其他一些类似函数的原型,如下表函数 作用 atoi() 将字符串转换成 int 类型数值形式 atof() 将字符串转换成 float 类型数值形式 atol() 将字符串转换成 long 类型数值形式 strtol()示例程序
#include <stdio.h> #include <stdlib.h> // 前面自定义函数提到的自定义s_gets()函数 char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; } int main(void) { char str[30]; char *end; long value; s_gets(str, 30); value = strtol(str, &end, 10); // 十进制 printf("10进制:%ld,终止于%s (%d)\n", value, end, *end); value = strtol(str, &end, 16); // 十六进制 printf("16进制:%ld,终止于%s (%d)\n", value, end, *end); return 0; }10 10进制:10,终止于 (0) 16进制:16,终止于 (0)10atom 10进制:10,终止于atom (97) 16进制:266,终止于tom (116)strtol()与其类别函数
1、
atrtol()函数用于将字符串转换为long 数值形式
2、strtol()的第一个参数接受一个指向待转换字符串的指针;第二个参数接受一个指针的地址,该指针被设置为标识输入数字结束字符的地址;第三个参数接受一个整数,表示以什么进制读入数字
3、示例中,如果end指针指向一个字符,那么解引用*end就是一个字符。第一次转换读到空字符结束(‘1’,’0’,’\0’),此时end指向空字符,打印end会显示一个空字符,后面的%d输出的*end显示的是空字符的ASCII 码(即 0)
4、第二次转换,以十进制读入字符串,end的值是字符’a’的地址,所以打印end显示字符串”atom”;以十六进制读入,函数将atom的字符 a识别为合法的十六进制数,所以将十六进制数10a转换为266
5、该函数最多可以支持转换三十六进制,即a~z都可以用作数字
6、除了strtol()外,stdlib.h还包含了其他一些类似函数的原型,如下表函数 作用 strtol() 将字符串转换成 long 类型数值形式 strtoul() 将字符串转换成 unsigned long 类型数值形式 strtod() 将字符串转换成 double 类型数值形式(只以十进制转换,只需要两个参数)
储存类别、链接和内存管理
章节概要:储存类别(引入);标识符、表达式与左值;作用域、链接与存储期;作用域;翻译单元和文件;链接;储存期;使块作用域变量具有静态存储期;C 的存储类别;自动变量;内层块与外层块变量同名隐藏;编译器对 C99 和 C11 的支持;寄存器变量;块作用域的静态变量;外部链接的静态变量;内部链接的静态变量;存储类别补充;多文件;储存类别说明符;储存类别和函数;存储类别的选择;随机数函数和静态变量;随机数实现原理;自动重置种子;分配内存:
malloc()和free();calloc()函数;ANSI C 类型限定符;volatile类型限定符;restrict类型限定符;_Atomic类型限定符
储存类别(引入)
C 提供了多种不同的模型或存储类别在内存中存储数据。要理解这些存储类别,需要先复习一些概念和术语
概念术语复习
1、截至目前,所有的示例程序的数据都存储在内存中
2、从硬件层面来看,被存储的每个值都占用一定的物理内存,C 把这样的一块内存称为对象。对象可以存储一个或多个值。一个对象可能并未存储实际的值,但当它存储适当的值时一定具有相应的大小(面向对象编程中对象指的是类对象,其定义包括数据和允许对数据进行的操作,但 C 不是面向对象编程语言)
3、从软件层面来看,程序需要一种方法来访问对象。可以通过声明变量来完成,如int entity = 3;,该声明创建了一个名为entity的标识符。标识符是一个名称,这种情况下,标识符可以用来指定特定对象的内容,其遵循变量的命名规则,该例中,标识符 entity即是软件(即 C 程序)指定硬件内存中的对象的方式标识符、表达式与左值
int entity = 3; int *pt = &entity; int ranks[10];1、变量名不是指定对象的唯一途径
2、pt是一个标识符,它指定了一个储存地址的对象。但是,表达式*pt不是标识符,因为它不是一个名称,但它确实指定了一个对象,这种情况下,它与entity指定的对象相同
3、一般而言,那些指定对象的表达式被称为左值。所以entity既是标识符也是左值,*pt既是表达式也是左值
4、按照这个思路,ranks + 2 * entity既不是标识符(不是名称)也不是左值(不指定内存位置上的内容)。但是表达式*(ranks + 2 * entity)是一个左值,因为它指定了特定内存位置的值,即ranks的第七个元素
5、所有这些示例中,如果可以使用左值改变对象中的值,该左值就是一个可修改的左值
6、例如const char *pc = "Behold";这条声明,创建了一个标识符为 pc的对象,存储字符串的地址。由于可以设置pc重新指向其他字符串,所以标识符 pc是一个可修改的左值(该const只保证字符串内容不被修改)。由于*pc指向存储’B’字符的数据对象,所以*pc是一个左值,但不是可修改的左值;与此类似,因为字符串字面量本身指定了存储字符串的对象,所以它也是一个左值,但也不是可修改的左值新概念引入
1、可以用存储期描述对象,所谓存储期是指对象在内存中保留了多长时间
2、标识符用于访问对象,可以用作用域和链接描述标识符,标识符的作用域和链接表明了程序哪些部分可以使用它
3、不同的存储类别具有不同的存储期、作用域和链接
4、标识符可以在源代码的多文件中共享、可用于特定文件的任意函数中、可仅限于特定函数中使用,甚至只在函数中某部分使用
5、对象可存在于程序的执行期,也可仅存在于它所在函数的执行期。对于并发编程,对象可以在特定线程的执行期存在
作用域、链接与存储期
作用域
作用域描述程序中可访问标识符的区域。一个 C 变量的作用域可以是块作用域、函数作用域、函数原型作用域或文件作用域
块作用域
double blocky(double cleo) // cleo的作用域开始 { double partrick = 0.0; // partrick的作用域开始 for(int i = 0; i < 10; i++) // i的作用域开始 { double q = cleo * i; // q的作用域开始 ... partrick *= q; } // i,q的作用域结束 return patrick; } // cleo,partrick的作用域结束1、到目前为止,示例程序中使用的变量几乎都具有块作用域
2、块是用一对花括号括起来的代码区域。例如整个函数体是一个块,函数中的任意复合语句也是一个块
3、定义在块中的变量具有块作用域,块作用域变量的可见范围是从定义处到包含该定义的块的末尾。另外,虽然函数形参声明在函数的左花括号之前,但它们也具有块作用域,属于函数体这个块,同理对于一些复合语句也是这样(如for()循环)函数作用域
1、函数作用域仅用于
goto语句的标签。这意味着即使一个标签首次出现在函数的内层块中,它的作用域也延伸至整个函数
2、如果在两个块中使用相同的标签会很混乱,标签的函数作用域防止了这样的事情发生函数原型作用域
1、函数原型作用域用于函数原型中的形参名:
int def(int mouse, double large);,函数原型作用域的范围是从形参定义处到函数原型声明结束
2、这意味着,编译器在处理函数原型中的形参时,只关注它的类型,而形参名(如果有的话,因为可以省略)通常无关紧要。而且即使函数原型有形参名,也不必与函数定义中的形参名相匹配
3、只有在变长数组中,形参名才有用:void def(int n, int m, arr[n][m]),方括号中必须使用在函数原型中已声明的名称文件作用域
#include <stdio.h> int units = 0; // 具有文件作用域 void def(void) { ... } int main(void) { ... return 0; }1、变量定义在函数的外面,具有文件作用域。具有文件作用域的变量,从定义处到该定义所在文件末尾均可见
2、如示例units变量,具有文件作用域,def()和main()都可以使用它(更准确的说,units具有外部链接文件作用域,稍后讲解)
3、由于这样的变量可用于多个函数,所以文件作用域变量也被称为全局变量翻译单元和文件
1、你认为的多个文件在编译器中可能以一个文件出现。例如,通常在源代码(.c 拓展名)中包含一个或多个头文件(.h 拓展名),头文件会依次包含其他头文件,所以会包含多个单独的物理文件
2、但是,C 预处理实际上是用包含的头文件内容替换#include指令。所以编译器把源代码文件和所有头文件都看成是一个包含信息的单独文件,这个文件被称为翻译单元
3、描述一个具有文件作用域的变量时,它的实际可见范围是整个翻译单元。如果程序由多个源代码文件组成,那么该程序也将由多个翻译单元组成,每个翻译单元对应一个源代码文件和它所包含的文件
链接
基本概念
1、C 变量有 3 种链接属性:外部链接、内部链接或无链接
2、具有块作用域、函数作用域或函数原型作用域的变量都是无链接变量。这意味着这些变量属于定义它们的块、函数或函数原型私有
3、具有文件作用域的变量可以是外部链接或内部链接。外部链接变量可以在多文件程序中使用,内部链接变量只能在一个翻译单元中使用非正式用语的简称
1、C 标准用内部链接的文件作用域描述仅限于一个翻译单元的作用域,用外部链接的文件作用域描述可延伸至其他翻译单元的作用域,这些是正式用语
2、对于程序员而言这些用语太长了。因此一些程序员把内部链接的文件作用域简称为文件作用域,把外部链接的文件作用域简称为全局作用域或程序作用域如何知道文件作用域变量是内部链接还是外部链接?可以看外部定义是否使用了储存类别说明符
static:int giants = 5; // 文件作用域,外部链接 static int dodgers = 3; // 文件作用域,内部链接 /*该文件和同一程序的其他文件,都可以使用giants,但dodgers属文件私有*/ int main(void) { ... return 0; }
存储期
作用域和链接描述了标识符的可见性,存储期描述了通过这些标识符访问的对象的生存期。C 对象有 4 种存储期:静态存储期、线程存储期、自动存储期、动态分配存储期
静态存储期
1、如果对象具有静态存储期,那么它在程序执行期间一直存在。文件作用域变量具有静态存储期
2、注意,对于文件作用域变量,关键字static表明其链接属性,而非存储期。所有的文件作用域变量都具有静态存储期线程存储期
1、线程存储期用于并发程序设计,程序执行可被分为多个线程。具有线程存储期的对象,从被声明到线程结束都一直存在
2、以关键字_Thread_local声明一个对象时,每个线程都获得该变量的私有备份自动存储期
1、块作用域通常都具有自动存储期。当程序进入定义这些变量的块时,为这些变量分配内存,退出这个块时,释放刚才分配的内存
2、这种做法相当于把自动变量占用的内存视为一个可重复使用的工作区或暂存区。例如一个函数调用结束时,其变量占用的内存可用于存储下一个被调函数的变量
3、变长数组稍有不同,它们的存储期从声明处到块的末尾,而不是从块的开始到末尾
4、我们到目前为止使用的局部变量都是自动类别。然而,块作用域变量也能具有静态存储期,为此需要把变量声明在块中并在声明前加上关键字static使块作用域变量具有静态存储期
void more(int number) { int index; static int ct=0; ... }1、该程序中,变量ct由于声明在块中且使用
static关键字,因此ct 存储在静态内存中,从程序被载入到程序结束期间都一直存在
2、注意,它的作用域定义在more()函数块中,只有在执行该函数时,程序才能使用ct访问它所指向的对象
3、但是,该函数可以给其他函数提供该存储区的地址,以便间接访问该对象,例如通过指针形参或返回值动态分配存储期在本章后面介绍。C 使用作用域、链接和存储期为变量定义了多种存储方案。由于教程不涉及并发程序设计,所以不再赘述这方面的内容
C 的存储类别
C 有 5 种存储类别:自动、寄存器、静态块作用域、静态外部链接、静态内部链接。如下表:
存储类别 存储期 作用域 链接 声明方式 自动 自动 块 无 块内 寄存器 自动 块 无 块内,使用关键字 register静态块作用域(静态无链接) 静态 块 无 块内,使用关键字 static静态外部链接 静态 文件 外部 所有函数外 静态内部链接 静态 文件 内部 所有函数外,使用关键字 static自动变量
属于自动存储类别的变量具有自动存储期、块作用域且无链接,其拥有这三者的所有特点。默认情况下,声明在块或函数头中的任何变量都属于自动存储类别
auto关键字int main(void) { auto int plox; ... return 0; }1、为了更清楚表达你的意图,可以显式使用关键字
auto
2、关键字auto是存储类别说明符。但要注意auto在C++中用法完全不同内层块与外层块变量同名隐藏
#include <stdio.h> int main(void) { int x = 30; // 原始的 x=30 printf("outer block:%p %d\n", &x, x); // 定义一个单独的块 { int x = 77; // 新的 x,隐藏了原始的 x printf("inner block:%p %d\n", &x, x); } // 离开块后,仍使用原始的 x printf("outer block:%p %d\n", &x, x); while (x++ < 33) // 原始的 x { int x = 100; // 新的 x,隐藏了原始的 x x++; printf("while loop :%p %d\n", &x, x); } printf("outer block:%p %d\n", &x, x); return 0; }outer block:000000000061FE1C 30 inner block:000000000061FE18 77 outer block:000000000061FE1C 30 while loop :000000000061FE14 101 while loop :000000000061FE14 101 while loop :000000000061FE14 101 outer block:000000000061FE1C 341、如果内层块与外层块变量同名,内层块将会隐藏外层块的定义,但当离开内层块后,外层块变量的作用域又回到了原来的作用域
2、程序中,较难理解的是while()循环部分。while()循环的条件内使用的x是原始的 x,其每次先参与while的判断,再自增 1(因此参与判断的 x 的值分别为 30、31、32、33,当 x=33 时循环中断,但由于x++所以 x 仍然自增 1)。while()循环的内部,每次执行循环都会创建一个新的 x=100(此时进入块内,与原始的 x 已无关系,原始 x 已被隐藏),由于块作用域每次循环结束就销毁新建的 x,因此实际创建了三个 x,又由于自动存储期每次创建的 x会复用前面销毁的 x 的地址,所以三次输出都是101且地址相同
3、我们的编译器在创建while()循环体中的x时,并未复用前一个块(即程序中单独的那对花括号)销毁的 x 的地址,有的编译器会这样做(则while的x复用前面FE18的地址)没有花括号的块
1、前面提到一个C99特性:作为循环或
if语句的一部分,即使不使用花括号,也是一个块
2、更完整的说,整个循环是它所在块的子块,循环体是整个循环块的子块。相似的,if语句是一个块,其相关联的子语句是if语句的子块编译器对 C99 和 C11 的支持
1、有些编译器并不支持 C99/C11的这些作用域规则(如 Microsoft Visual Stutio 2012)
2、有些编译器会提供激活这些规则的选项,如gcc默认支持了部分 C99 特性,但要用-std=c99选项激活其他特性,命令行输出gcc -std=c99 文件名激活
3、与此类似,gcc或clang都要使用-std=c1x或-std=c11选项,才支持C11 特性
寄存器变量
1、变量通常存储在内存中。但如果幸运的话,寄存器变量将被存储在CPU 的寄存器中,或者概括地说,存储在最快的可用内存中。与普通变量相比,访问和处理这些变量的速度更快
2、由于寄存器变量存储在寄存器中,而非内存中,所以无法获取寄存器变量的地址
3、绝大多数方面,寄存器变量和自动变量一样(块作用域、无链接、自动存储期)。使用存储类别说明符register即可声明寄存器变量,如register int quick;
4、前面之所以说“如果幸运的话”,是因为声明变量为register与直接命令相比更像是一种请求。编译器会根据实际寄存器或最快可用内存的数量衡量你的请求,或者直接忽略。如果忽略,寄存器变量就变成普通变量,但仍然不能对该变量使用地址运算符块作用域的静态变量
静态变量中静态的意思是该变量在内存中原地不动,并不是值不变。具有文件作用域的变量自动具有且必须是静态存储期
前面提到过,可以创建具有静态存储期、块作用域的局部变量。这些变量和自动变量具有相同的作用域,但是程序离开它们所在的函数后,这些变量不会消失。也就是说,这些变量具有块作用域、无链接、静态存储期
static关键字#include <stdio.h> void def(void) { int fade = 1; static int stay = 1; // 块作用域的静态变量,具有静态存储期 printf("fade = %d, stay = %d\n", fade++, stay++); } int main(void) { for (int i = 1; i <= 3; i++) { printf("%d: ", i); def(); } return 0; }1: fade = 1, stay = 1 2: fade = 1, stay = 2 3: fade = 1, stay = 31、在块中,以存储类别说明符
static以声明块作用域的静态变量
2、从程序的运行结果可以看出,静态变量 stay保存了它递增 1后的值,但fade每次都是1。这表明了初始化的不同:每次调用def()都会初始化 fade,但stay只在编译时被初始化一次
3、不能在函数形参中使用static,如int wontwork(static int flu);
外部链接的静态变量
外部链接的静态变量具有块作用域、外部链接、静态存储期。该类别有时称为外部存储类别,属于该类别的变量称为外部变量
外部存储类别的使用
#include <stdio.h> int Errupt; // 外部定义的变量 double Up[100]; // 外部定义的数组 extern char Coal; // 如果只是本文件的声明,extern可省略,如果Coal被定义在另一个源代码文件中,则必须需要extern声明 int main(void) { extern int Errupt; // 可选的声明 extern double Up[]; // 可选的声明 return 0; }1、把变量的定义性声明放在所有函数外便创建了外部变量
2、为了指出该函数使用了外部变量,可以在函数内使用关键字extern再次声明。如果一个源代码文件使用的外部变量被定义在另一个源代码文件中,则必须用extern关键字声明该变量
3、注意示例中,main()中声明Up 数组时不用指明数组大小,因为前面外部变量第一次声明已经提供了数组大小信息。此外main()中的这两条声明都可以省略,使用extern再次声明只是为了说明告知main()要使用这两个变量
4、如果main()中的两条声明都去除extern关键字(如int Errupt;)会怎样?这相当于在main()中创建了一个自动变量,它是一个独立的局部变量,与原来的外部变量 Errupt 不同。此时原先的外部变量仍然存在,只是在块内(即main()中)执行语句时,块作用域的变量(即main()中声明的 Errupt)会隐藏原先文件作用域(即外部变量 Errupt)的同名变量。因此如果不得已要使用与外部变量同名的局部变量,最好在局部变量声明时显式使用auto存储类别说明符,以清楚告知他人你的这种意图
内部链接的静态变量
内部链接的静态变量具有静态存储期、文件作用域、内部链接
static关键字static int svil = 1; // 静态变量,内部链接 int main(void) { ... return 0; }1、在所有函数外部(这点与外部变量相同),用存储类别说明符
static定义的变量具有这种存储类别
2、普通的外部变量可用于同一程序中任意文件的任意函数,但是内部链接的静态变量只能用于同一个文件的任意函数
3、同样可以使用储存类别说明符extern,在函数中再次重复声明任何具有文件作用域的变量。这样的声明不会改变其链接属性
存储类别补充
多文件
只有当程序由多个翻译单元组成时,才体现区别内部链接和外部链接的重要性
C 的变量共享
1、复杂的 C 程序通常由多个单独的源代码文件组成。有时,这些文件可能要共享一个外部变量。C 通过在一个文件中进行定义式声明,然后在其他文件中进行引用式声明来实现共享
2、也就是说,除了一个定义式声明外,其他声明都要使用extern关键字,而且,只有定义式声明才能初始化变量
3、如果外部变量定义在一个文件里,其他文件在使用它前必须先用extern声明它。也就是说,在文件中对外部变量进行定义式声明但是单方面允许其他文件使用,其他文件在用extern声明前不能直接使用
储存类别说明符
C 语言共有6 个关键字作为存储类别说明符,分别是
auto、register、static、extern、_Thread_local、typedef存储类别说明符
1、
typedef与任何内存存储无关,把它归为此类有一些语法上的原因。尤其是,在绝大多数情况下,不能在声明中使用多个存储类别说明符,所以这意味着不能使用多个存储类别说明符作为typedef的一部分
2、_Thread_local是唯一例外,其可以和static或extern一起使用
3、auto表明变量是自动存储期,只能用于块作用域的变量声明中。由于块中的变量本就具有自动存储期,显式使用auto大多情况是为了明确表达要使用与外部变量同名的局部变量的意图
4、register也只用于块作用域的变量,它把变量归为寄存器存储类别,请求最快速度访问该变量,同时还保护变量地址不被获取
5、static说明符创建的对象具有静态存储期。载入程序时创建对象,程序结束对象消失
6、extern表明声明的变量定义在别处
储存类别和函数
函数也有存储类别,可以是外部函数(默认)或静态函数。此外C99新增了第三种类别——内联函数,将在 16 章介绍
示例程序
double gamma(double); // 该函数默认为外部函数 static double beta(int, int); extern double delta(double, int);1、外部函数可以被其他文件的函数访问,静态函数只能用于其定义所在的文件
2、在同一个程序中,其他文件的函数可以调用gamma()和delta(),但不能调用bate(),因为以static存储类别说明符创建的函数属于特定模块私有
3、这样做避免了名称冲突的问题,由于beta()受限于它所在的文件,所以其他文件中可以使用与之同名的函数
4、通常的做法是:使用extern声明定义在其他文件中的函数。这么做是为了表明当前文件中的使用的函数被定义在别处。除非使用static关键字,否则一般函数声明都默认为extern
存储类别的选择
对于使用哪种存储类别的回答,大多数是自动存储类别,要知道默认类别就是自动存储类别
你可能会认为外部存储类别很不错,把所有变量设置成外部变量,就不需要参数和指针在函数间传递信息了。然而,如果这样做,很可能A 函数会违背你的意图,私自修改B 函数要使用的变量。无数程序员的经验表明,随意使用外部存储类别的变量导致的后果会远远超过它带来的便利
保护性程序设计的黄金法则是:“按需知道”原则。尽量在函数内部解决该函数的任务,只共享那些需要共享的变量。因此,在使用某类别前,考虑一下是否有必要这样做
随机数函数和静态变量
C 语言的随机数函数是一个使用内部链接的静态变量函数。ANSI C库提供了一个
rand()函数生成随机数生成随机数有多种算法,ANSI C 允许 C 实现针对特定机器使用最佳算法。然而,ANSI C 标准还提供了一个可移植的标准算法,在不同系统生成相同的随机数。实际上,
rand()是伪随机数生成器,意思是可预测生成数字的实际序列,但是,数字在其取值范围内均匀分布实现原理分析
随机函数
为了看清程序内部情况,我们使用可移植的ANSI 版本(标准版本),而不是编译器内置的
rand()函数(实际使用可以直接使用编译器内置版本,只是生成的公式可能不同)随机函数示例(多文件编译)
/* rand0.c —— 随机数函数文件 */ static unsigned long int next = 1; // 种子 unsigned int rand0(void) { // 生成伪随机数的公式 next = next * 1103515245 + 12345; // 更新种子的公式 return (unsigned int)(next / 65536) % 32768; // 返回随机数的公式,(unsigned int)为强制类型转换 }/* r_drive0.c 主运行文件,与 rand0.c 函数文件一起编译 */ #include <stdio.h> extern unsigned int rand0(void); // 声明跨文件调用外部函数 int main(void) { for (int i = 0; i < 5; i++) { printf("%d\n", rand0()); // 输出随机数 } return 0; }16838 5758 10113 17515 31051示例解析
1、可移植版本的方案开始于一个“种子”数字。该函数使用该种子生成新的数,这个新数又成为新的种子。然后新的种子可用于生成更新的种子,以此类推。因此这个种子需要是一个静态变量,保持时刻存在并记录种子以便函数访问
2、如示例rand0.c函数文件中,seed就是种子,其在ANSI 方案中默认被初始化为 1。生成随机数的函数中,先利用公式和seed 自身数值来更新 seed 的值(即生成新种子),然后return利用公式返回一个按照公式生成的伪随机数,return中%32768说明返回的数一定在0~32767之间
3、r_drive0.c主运行文件和rand0.c一起编译并运行。输出证明调用正常,结果确实生成了伪随机数。但如果多运行几次,会发现每次生成的伪随机数都是按照相同规律出现的(即生成的随机数队列是一样的,都是 16838、5758、10113…)。这是因为,每次程序开始运行时,随机数生成都开始于种子 1
4、为了解决这一问题,我们需要想种办法让每次程序开始时的种子不同,即需要一种办法重置种子
重置种子
我们可以引入另一个函数
srand1()重置种子来解决随机数队列相同的问题(srand1()相当于 C 库的srand()函数)关键在于,要让随机数函数中的next 变量,成为只供
rand0()和srand1()访问的内部链接静态变量(“按需知道”原则)重置种子示例(多文件编译)
/* rand0.c 函数文件 */ static unsigned long int next = 1; // 种子 unsigned int rand0(void) { // 生成伪随机数的公式 next = next * 1103515245 + 12345; // 更新种子的公式 return (unsigned int)(next / 65536) % 32768; // 返回随机数的公式,(unsigned int)为强制类型转换 } // 添加 srand1() 函数 void srand1(unsigned int seed) { next = seed; // 重置种子 }/* r_drive0.c 主运行文件,与 rand0.c 函数文件一起编译 */ #include <stdio.h> #include <stdlib.h> extern unsigned int rand0(void); // 声明跨文件调用外部函数 extern int rand1(void); // 声明跨文件调用外部函数 int main(void) { unsigned seed; printf("输入你想要的随机数的种子\n"); // while判断输入是否有效合法 while (scanf("%u", &seed) == 1) { srand1(seed); // 重置种子 for (int i = 1; i <= 5; i++) printf("%d\n", rand0()); // 输出随机数 printf("输入您的下一个种子,或输入q退出\n"); } return 0; }示例解析
1、由于next具有内部链接的文件作用域静态变量,意味着
rand0()和srand1()都能使用它,但其他文件的函数无法访问它。这符合了程序设计“按需知道”的原则
2、现在的示例程序中,由于每次运行执行了srand1()重置种子,所以种子都是输入的数字,因此随机数函数的随机性更强了
3、但这样重置种子还是比较麻烦,有没有什么办法能自动重置种子,答案是有的
项目中使用随机数(自动重置种子)
在项目中使用随机数,不需要再编写
rand0.c函数文件了,前面只是为了方便看清内部的操作。项目中,可以直接使用编译器提供的版本:rand()函数和srand()函数,它们被集成在stdlib.h头文件中,与前面rand0.c中定义的函数使用方法相同此外,在项目中很多时候需要程序自动重置种子以生成随机数,思路如下
1、如果C 实现允许访问一些可变的量(如,系统时钟),可以用这些值来初始化种子
2、例如ANSI C有一个time()函数,集成在time.h头文件中,可以返回系统时间。该返回值是一个可运算类型,且随时间变化而变化,便很适合做自动重置种子的值
3、time()的返回类型是time_t,这与srand()接受的unsigned int类型不符,但我们可以使用强制类型转换(注意别忘了time.h头文件):srand( (unsigned int)time(0) );
4、一般而言,time()接受的参数是一个time_t类型对象的地址,而时间值就存储在传入的地址上(将时间值存入传入的地址)。当然也可以传入空指针 0作为参数,这样只不过仅能通过返回值机制来提取值
分配内存:malloc()和 free()
我们前面讨论的存储类别有一个共同之处:在确定用哪种存储类别后,根据已制定好的内存管理规则,自动选择作用域和存储期。然而,还有更灵活的选择,即用库函数来分配和管理内存
malloc()函数C 可以在程序运行时分配更多的内存,主要的工具是
malloc()函数,其被包含在stdlib.h中函数使用
1、
malloc()函数用于主动分配内存。其接受一个参数,表示所需的内存字节数,返回动态分配内存块的首字节地址
2、malloc()函数会找到合适的空闲内存块,这样的内存是匿名的。也就是说,该函数可以分配内存,但不会为其赋名
3、可以把返回的首字节地址赋值给一个指针变量,并使用指针访问这块内存函数的返回类型
1、由于char表示1 字节,所以曾经
malloc()的返回类型通常被定义为指向 char 的指针
2、然而从ANSI C标准起,C 使用一个新的类型——指向 void 的指针。该类型相当于一个通用指针,将这种类型赋值给任意其他类型的指针,完全不用考虑类型匹配的问题
3、malloc()函数还可用于返回指向数组的指针、指向结构的指针等,所以通常该函数的返回值会被强制转换为对应匹配的类型。在ANSI C中,应该坚持使用强制类型转换以提高代码可读性(可选,因为第 2 条的说明)
4、如果malloc()分配内存失败,将返回空指针使用
malloc()创建数组#include <stdlib.h> // 注意不要忘了头文件 double *ptd; ptd = (double *)malloc(30 * sizeof(double));1、要使用
malloc()创建一个数组,除了要用malloc()请求一块内存,还需要一个指针记录这块内存的位置
2、示例中,sizeof(double)表示一个 double 类型所需的内存大小,30 * sizeof(double)表示需要 30 个 double 的大小(即可以看做 30 个元素)
3、(double *)为强制类型转换,仅用于提高代码可读性,因为malloc()返回值是指向 void 的指针,可以不用考虑类型匹配问题
4、注意,指针 ptd被声明指向一个 double 类型,而不是指向内含 30 个 double 的块。回忆一下,数组名是该数组首元素地址,因此如果让ptd指向这个块的首元素,就能像使用数组名一样使用它。也就是说,可以使用表达式ptd[0]、ptd[1]分别访问该块的首元素和第二个元素,以此类推malloc()创建的数组的特点1、
malloc()创建的数组和曾经学过的变长数组,都可以创建动态数组
2、动态数组与普通数组的不同在于,前者可以在运行时再选择数组的大小和分配内存(详细介绍见变长数组)
3、此外C99前不允许double item[n];,因为n 不允许是变量,但可以ptd = malloc(n * sizeof(double));,因此malloc()创建数组比变长数组要更灵活
free()函数通常,
malloc()要与free()配套使用,free()可以释放之前malloc()分配的内存,其也被包含在stdlib.h头文件中函数使用
1、
free()函数用于释放malloc()分配的内存,其接受一个参数,即之前malloc()返回的地址
2、因此,动态分配内存的存储期就是从调用malloc()分配内存开始,到调用free()释放内存为止。试想malloc()和free()管理着一个内存池,每次调用malloc()便分配给程序使用,每次调用free()便将内存归还给内存池,以便重复使用这些内存
3、free()只能接受malloc()分配的内存的地址,不能释放通过其他方式(如:声明)分配的内存free()的重要性1、静态内存的数量在编译时是固定的,在程序运行期间也不会改变。自动变量使用的内存数量在程序执行期间自动增加或减少。但是动态分配的内存则只会增加,除非用
free()进行释放
2、假设一个程序需要大量调用malloc()分配内存,但没有使用free()释放内存,就可能在运行时耗尽所有可分配的内存导致程序出错
3、这类为题称为内存泄漏,因此需要及时使用free()释放内存避免这类问题发生
calloc()函数分配内存还可以使用
calloc()函数,其用法与malloc()大致相同函数使用
#include <stdlib.h> long *newmem; newmem = (long *) calloc(100, sizeof(long));1、和
malloc()类似,calloc()在ANSI C前返回指向 char 的指针,在ANSI C后返回指向 void 的指针
2、calloc()接受两个参数(ANSI C规定是size_t类型),第一个参数是所需的存储单元数量,第二个参数是存储单元大小(以字节为单位)
3、calloc()还有一个特性,它会把块中所有位都设置为 0。此外,free()也可以释放calloc()分配的内存
ANSI C 类型限定符
引入
1、我们通常用类型和存储类别来描述一个变量。C90还新增了两个属性:恒常性和易变性,可以分别用关键字
const和volatile来声明,以这两个关键字创建的类型是限定类型
2、C99标准新增了第三个限定符:restrict,用于提高编译器优化
3、C11标准新增了第四个限定符:_Atomic。C11提供了一个可选库,由stdatomic.h管理,以支持并发程序设计,而且_Atomic是可选支持项
4、C99为类型限定符新增了一个属性:它们现在是幂等的。这个属性的意思是,可以在一条声明中多次使用同一个限定符,多余的限定符将被忽略const类型限定符在之前第 4 章和第 10 章已经详细介绍过,在此略过volatile类型限定符作用及用途
1、
volatile类型限定符告知计算机,代理(而不是该变量所在的程序)可以改变该变量的值
2、通常,它被用于硬件地址以及其他程序或同时运行的线程中共享数据。例如,一个地址上可能存储着当前的时钟时间,无论程序做什么,地址上的值都随时间变化而改变。或者一个地址用于接受另一台计算机传入的信息使用语法
/* volatile语法与const一样 */ volatile int loc1; // loc1是一个易变的位置 volatile int * ploc; // ploc是一个指向易变位置的指针为什么列入 ANSI 标准
val1 = x; /* 省略中间一些不使用x的代码 */ val2 = x;1、开始可能认为
volatile是个可有可无的概念,为何ANSI要将其放入标准?是因为它涉及编译器的优化
2、智能的(进行优化的)编译器会注意到以上代码使用了 2 次 x,但并未改变它的值,于是编译器把x 的值临时存储在寄存器中,然后再val2使用x时,才从寄存器中(而非原始内存位置上)读取 x 的值,以节约时间。这个过程被称为高速缓存
3、通常高速缓存是个不错的优化方案,但如果一些其他代理在以上两条语句间改变了 x 的值,就不能这样优化了。如果没有volatile关键字,编译器就不知道这种事情是否发生,因此为了安全起见,编译器不会进行高速缓存。这便是ANSI 前的情况
4、现在,如果声明中没有volatile关键字,编译器会假定变量的值使用过程中不变,然后再尝试优化代码
restrict类型限定符作用及用途
1、
restrict关键字允许编译器优化某部分代码以更好地支持运算
2、它只能用于指针,表明该指针是访问数据对象的唯一且初始的方式深入理解优化部分代码
int ar[10]; int *restrict restar = (int *)malloc(10 * sizeof(int)); int *par = ar; /*-----------------------------------------------------*/ for (int n = 0; n < 10; n++) { par[n] += 5; restar[n] += 5; ar[n] += 2; par[n] += 3; restar[n] += 3; }1、这里,指针restar是访问
malloc()所分配内存的唯一且初始的方式,因此可以用restrict限定它;而指针par既不是访问 ar 数组中数据的初始方式,也不是唯一方式,所以不用将其设置为restrict
2、由于之前声明了 restar为restrict,编译器可以把for()中涉及restar的两条语句简化替换为restar[n] += 8;(原本是先+5,后+3)。但是如果将for()中与par相关的两条语句简化替换为par[n] += 8;就不可以,因为par在两次访问相同数据之间,用 ar 改变过该数据的值
3、在本例中,如果未使用restrict,编译器就必须假设最坏的情况(即两次使用指针之间,其他标识符可能更改了数据)。如果使用了restrict,编译器则可以选择捷径优化计算
_Atomic类型限定符简介概述
1、并发程序设计把程序执行分为可以同时执行的多个线程。这给程序设计带来了新的挑战,包括如何管理并访问相同数据的不同线程
2、C11通过包含可选的头文件stdatomic.h和threads.h提供了一些可选的(不是必须实现的)管理方法
3、值得注意的是,要通过各种宏函数来访问原子类型。当一个线程对一个原子类型的对象执行原子操作时,其他线程不能访问该对象,如下示例示例程序
#include <stdatomic.h> int hogs; // 普通声明 hogs = 12; // 普通赋值 /*---------------可以替换为---------------*/ _Atomic int hogs; // hogs是一个原子类型的变量 atomic_store(&hogs, 12); // stdatomic.h中的宏1、这里,在hogs中存储的12是一个原子过程,其他线程不能访问 hogs
2、编写这一代码的前提,是编译器要支持这一新特性
文件输入/输出
章节概要:与文件进行通信;文本模式和二进制模式;I/O 的级别;标准文件;标准 I/O;
fopen()函数;文件指针;getc()和putc()函数;fclose()函数;指向标准文件的指针;简单的文件压缩程序;文件 I/O;fprintf()、fscanf()函数和rewind()函数;fgets()和fputs()函数;随机访问:fseek()和stell();fgetpos()和fsetpos()函数;其他标准 I/O 函数;ungetc()函数;fflush()函数;setvbuf()函数;二进制 I/O:fread()和fwrite();feof()和ferror()函数
与文件进行通信
有时,需要程序从文件中读取信息或把信息写入文件。这种程序与文件交互的形式就是文件重定向(第 8 章介绍过)。这种方法很简单,但是有一定限制,尤其对于交互性程序。C 提供了更强大的文件通信方法,可以在程序中打开文件,然后使用特殊的I/O 函数与文件交互。在研究这些方法之前,先简要介绍下文件的性质
文件是什么
1、文件通常是在磁盘或固态硬盘上的一段已命名的存储区
2、对我们而言,stdio.h就是一个文件的名称,该文件中包含一些有用的信息。对于操作系统而言,文件更复杂一些
3、例如,大型文件会被分开存储,或者包含一些额外的数据,方便操作系统确定文件的种类。然而这些都是操作系统所关心的,程序员关心的是C 程序如何处理文件
4、C 把文件看做是一系列连续的字节,每个字节都能被单独读取。这与UNIX环境中的文件结构相对应。由于其他环境中可能无法完全对应这个模型,C 提供两种文件模式:文本模式和二进制模式文本模式和二进制模式
首先,要区分文本内容与二进制内容、文本文件格式和二进制文件格式以及文件的文本模式和二进制模式
文本与二进制的文件格式和内容
1、所有文件的内容都以二进制形式(0 或 1)存储
2、但是,如果文件最初使用二进制编码的字符(如 ASCII 或 Unicode)表示文本,该文件就是文本文件,其中包含文本内容
3、如果文件中的二进制值表示机器语言代码、数值数据、图片或音乐编码等,该文件就是二进制文件,其中包含二进制内容文本与二进制模式
1、由于各个操作系统对文件的识别与管理方式不同,为了规范文本文件的处理,C 提供两种访问文件的途径:二进制模式和文本模式
2、在二进制模式中,程序可以访问文件的每个字节。而在文本模式中,程序所见的内容和文件的实际内容不同
3、程序以文本模式读取文件时,把本地环境表示的行末尾或文件结尾映射为C 模式。例如 C 的文本模式在MS-DOS平台,读取文件时,会把\r\n(MS-DOS 中表示的行末尾)转换成\n,写入文件时,恰好与此相反
4、虽然 C 提供了二进制模式和文本模式,但这两种模式的实现可以相同。因为UNIX只使用一种文件格式,这两种模式对UNIX实现完全相同,对Linux也是如此
I/O 的级别
1、除了选择文件的模式,大多数情况下,还可以选择I/O的两个级别(即处理文件访问的两个级别)
2、底层 I/O使用操作系统提供的基本 I/O 服务,标准高级 I/O使用C 库的标准包和stdio.h头文件定义
3、因为无法保证所有的操作系统都使用相同的底层 I/O 模型,C 标准只支持标准 I/O 包
4、有些实现会提供底层库,但是 C 标准建立了可移植的 I/O 模型,我们主要讨论这些I/O标准文件
1、C 程序会自动打开3 个文件,它们被称为标准输入、标准输出、标准错误输出
2、在默认情况下,标准输入是系统的普通输入设备,通常为键盘;标准输出和标准错误输出是系统的普通输出设备,通常为显示屏
3、通常,标准输入为程序提供输入,它是getchar()和scanf()使用的文件;程序通常输出到标准输出,它是putchar()、puts()和printf()使用的文件
4、第 8 章提到的重定向,便是将其他文件视为标准输入和标准输出,但并不会重定向标准错误输出。这样很好,否则只能打开文件才能看到错误信息了
标准 I/O
标准 I/O 的优点
1、与底层 I/O相比,标准 I/O 包除了可移植以外,还有两个好处
2、第一,标准 I/O有许多专门的函数简化了处理不同 I/O的问题。例如printf()把不同形式的数据转换成与终端相适应的字符串输出
3、第二,输入和输出都是缓冲的。也就是说,一次转移一大块信息而不是一字节信息(通常至少 512 字节)。例如程序读取文件时,一块数据被拷贝到缓存区,这种缓冲极大地提高了数据传输速率示例程序
/*注意本程序使用了命令行参数,需要使用命令行运行并传入参数*/ #include <stdio.h> #include <stdlib.h> // 提供exit()的原型 // 使用命令行参数 int main(int argc, char *argv[]) { int ch; FILE *fp; // 文件指针 unsigned long ct = 0; // 判断命令行参数是否成功读取 if (argc != 2) { // 如果读取有误输出提示语并退出 printf("Usage: %s filename\n", argv[0]); exit(EXIT_FAILURE); } // 判断文件是否成功打开 if ((fp = fopen(argv[1], "r")) == NULL) { printf("Can't open %s\n", argv[1]); exit(EXIT_FAILURE); } // 将文件内容打印到屏幕并记录文件的字符数 while ((ch = getc(fp)) != EOF) { putc(ch, stdout); // 等效于putchar(ch) ct++; } fclose(fp); // 关闭文件 printf("\n%d", ct); return 0; }fopen()函数
程序可以使用
fopen()打开文件,其声明在stdio.h头文件中fopen()的第一个参数是待打开的文件名称,更准确的说,是一个包含该文件名的字符串地址。第二个参数是一个字符串,用于指定打开文件的模式fopen()的模式字符串模式字符串 含义 “r” 以读模式打开文件 “w” 以写模式打开文件,将现有文件的长度截为 0,如果文件不存在,则创建一个新文件 “a” 以写模式打开文件,在现有文件末尾添加内容,如果文件不存在,则创建一个新文件 “r+” 以更新模式打开文件(即可以读写文件) “w+” 以更新模式打开文件(即可以读写文件),将现有文件的长度截为 0,如果文件不存在,则创建一个新文件 “a+” 以更新模式打开文件(即可以读写文件),在现有文件末尾添加内容,如果文件不存在,则创建一个新文件。可以读整个文件,但只能从末尾添加内容 “rb”,”wb”,”ab”,”rb+”,”r+b”,”wb+”,”w+b”,”ab+”,”a+b” 与上一个模式类似,但是以二进制模式而不是文本模式打开文件 “wx”,”wbx”,”w+x”,”wb+x”,”w+bx” (C11)类似非 x 模式,但是如果文件已存在或以独占模式打开文件,则打开文件失败 1、像UNIX和Linux这样只有一种文件类型的系统,带 b 字母的模式和不带 b 字母的模式相同
2、C11新增了带 x 字母的写模式,与以前的写模式相比具有更多特性。第一,如果以传统的写模式打开一个现有文件,fopen()会把该文件长度截为 0,就会丢失该文件的内容;但使用带 x 的写模式,即使fopen()操作失败,也不会删除源文件内容。第二,如果环境允许,x 模式的独占特性使得其他程序或线程无法访问正在被打开的文件fopen()与文件指针1、程序成功打开文件后,
fopen()将返回文件指针,其他 I/O 函数可以使用这个指针指定该文件
2、文件指针(该例中的 fp)的类型是指向 FILE 的指针,FILE是一个定义在stdio.h中的派生类型
3、文件指针并不指向实际的文件,它指向一个包含文件信息的数据对象,其中包含操作文件的I/O 函数所用的缓冲区信息
getc()和 putc()函数
getc()和putc()与getchar()和putchar()作用类似,所不同的是,要告诉getc()和putc()函数使用哪一个文件getc接受一个参数,即文件指针;putc()接受两个参数,第一个是待写入的字符,第二个是文件指针使用方式
1、
ch = getchar();的意思是从标准输入中获取一个字符,而ch = getc(fp);的意思是从fp 指定的文件中获取一个字符。与此类似,putc(ch, fpout);的意思是把字符 ch放入FILE 指针 fpout 指定的文件中
2、示例程序中,putc(ch, stdout);将stdout作为第二个参数。stdout作为与标准输出相关联的文件指针,定义在stdio.h中,所以putc(ch, stdout);与putchar(ch);作用相同
3、如果getc()在读取一个字符时发现是文件结尾,将返回特殊值EOF
fclose()函数
程序可以使用
fclose()关闭文件,必要时刷新缓冲区,其接受一个参数,即文件指针,如fclose(fp)函数关闭 fp 指定的文件对于较正式的程序,应该检查是否成功关闭文件。如果成功关闭,
fclose()返回 0,否则返回EOF
指向标准文件的指针
标准文件 文件指针 通常使用的设备 标准输入 stdin 键盘 标准输出 stdout 显示器 标准错误 stderr 显示器
简单的文件压缩程序
/* 将文件压缩成原来的1/3*(仅压缩大小) */
/* 同样本程序依然使用命令行参数传入参数 */
#include <stdio.h>
#include <stdlib.h> // 提供 exit() 的原型
#include <string.h> // 提供 strcpy()、strcat()的原型
#define LEN 40
int main(int argc, char *argv[])
{
FILE *in, *out; // 声明两个文件指针
int ch;
char name[LEN]; // 存储输出文件名
int count = 0;
// 检查命令行参数
if (argc < 2)
{
fprintf(stderr, "Usage: %s filename\n", argv[0]);
exit(EXIT_FAILURE);
}
// 设置输入
if ((in = fopen(argv[1], "r")) == NULL) // 以读模式打开文件
{
fprintf(stderr, "I couldn't open the file '%s' \n", argv[1]);
exit(EXIT_FAILURE);
}
// 设置输出
strncpy(name, argv[1], LEN - 5); // 拷贝文件名,LEN-5留出5字符添加文件后缀名
name[LEN - 5] = '\0';
strcat(name, ".red"); // 在文件名后添加.red后缀
if ((out = fopen(name, "w")) == NULL) // 以写模式打开文件
{
fprintf(stderr, "Can't create output file\n");
exit(3);
}
// 拷贝数据
while ((ch = getc(in)) != EOF)
if (count++ % 3 == 0)
putc(ch, out); // 打印每三个字符的第一个字符
// 关闭文件,收尾
if (fclose(in) != 0 || fclose(out) != 0)
fprintf(stderr, "Error in closing files\n");
return 0;
}文件 I/O
fprintf()、fscanf()函数和 rewind()函数
fprintf()和fscanf()函数的工作方式与我们熟悉的printf()和scanf()相似,只是前两者需要用第一个参数指定待处理的文件rewind()可以让程序回到文件开始处,其接受一个参数,即文件指针示例程序
/* 将终端输入的字符存入文件,并从文件再次读取输出到终端 */ #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAX 41 int main(void) { FILE *fp; char words[MAX]; if ((fp = fopen("wordy", "a+")) == NULL) { fprintf(stdout, "Can't open 'wordy' file\n"); exit(EXIT_FAILURE); } puts("输入单词将其添加到文件中,在新的一行输入#符号退出"); // 终端提示语 while ((fscanf(stdin, "%40s", words) == 1) && (words[0] != '#')) // 从 stdin 接受至多40字符存入 words,且首字符不为# fprintf(fp, "%s\n", words); // 向 fp 指向的文件输出字符串,内容为 words 的字符 puts("文件预览:"); // 终端提示语 rewind(fp); // 回到文件开始处 while (fscanf(fp, "%s", words) == 1) // 从 fp 指向的文件接受字符,存入 words puts(words); // 输出到屏幕上 fclose(fp); return 0; }
fgets()和 fputs()函数
第 11 章简要介绍过这两个函数,在此简单回顾
fgets()函数1、语法
fgets(words,STLEN,fp);。第一个参数为存储字符串的地址,第二个参数为输入字符串的大小,第三个参数为文件指针
2、fgets()读取输入,直到第一个换行符后,或文件结尾,或STLEN-1个字符,在末尾添加一个空字符使其成为字符串
3、fgets()遇到 EOF时将返回 NULL 值,可以利用这一特性检查是否到达文件结尾;如果未遇到 EOF则返回第一个参数的地址fputs()函数1、语法
fputs(words,fp);。第一个参数为所需输出字符串的地址,第二个参数为文件指针
2、fputs在打印字符串时不会在末尾添加换行符
随机访问:fseek()和 stell()
有了
fseek()函数,便可把文件看做是数组,在fopen()打开的文件中直接移动到任意字节处注意,
fseek()有3 个参数,返回 int 类型的值;ftell()返回 long 类型的值,表示文件中的当前位置示例程序
#include <stdio.h> #include <stdlib.h> #define CNTL_Z '\032' // DOS 文本文件中的文件结尾标记 #define SLEN 81 int main(void) { char file[SLEN]; char ch; FILE *fp; long count, last; puts("输入文件名:"); scanf("%80s", file); if ((fp = fopen(file, "rb")) == NULL) // 只读模式 { puts("无法打开"); exit(EXIT_FAILURE); } fseek(fp, 0L, SEEK_END); // 定位到文件末尾 last = ftell(fp); for (count = 1L; count <= last; count++) { fseek(fp, -count, SEEK_END); // 回退(倒序输出) ch = getc(fp); if (ch != CNTL_Z && ch != '\r') // MS-DOS 文件 putchar(ch); } fclose(fp); return 0; }fseek()函数
fseek的使用1、
fseek()的第一个参数是FILE 指针,指向待查找的文件,fopen()应该已经打开该文件
2、fseek()的第二个参数是偏移量,该参数表示从设置的起始点开始要移动的距离。该参数必须是一个long 类型的值(L 后缀表明其值是long 类型),可以为正(前移)、负(后移)或者0(不动)
3、fseek()的第三个参数是模式,由该参数确定起始点。模式如下表(旧的实现可能缺少这些定义,可以用数值 0L、1L、2L分别表示这三种模式)模式 偏移量的起始点 SEEK_SET 文件开始处 SEEK_CUR 当前位置 SEEK_END 文件末尾 fseek()的一些示例fseek(fp, 0L, SEEK_SET); // 定位至文件开始处 fseek(fp, 10L, SEEK_SET); // 定位至文件中第10个字节 fseek(fp, 2L, SEEK_CUR); // 从文件当前位置前移2字节 fseek(fp, 0L, SEEK_END); // 定位至文件结尾 fseek(fp, -10L, SEEK_END); // 从文件结尾回退10字节如果一切正常,
fseek()的返回值为 0;如果出现错误(如试图移动的距离超出文件范围),其返回值为-1
ftell()函数
ftell()函数的返回类型是long,它返回的是参数指向文件的当前位置距离文件开始处的字节数实例要素分析
1、示例中首先使用了
fseek(fp, 0L, SEEK_END)将当前位置设置在文件末尾
2、此时ftell(fp)的值就是文件开始处到结尾的字节数,last = ftell(fp)将其赋给last
3、然后再是for循环中使用了last作为条件范围
fgetpos()和 fsetpos()函数
函数介绍
1、
fseek()和ftell()的潜在问题是,他们都把大小限制在long 能表示的范围内。鉴于此,ANSI C新增了两个处理较大文件的新定位函数:fgetpos()和fsetpos()
2、这两个函数不使用 long 类型的值表示位置,他们使用一种新类型——fpos_t(file position type,文件定位类型)。fpos_t类型不是基本类型,它根据其他类型来定义
3、fpos_t的变量或数据对象可以在文件中指定一个位置,它不能是数组类型,除此之外,没有其他限制。实现可以提供一个满足特殊平台要求的类型,例如fpos_t可以实现为结构函数使用简介
1、
fgetpos()的函数原型为int fgetpos(FILE * restrict stream, fpos_t * restrict pos);
2、调用该函数时,它把fpos_t 类型的值放在pos 指向的位置上,该值描述文件中当前位置距文件开头的字节数。如果成功,返回 0,如果失败,返回非 0
3、fsetpos()的函数原型为int fsetpos(FILE *stream, const fpos_t *pos);
4、调用该函数时,使用pos 指向位置上的fpos_t 类型值来设置文件指针指向偏移该值后指定的位置。如果成功,返回 0,如果失败,返回非 0。其中,fpos_t类型的值应通过之前调用的fgetpos()获得
其他标准 I/O 函数
ungetc()函数
1、函数原型:
int ungetc(int c, FILE *fp)
2、ungetc()函数把c 指定的字符放回输入流中
3、如果把一个字符放回输入流,下次调用标准输入函数时将读取该字符fflush()函数
1、函数原型:
int fflush(FILE *fp)
2、调用fflush()函数引起输出缓冲区中所有的未写入数据被发送到fp 指定的输出文件,这个过程被称为刷新缓冲区。如果fp是空指针,所有输出缓冲区都被刷新
3、在输入流中使用fflush()效果是未定义的。只要最近一次操作不是输入操作,就可以用该函数来更新流setvbuf()函数
1、函数原型:
int setvbuf(FILE * restrict fp, char * restrict buf, int mode, size_t size)
2、setvbuf()函数创建了一个供标准 I/O 函数替换使用的缓冲区。在打开文件后且未对流进行其他操作前调用该函数
3、指针 fp识别待处理的流;buf指向待使用的存储区;mode的选择有三种:_IOFBF表示完全缓冲,_IOLBF表示行缓冲,_IONBF表示无缓冲
4、如果buf的值不是 NULL,则必须创建一个缓冲区,如果把NULL作为buf 的值,该函数会为自己分配一个缓冲区
5、如果函数操作成功,返回 0,否则返回非 0 值二进制 I/O:fread()和 fwrite()
引入介绍
1、之前用到的标准 I/O 函数都是面向文本的,用于处理字符和字符串。如何在文件中保存数值信息?
2、用fprintf()函数和%f转换说明只是把数值保存为字符串。例如有double num = 1./3.;的声明,有fprintf(fp, "%f", num);的语句,num也不过只被存储为8 个字符:0.333333,存储后,读取文件时就无法将其恢复为更高的精度。一般而言,fprintf()把数值转换为字符数据,这种转换可能会改变值
3、为保证数值在存储前后一致,最精确的做法是使用与计算机相同的位组合来存储。因此,double 类型的值应该存储在一个double 大小的单元中。如果以程序所用的表示法把数据存储在文件中,则称以二进制形式存储数据
4、对于标准 I/O,fread()和fwrite()函数用于以二进制形式处理数据
fwrite()函数char buffer[256]; fwrite(buffer, 256, 1, fp); /*-----------------------*/ double earnings[10]; fwrite(earnings, sizeof(double), 10, fp);1、函数原型:
size_t fwrite(const void * restrict ptr, size_t size, size_t nmemb, FILE * restrict fp)
2、fwrite()把二进制数据写入文件。其中指针 ptr是待写入数据块的地址,size表示待写入数据块的大小(以字节为单位),nmemb表示待写入数据块的数量(也是一次性写入数据块的数量),fp表示待写入的文件
3、注意fwrite()第一个参数类型是指向 void 的指针(通用类型指针),因此示例中分别传入指向 char 的指针和指向 double 的指针都是合法的
4、fwrite()函数返回成功写入项的数量。正常情况下返回值就是nmemb,出现错误返回值就会比 nmemb 小fread()函数double earnings[10]; fread(earnings, sizeof(double), 10, fp);1、函数原型:
size_t fread(void * restrict ptr, size_t size, size_t nmemb, FILE * restrict fp)
2、fread()函数用于读取被fwrite()写入文件的数据。其接受参数与fwrite()一致,其中ptr是待读取文件数据在内存中的地址,fp指定待读取的文件
3、fread()函数返回成功读取项的数量。正常情况下返回值就是nmemb,出现错误或读到文件结尾返回值就会比 nmemb 小
feof()和 ferror()函数
1、函数原型:
int feof(FILE *fp),int ferror(FILE *fp)
2、如果标准输入函数返回EOF,则通常表明函数已到达文件结尾。然而当出现读取错误时,函数也会返回EOF。feof()和ferror()用于区分这两种情况
3、当上一次输入调用检测到文件结尾时,feof()返回非 0 值,否则返回 0;当读或写出现错误,ferror()返回非 0 值,否则返回 0
结构和其他数据形式
章节概要:初识结构体;建立结构声明;定义结构变量;初始化结构;访问结构成员;结构的初始化器;结构数组;声明结构数组;标识结构数组的成员;嵌套结构;指向结构的指针;声明和初始化结构指针;用指针访问成员;向函数传递结构的信息;传递结构成员;传递结构的地址;传递结构;其他结构特性;使用结构数组的函数;结构与内存分配;结构中的字符指针与
malloc();复合字面量和结构;伸缩型数组成员;匿名结构;把结构内容保存到文件;链式结构;联合简介;枚举类型;共享名称空间;typedef简介;其他复杂的声明;类型声明黄金法则;函数指针
初识结构体
示例问题:创建图书目录
引入
1、假如你需要打印一份图书目录,要打印每本书的各种信息(书名、作者、出版社、日期、页数等)。这些信息其中一些可以存储在字符数组中,其他一些又需要int 数组或float 数组
2、用7 个不同的数组分别记录比较繁琐,尤其是如果你需要多份列表(一份按书名排序,一份按作者排序等)。如果能把图书目录的信息都包含在一个数组里更好,每个元素包含一本书的相关信息
3、我们需要一种既能包含字符串又能包含数字的数据形式,而且还要保持各信息的独立。C 的结构体就满足这种情况下的需求示例程序
#include <stdio.h> #include <string.h> #define MAXTITL 41 // 书名最大长度+1 #define MAXAUTL 31 // 作者姓名最大长度+1 // 之前自己自定义的 s_gets 函数 char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; } // 定义结构模板:标记是 book struct book { char title[MAXTITL]; char author[MAXAUTL]; float value; }; // 结构模板结束,注意分号 int main(void) { struct book library; // 把 library 声明为一个 book 类型的变量 printf("输入书名:"); s_gets(library.title, MAXTITL); // 使用 s_gets 函数访问将信息写入 library.title,即结构中的 title 变量 printf("输入作者:"); s_gets(library.author, MAXAUTL); printf("输入价钱:"); scanf("%f", &library.value); printf("书名:%s\n作者:%s\n价钱:%.2f", library.title, library.author, library.value); return 0; }
建立结构声明
结构声明描述了一个结构的组织布局,声明类似下面这样:
struct book { char title[41]; char author[31]; float value; };声明分析
1、该声明描述了一个由两个字符数组和一个 float 类型变量组成的结构。该声明并未创建实际的数据对象,只描述该对象由什么组成
2、有时我们把结构声明称为模板,因为它勾勒出结构是如何存储数据的。但注意此模板并非C++的模板,C++的模板要更为强大
3、定义时,首先是关键字struct,表明跟在其后的是一个结构,后面是一个可选的标记(该例中为 book),稍后程序中可以使用该标记引用该结构。所以后面程序可以声明struct book library;,这把library声明为一个使用 book 结构布局的结构变量
4、在结构声明中,用一对花括号括起来的是结构成员列表。每个成员都用自己的声明来描述,成员可以是任意一种数据类型,甚至可以是其他结构。右花括号后面的分号是必需的,表示结构布局定义结束
5、可以把结构声明放在所有函数外部(如本例),也可以放在一个函数定义的内部。如果放在函数内部,则该结构标记仅供该函数内部使用
定义结构变量
定义结构变量
1、结构有两层含义。一层含义是结构布局(未让编译器为数据分配空间);另一层含义(同时也是下一步)是创建一个结构变量
2、程序中创建结构变量的一行是struct book library;,编译器执行这行代码便创建了一个结构变量 library。编译器使用 book 模板为该变量分配空间,这些分配的空间都与名称 library结合在一起
3、在结构变量的声明中,struct book所起的作用相当于一般声明中的int或float。例如,你也可以定义两个struct book类型的变量,或者定义指向struct book类型结构的指针
4、如struct book doyle, panshin, *ptbook;,其中的doyle和panshin都是以 book 为模板定义的独立的结构变量,指针 ptbook可以指向任何book 类型的结构变量补充说明
就计算机而言,
struct book library;这条声明,是以下声明的简化:struct book { char title[41]; char author[31]; float value; } library; // 声明的右花括号后跟变量名换言之,声明结构的过程和定义结构变量的过程可以组合成一个过程。如下,组合后可以省略结构标记:
struct { char title[41]; char author[31]; float value; } library;然而,如果打算多次使用结构模板,就要使用带标记的形式。所以不建议使用以上形式单独组合使用
初始化结构
我们可以通过
int count = 0;和int fibo[4] = {0,1,2,3};初始化变量和数组,结构变量能否初始化?初始化一个结构变量与初始化数组语法类似(但要注意 ANSI C 前不能用自动变量初始化结构):
struct book library = { "This is book name", "author name", 1.95 };简言之,可以使用一对花括号括起来的初始化列表来初始化结构变量,各项用逗号分隔。示例之所以换行是为了提高代码可读性
访问结构成员
1、结构就类似于一个超级数组,想要访问这个超级数组中的元素,需要使用结构成员运算符——点
.
2、例如library.value即访问library的value部分。你可以像使用任何float 变量那样使用library.value
3、本质上,.title、.author和.value就相当于book 结构的下标结构的初始化器
C99和C11为结构提供了指定初始化器,其语法与数组的指定初始化器类似
结构的初始化器使用点运算符和成员名标识特定的元素。例如先初始化 value,再初始化 author,示例如下:
struct book library = { .value = 10.99, .author = "author name" };与数组类似,在指定初始化器后面的普通初始化器,会初始化指定成员后面的成员。如下示例,value先被指定初始化为10.01,后被普通初始化覆盖为19.11(因为其模板定义时紧跟在 author 后面,即为 author 后面的成员)
struct book library = { .value = 10.99, .author = "author name", 19.11 };
结构数组
示例拓展
引入
1、接下来,我们要使上面的程序拓展成可以处理多本书,每本书的信息都可以用一个book 类型的结构变量来表示
2、可以使用这一类型的结构数组来处理多本书,如下面的示例程序
3、注意示例程序创建了一个内含100 个结构变量的结构数组。由于该数组是自动存储类别的对象,信息被存储在栈中。如此大的数组需要很大一块内存,这可能导致一些问题,比如栈溢出。这是由于编译器可能使用了一个默认大小的栈,要修正这个问题,可以使用编译器选项设置栈大小为10000,或者也可以创建静态或外部数组(这样不会存储在栈内)示例程序
#include <stdio.h> #include <string.h> #define MAXTITL 41 // 书名最大长度+1 #define MAXAUTL 31 // 作者姓名最大长度+1 #define MAXBKS 100 // 书籍最大数量 // 之前自己自定义的 s_gets 函数 char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; } struct book { char title[MAXTITL]; char author[MAXAUTL]; float value; }; int main(void) { struct book library[MAXBKS]; // book 类型结构的数组 int count = 0, index; printf("输入书名,在新行行首换行停止程序:"); // 计数小于最大书籍数 && 输入title正常 && 不停止程序 while (count < MAXBKS && s_gets(library[count].title, MAXTITL) != NULL && library[count].title[0] != '\0') { printf("现在输入作者:"); s_gets(library[count].author, MAXAUTL); printf("现在输入价钱:"); scanf("%f", &library[count++].value); // 输入结束后,count++ while (getchar() != '\n') // 清理输入行(scanf输入会保留换行符) continue; if (count < MAXBKS) printf("输入下一本书名:"); } if (count > 0) { printf("这是你的书籍信息单:\n"); for (index = 0; index < count; index++) printf("%s %s %.2f\n", library[index].title, library[index].author, library[index].value); } else printf("没有书籍信息"); return 0; }
声明结构数组
1、声明结构数组和声明其他类型的数组类似,例如
struct book library[50]
2、以上代码把library声明为一个内含 50 个元素的数组。数组的每个元素都是一个book 类型的结构
3、因此,library[0]是第 1 个 book 类型结构变量,library[1]是第 2 个 book 类型结构变量
4、数组名 library本身不是结构名,它只是一个数组名标识结构数组的成员
1、为了标识结构数组的成员,可以采用访问单独结构的规则:结构名后加一个点运算符,再写成员名
2、只是对于结构数组,结构名为library[0]这种形式,而非library(library 只是数组名)
3、因此访问对象为library[0].title、library[1].author等等
嵌套结构
示例程序
#include <stdio.h> #define LEN 20 struct names { char first[LEN]; char last[LEN]; }; struct guy { struct names handle; // 嵌套结构 char favfood[LEN]; char job[LEN]; float income; }; int main(void) { // 初始化结构变量 struct guy fellow = { {"Ewen", "Villard"}, "grilled salmon", "personality coach", 68112.00 }; printf("朋友信息:\n"); printf("名:%s 姓:%s\n", fellow.handle.first, fellow.handle.last); printf("喜欢的食物:%s\n职业:%s\n收入:%.2f",fellow.favfood, fellow.job, fellow.income); return 0; }示例解析
1、首先注意如何在结构声明中创建嵌套结构。和声明int 类型变量一样,先进行声明
struct names handle,该声明表示handle是一个struct names类型的变量(当然文件中应提前声明 names)
2、其次注意如何访问嵌套结构的成员。此时应使用两次点运算符,如fellow.handle.first,意为找到fellow中嵌套的handle,再找到handle的first 成员
3、初始化结构变量时,嵌套的结构也仍需按照初始化语法进行初始化,即需要用花括号包裹
指向结构的指针
为何要使用指向结构的指针
1、就像指向数组的指针比数组本身更容易操控(如排序问题)一样,指向结构的指针通常比结构本身更容易操控
2、在一些早期的 C 实现中,结构不能作为参数传递给函数,但是可以传递指向结构的指针
3、即使能传递一个结构,传递指针通常更有效率
4、一些用于表示数据的结构中包含指向其他结构的指针示例程序
#include <stdio.h> #define LEN 20 struct names { char first[LEN]; char last[LEN]; }; struct guy { struct names handle; char favfood[LEN]; char job[LEN]; float income; }; int main(void) { struct guy fellow[2] = { { {"Ewen", "Villard"}, "grilled salmon", "personality coach", 68112.00 }, { {"Rodney", "Swillbelly"}, "tripe", "tabloid editor", 432400.00 } }; struct guy *him; // 一个指向结构的指针 him = &fellow[0]; // 指针指向 fellow[0] printf("%p %p\n", &fellow[0], &fellow[1]); printf("%p %p\n", him, him + 1); printf("him->income: %.2f (*him).income: %.2f\n", him->income, (*him).income); him ++; // 指向下一个结构 printf("him->favfood: %s (*him).handle.last: %s\n", him->favfood, (*him).handle.last); return 0; }000000000061FD70 000000000061FDC4 000000000061FD70 000000000061FDC4 him->income: 68112.00 (*him).income: 68112.00 him->favfood: tripe (*him).handle.last: Swillbelly声明和初始化结构指针
1、声明结构指针很简单:
struct guy *him;。首先是关键字struct,其次是结构标记guy,然后是一个星号*,其后跟着指针名him。这个语法和其他指针声明一样
2、该声明并未创建一个新的结构,但是指针 him可以指向任意现有的guy 类型结构
3、和数组不同的是,结构变量名并不是结构变量的地址,因此要在结构变量名前面加上取地址运算符&
4、在本例中,fellow是一个结构数组,这意味着fellow[0]才是一个结构。所以要让him指向fellow[0]
5、比较输出的前两行,发现him + 1相当于him指向的地址+84(十六进制 DC4 - D70 = 54,换算十进制 84)。这是因为每个 guy 结构都占84 字节内存(20+20+20+20+4)
6、在有些系统中,一个结构的大小可能大于各成员大小之和,这是因为系统对数据进行校准的过程中产生了一些缝隙。例如有些操作系统必须把每个成员都放在偶数地址或4 的倍数的地址上用指针访问成员
1、第一种方法是使用
->运算符,有以下关系:him == &barney,那么him->income即是barney.income。换句话说,指向结构的指针后面的->运算符和结构变量名后面的.运算符工作方式相同。这里要注意him是一个指针,him->income是指针所指结构的一个成员
2、第二种方法是:如果him == &fellow[0],那么*him == fellow[0],因为&和*是一对互逆运算符。因此有fellow[0].income == (*him).income。注意必须使用圆括号,因为.比*优先级更高
向函数传递结构的信息
传递结构成员
#include <stdio.h> struct funds { double bankfund; double savefund; }; double sum(double x, double y) { return (x + y); } int main(void) { struct funds stan = { 4032.27, 8543.94 }; // 传参 printf("%.2f", sum(stan.bankfund, stan.savefund)); return 0; }1、只要结构成员是一个具有单个值的数据类型,即可把它作为参数传递给接受该类型的函数
2、当然,如果需要在被调函数中修改主调函数中成员的值,需要传递成员的地址(&stan.bankfund)传递结构的地址
#include <stdio.h> struct funds { double bankfund; double savefund; }; double sum(const struct funds *money) // 参数是一个指针 { return (money->bankfund + money->savefund); // 通过指针访问成员 } int main(void) { struct funds stan = { 4032.27, 8543.94 }; // 传参 printf("%.2f", sum(&stan)); return 0; }1、这次将结构的地址作为参数,
sum()函数使用指向 funds 结构的指针(money)作为参数,,把地址&stan传给函数,使money指向结构变量 stan
2、函数中,通过指针访问成员(->运算符),获取stan.bankfund和stan.savefund的值
3、由于该函数并不能改变指针所指向值的内容,所以把money声明为一个指向 const 的指针传递结构
#include <stdio.h> struct funds { double bankfund; double savefund; }; double sum(struct funds moolah) // 参数是一个结构 { return (moolah.bankfund + moolah.savefund); // 通过结构变量访问成员 } int main(void) { struct funds stan = { 4032.27, 8543.94 }; // 传参 printf("%.2f", sum(stan)); return 0; }1、对于允许把结构作为参数的编译器(一些旧的实现不允许这样做),可以通过上述示例方式传递结构
2、函数sum()被调用时,创建了一个名为moolah的自动结构变量,其各成员被初始化为stan 结构变量相应成员的值的副本
3、因此,传递指针的方式使用的是原始的结构进行计算,而这种方式使用的是新创建的 moolah 副本进行计算,因此该程序使用moolah.bankfund访问成员其他结构特性
结构赋值
1、现在的 C 允许把一个结构赋值给另一个结构(但是数组不能这样做)
2、也就是说,如果n_data和o_data都是相同类型的结构,可以这样做:o_data = n_data
3、这条语句把n_data的每个成员的值都赋给o_data的相应成员。即使成员是数组,也能完成赋值结构作为返回值
1、现在的 C,函数不仅能把结构作为参数传递,还能把结构作为返回值返回
2、例如一个常规的函数,接受一个指向结构的指针作为参数,并通过指针改变数据。现在还可以在函数内定义单独的结构变量,在函数内对该结构变量进行操作,最后将其作为返回值返回。
3、例如函数为void def(void),函数内定义结构变量为person,函数返回语句为return person;,主函数有同类型结构变量 person_data,便可以通过person_data = def();将def()函数内的person,作为返回值赋给 person_data
使用结构数组的函数
1、整体传参方式和之前传递一个数组类似。数组名就是首元素地址(数组地址),可以将其传给指针,另外该函数还需要访问结构模板
2、函数定义时参数定义大致为double sum(struct funds money[], int n);,其中money[]就是一个指针(也可以写为*money,这样写是为了提醒他人这是一个数组地址),n为数组元素个数
3、在主函数中调用函数sum(jones, 5)(其中 jones 被定义为struct funds jones[5])。数组名 jones就是首元素地址,因此指针 money初始值相当于money = &jones[0]
4、因为money指向jones 的首元素,所以money[0]就是jones[0]的另一个名称。与此类似,money[1]就是第二个元素,在函数中便使用money[下标].成员名访问成员
结构与内存分配
结构中的字符指针与 malloc()
问题分析
1、到目前为止,我们在结构中都是使用字符数组存储字符串,能否像学习字符串时使用指向 char 的指针存储字符串?
2、通常而言是可行的,但是实际使用时,也会出现指向 char 的指针存储字符串时的通病——内存分配
3、使用这样的方式存储字符串,由于指针所指向的位置并未被分配,因此其存储的位置地址可以是任何值,这可能会篡改程序的其他数据,导致程序崩溃
4、因此如果要用结构存储字符串,用字符数组较为简单,如果使用指针,误用可能导致严重的问题,因此最好配合malloc()函数提前分配内存指针与
malloc()函数#include <stdio.h> #include <string.h> // 提供 strcpy()、strlen()的原型 #include <stdlib.h> // 提供 malloc()、free()的原型 #define SLEN 81 struct namect { char *fname; // 使用指针存储字符串 char *lname; int letters; // 统计名字字符数 }; // 之前自定义的 s_gets() 函数 char *s_gets(char *str, int n) { char *ret_val; // 创建指针(同时也是存储字符串的变量) int i = 0; ret_val = fgets(str, n, stdin); // fgets()返回指向char的指针,如果顺利的话返回地址与传入的第一个参数相同(注意 ret_val 会和 str 指向同一个地址),如果读到文件结尾返回NULL if (ret_val) // 即,ret_val != NULL,判断是否读到文件结尾 { while (str[i] != '\n' && str[i] != '\0') // 忽略跳过正常字符 i++; if (str[i] == '\n') // 出现换行符替换为空字符,即不存储换行符 str[i] = '\0'; else // 否则就是读到了空字符 while (getchar() != '\n') // 丢弃该输入行的其余字符 continue; } return ret_val; } // 获取信息 void getinfo(struct namect *pst) // 传递指针 { char temp[SLEN]; printf("输入名字:"); s_gets(temp, SLEN); // 分配内存以存储名字 pst->fname = (char *)malloc(strlen(temp) + 1); // 分配存储 temp+1 所需的大小 strcpy(pst->fname, temp); // 拷贝字符串 printf("输入姓氏:"); s_gets(temp, SLEN); pst->lname = (char *)malloc(strlen(temp) + 1); strcpy(pst->lname, temp); } // 处理信息 void makeinfo(struct namect *pst) { // 计算名字字符个数 pst->letters = strlen(pst->fname) + strlen(pst->lname); } // 打印信息 void showinfo(struct namect *pst) { printf("%s %s %d\n", pst->fname, pst->lname, pst->letters); } // 释放分配的内存 void cleanup(struct namect *pst) { free(pst->fname); free(pst->lname); } int main(void) { struct namect person; // 名为person的结构变量 getinfo(&person); makeinfo(&person); showinfo(&person); cleanup(&person); return 0; }
复合字面量和结构
1、C99的复合字面量特性不仅可以用于数组,还可以用于结构。如果只需要一个临时结构值,复合字面量很好用
2、可以使用复合字面量创建一个结构作为函数的参数或赋给另一个结构
3、语法与数组复合字面量相似,将类型名放在圆括号中,后面紧跟一个用花括号括起来的初始化列表,示例如下struct book { char title[20]; char author[20]; float value; }; int main(void) { struct book readfirst; readfirst = (struct book){"food","Nick",11.25}; // 使用复合字面量创建临时结构值赋值 return 0; }伸缩型数组成员
简介
1、C99新增了一个特性:伸缩型数组成员。利用这项特性声明的结构,其最后一个数组成员具有一些特性
2、第 1 个特性是,该数组不会立即存在
3、第 2 个特性是,使用这个伸缩型数组成员可以编写合适的代码,就好像它确实存在并具有所需数目的元素声明伸缩型数组成员
struct flex { int count; double average; double score[]; // 伸缩型数组成员 };1、伸缩型数组成员必须是结构的最后一个成员
2、结构中必须至少有一个成员
3、伸缩数组的声明类似于普通数组,只是方括号中是空的使用伸缩型数组成员
声明一个struct flex类型的结构变量时,不能用score去做任何事,因为没有给这个数组预留存储空间
实际上,C99的意图不是让你声明struct flex类型的结构变量,而是希望你声明指向 struct flex 类型的指针,然后用
malloc()函数来分配足够的空间,以存储struct flex类型结构的常规内容和伸缩型数组成员所需的额外空间例如,假设用score表示一个内含 5 个 double 类型值的数组,可以这样做:
struct flex * pf; // 声明一个指针 // 请求为一个结构和一个数组分配存储空间 pf = malloc(sizeof(struct flex) + 5 * sizeof(double)); // 一个struct flex的空间 + 5个double的空间现在有足够储存空间存储count、average和一个内含 5 个 double 类型值的数组,可以用指针 pf访问这些成员:
pf -> count = 5; // 访问 count 成员 pf -> score[2] = 18.5; // 访问数组的一个元素此时,可以将5 个 double 类型值的5换为一个变量 n,就可以更方便的伸缩数组大小。即
malloc()分配时,malloc(sizeof(struct flex) + n * sizeof(double)),其中n就表示伸缩型数组成员的元素个数
一些特殊的处理要求
1、第一,不能用结构进行赋值或拷贝(即
*pf1 = *pf2这样),这样做只会拷贝除伸缩型数组成员外的其他成员。如果确实要拷贝,应使用memcpy()函数(第 16 章介绍)
2、不要以按值方式把这种结构传递给函数。原因相同,按值传递一个参数与赋值类似。应该把结构的地址传给函数
3、不要使用带伸缩型数组成员的结构作为数组成员或另一个结构的成员
匿名结构
匿名结构是一个没有名称的结构成员。C11中,可以用嵌套的匿名成员结构定义结构:
struct person { int id; struct {char first[20]; char last[20];}; // 匿名结构 };特点
1、假设需要一个struct person类型的结构变量 ted,初始化 ted的方式与初始化一个嵌套结构方式相同:
struct person ted = {12, {"Ted", "Grass"}};
2、但是在访问 ted 时,相比嵌套结构简化了步骤。只需把first和last看作person 的成员,使用ted.first即可访问,而不需要像嵌套结构那样使用ted.xxxxx.first访问
3、当然,这样看来也可以把first和last直接作为person 的成员,匿名特性在嵌套联合中更加有用,后续介绍
把结构内容保存到文件
引入
1、由于结构可以存储不同类型的信息,所以它是构建数据库的重要工具。我们要把这些信息存储在文件中,并且能再次检索
2、数据库文件可以包含任意数量的此类数据对象。存储在一个结构中的整套信息被称为记录,单独的项被称为字段
3、或许存储记录最没效率的方法是用fprintf()。首先便是当结构的成员更多时,fprintf()所需要使用的转换说明也更多;其次检索时还存在问题,因为程序要知道一个字段结束和另一个字段开始的位置
4、更好的方案是使用fread()和fwrite()函数读写结构大小的单元。回忆一下,这两个函数使用与程序相同的二进制表示法,如fwrite(&primer, sizeof(struct book), 1, pbooks);。定位到primer 结构变量开始的位置,并把结构中的所有字节都拷贝到pbooks 所指文件中,sizeof(struct book)告诉函数待拷贝的一块数据的大小(即 struct book 类型的大小),1表示一次拷贝一块数据示例程序
#include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXTITL 40 #define MAXAUTL 40 #define MAXBKS 10 // 最大书籍数量 struct book { char title[MAXTITL]; char author[MAXAUTL]; float value; }; // 之前自定义的 s_gets() 函数 char *s_gets(char *str, int n) { char *ret_val; int i = 0; ret_val = fgets(str, n, stdin); if (ret_val) { while (str[i] != '\n' && str[i] != '\0') i++; if (str[i] == '\n') str[i] = '\0'; else while (getchar() != '\n') continue; } return ret_val; } int main(void) { struct book library[MAXBKS]; // 定义结构数组 int ct = 0, index, filecount; FILE *pbooks; int size = sizeof(struct book); // 打开文件 if ((pbooks = fopen("book.dat", "a+b")) == NULL) { fputs("无法打开book.dat\n", stderr); exit(1); } // 读取数据文件中已经存储的数据,存入library,并打印之前存储的数据 rewind(pbooks); // 定位到文件开始处 // 遍历的 ct 小于数组元素个数 && 读取二进制内容并写入library正常 while (ct < MAXBKS && fread(&library[ct], size, 1, pbooks) == 1) { if (ct == 0) puts("book.dat当前的内容:"); // 首次的提示语 printf("%s %s %.2f\n", library[ct].title, library[ct].author, library[ct].value); ct++; } // filecount 记录以前已写到结构数组第几个元素。判断目前结构数组是否有多余位置存储新数据 filecount = ct; if (ct == MAXBKS) { fputs("book.dat文件已满\n", stderr); exit(2); } // 向library写入新数据 puts("请添加新的书籍名称:(在新的一行回车停止)"); // 遍历的 ct 小于数组元素个数 && 读取书籍名称正常 && 不在新的一行回车停止程序 while (ct < MAXBKS && s_gets(library[ct].title, MAXTITL) != NULL && library[ct].title[0] != '\0') { puts("现在输入作者:"); s_gets(library[ct].author, MAXAUTL); puts("现在输入价钱(或编号):"); scanf("%f", &library[ct].value); while (getchar() != '\n') // 清理输入行 continue; if (ct < MAXBKS) puts("输入下一本书的标题:"); ct++; } // 输出添加后的library,并写入数据文件 if (ct > 0) { puts("这是新的书单列表:"); for (index = 0; index < ct; index++) printf("%s %s %.2f\n", library[index].title, library[index].author, library[index].value); fwrite(&library[filecount], size, ct - filecount, pbooks); } else { puts("没有新书写入"); } fclose(pbooks); return 0; }示例重点
1、以
a+b模式打开文件。a+模式允许程序读取文件并可以在末尾追加内容,b表明程序将使用二进制文件格式
2、选择二进制模式是因为fread()和fwrite()要使用二进制文件。rewind()函数确保文件指针处于文件开始处,为读文件做好准备
3、写入新的数据时,我们本也可以用一个循环在文件末尾使用fwrite()一次添加一个结构,但示例中使用fwrite()一次写入一块数据。filecount表示第一个新写入的结构的下标,表达式ct - filecount就是新添加书籍的数量
4、虽然结构中有些内容是文本,但value成员不是文本。如果使用文本编辑器查看book.dat,其中文本部分内容显示正常,但数值部分内容不可读,甚至可能乱码
链式结构
结构有很多种用途,除了前面介绍的,还有一种是创建新的数据形式
1、计算机用户已经开发出的一些数据形式比我们提到过的数组和简单结构能更有效地解决特定问题
2、这些形式包括队列、二叉树、堆、哈希表和图表,许多这样的形式都由链式结构组成
3、通常,每个结构都包含一两个数据项和一两个指向其他同类型结构的指针。这些指针把一个结构和另一个结构链接起来,并提供一种路径能遍历整个彼此链接的结构二叉树演示
1、下图是一个二叉树结构的示意图
2、考虑有10 个节点的树的情况下,他有 210-1 个(或 1023 个)节点,可以存储 1023 个单词
3、如果这些单词以某种规则排列,自上而下逐级查找,最多只需要移动 9 次即可找到;如果放在数组中,至多需要遍历1023 个元素才能找到
联合简介
概述
1、联合是一种数据类型,它能在同一个内存空间中存储不同的数据类型(不是同时存储)
2、其典型的用法是,设计一种表以存储既无规律、事先也不知道顺序的混合类型
3、使用联合类型的数组,其中的联合都大小相等,每个联合可以存储各种数据类型声明联合
创建联合和创建结构的方式相同,需要一个联合模板和一个联合变量
// 声明联合模板 union hold { int digit; double bigfl; char letter; }; // 声明联合变量 union hold fit; // hold 类型的联合变量 union hold save[10]; // 内含10个联合变量的数组 union hold *pu; // 指向 hold 类型联合变量的指针联合与结构的不同
1、根据如上示例声明的结构,可以存储一个 int 类型、一个 double 类型和一个 char 类型的值(三种类型都可以存储)
2、然而,声明的联合,只能存储一个 int 类型或一个 double 类型或一个 char 类型的值(只能存储其一)
初始化联合
union hold valA; valA.letter = 'R'; union hold valB = valA; // 用另一个联合来初始化 union hold valC = {88}; // 初始化联合的第一个元素:digit 成员 union hold valD = {.bigfl = 118.2}; // 指定初始化器1、可以初始化联合,但要注意,联合只能存储一个值。
2、共有三种初始化的方法:把一个联合初始化为另一个同类型的联合;初始化联合的第一个元素;或者根据C99标准,使用指定初始化器使用联合
// 使用联合 fit.digit = 23; // 把 23 存储在 fit 中,占 2 字节 fit.bigfl = 2.0; // 清除 23,存储 2.0,占 8 字节 fit.letter = 'h'; // 清除 2.0,存储 h,占 1 字节 // 使用指针访问联合 pu = &fit; // 此处 pu 是一个指向联合的指针 x = pu->digit; // 相当于 x = fit.digit1、点运算符表示正在使用哪种数据类型
2、在联合中,一次只储一个值。即使有足够的空间,也不能同时存储一个char 类型值和一个int 类型值。编写代码时要注意当前存储在联合中的数据类型
3、和用指针访问结构一样,用指针访问联合也要用->运算符联合的一种用途
引入
1、联合的主要用途之一是,在结构中存储与其成员有从属关系的信息
2、例如,用一个结构表示一辆汽车。如果汽车属于驾驶者,就用一个结构成员描述这个所有者;如果汽车被租赁,就用一个成员来描述其租赁公司示例思路
struct owner // 个人拥有者信息 { char socsecurity[12]; ... }; struct leasecompany // 租赁公司信息 { char name[40]; char headquarters[40]; ... }; union data // 创建联合 { struct owner owncar; // 创建成员,为 owner 类型结构变量 struct leasecompany leasecar; // 创建成员,为 leasecompany 类型结构变量 }; struct car_data // 使用结构表示一辆车的信息 { char make[15]; int status; // 人为约定私有为 0, 租赁为 1 union data onwerinfo; ... };示例说明
1、假设有flits是car_data 类型的结构变量
2、如果flits.status == 0(即私有),程序将设计为使用flits.ownerinfo.owncar.socsecurity
3、如果flits.status == 1(即租赁),程序将设计为使用flits.ownerinfo.leasecar.name
匿名联合
匿名联合和匿名结构的工作原理相同,即匿名联合是一个结构或联合的无名联合成员
例如,我们可以把上面程序的
car_data重新定义:struct owner // 个人拥有者信息 { char socsecurity[12]; ... }; struct leasecompany // 租赁公司信息 { char name[40]; char headquarters[40]; ... }; struct car_data // 使用结构表示一辆车的信息 { char make[15]; int status; // 人为约定私有为 0, 租赁为 1 union // 创建匿名联合 { struct owner owncar; // 创建成员,为 owner 类型结构变量 struct leasecompany leasecar; // 创建成员,为 leasecompany 类型结构变量 }; ... };现在,像匿名结构一样,可以用
flits.owncar.socsecurity代替原先的flits.owninfo.owncar.socsecurity
枚举类型
简介
1、可以用枚举类型声明符号名称来表示整型常量
2、使用enum关键字,可以创建一个新“类型”并指定它可具有的值
3、实际上,enum常量是int类型,因此,只要能使用int 类型的地方就可以使用枚举类型
4、枚举类型的目的,是提高程序的可读性,它的语法与结构的语法相同声明与使用枚举类型
// 声明枚举类型 enum spectrum {red, orange, yellow, green, blue, violet}; // 枚举声明 enum spectrum color; // 声明枚举变量 // 使用枚举类型 color = blue; if (color == yellow) ...; for (color = red; color <= violet; color++) ...;1、第一个声明创建了spectrum作为标记名,允许把
enum spectrum作为一个类型名使用。第二个声明使color作为该类型的变量
2、第一个声明中的花括号内的标识符枚举了spectrum 变量可能有的值。因此,color可能的值是red、orange、yellow等。这些符号常量被称为枚举符
3、虽然枚举符是int 类型,但是枚举变量可以是任意整数类型,前提是该整数类型可以存储枚举常量
4、例如,spectrum的枚举符范围是0 ~ 5,所以编译器可以用unsigned char类型来表示 color 变量C 与 C++的枚举兼容性
1、C 枚举的一些特性并不适用于 C++
2、例如,C 允许枚举变量使用++运算符,但 C++ 标准不允许
3、所以,如果需要和 C++ 标准兼容,必须把上面例子的color声明为int 类型enum 常量
1、blue和red到底是什么?从技术层面看,它们是int 类型的常量
2、例如假定有前面的枚举声明,printf("red = %d, orange = %d", red, orange)的输出为red = 0, orange = 1
3、red成为一个有名称的常量,代表整数 0。类似的,其他标识符都是有名称的常量,分别代表1~5
4、只要能使用整型常量的地方就都能使用枚举常量。例如声明数组时,可以用枚举常量表示数组的大小;在switch语句中,可以把枚举常量作为标签
5、默认情况下,枚举列表中的常量都被赋予0、1、2等枚举常量赋值
1、枚举声明中,可以为枚举常量指定整数值。如
enum levels {low = 100, medium = 500, high = 2000};
2、如果只给一个枚举常量赋值,没有对后面的枚举常量赋值,那么后面的常量会被赋予后续的值
3、例如enum feline{cat, lynx = 10, puma, tiger};,cat的值为0(默认),lynx、puma与tiger的值分别为10、11、12共享名称空间
1、C 语言使用名称空间(namespace),标识程序中的各部分,即通过名称来识别
2、作用域是名称空间概念的一部分:两个不同作用域的同名变量不冲突,两个相同作用域的同名变量冲突
3、名称空间是分类别的,在特定作用域中的结构标记、联合标记、枚举标记都共享相同的名称空间,该名称空间与普通变量使用的空间不同
4、例如在 C 中,同时声明struct rect {double x; double y;};和int rect;不会产生冲突
5、尽管如此,以两种不同的方式使用相同的标识符会造成混乱。另外C++ 不允许这样做,因为它将标识名和变量名放在相同的名称空间里
typedef 简介
typedef 简介
1、
typedef工具是一个高级数据特性,利用typedef可以为某一类型自定义名称。这方面与#define类似,但是两者有3 处不同
2、与#define不同,typedef创建的符号名只受限于类型,不能用于值
3、typedef由编译器解释,而不是预处理器
4、在其受限范围内,typedef比#define更灵活typedef 的使用
1、假设用BYTE表示1 字节的数组,只需像定义char 类型变量一样定义BYTE,然后在定义前面加上关键字
typedef:即typedef char BYTE;
2、随后,便可以使用BYTE来定义变量,如BYTE x, y[10], *z;
3、该定义的作用域取决于typedef定义所在的位置,typedef中使用的名称遵循变量的命名规则
4、通常typedef定义中用大写字母表示被定义的名称,以提醒用户这个类型名是一个符号缩写typedef 的一些用途
typedef的一些特性与#define的功能重合typedef char BYTE; #define BYTE char但是
typedef也有#define没有的功能char * STRING; typedef char * STRING; #define STRING char *1、没有
typedef关键字的话,编译器会把STRING识别为指向 char 的指针
2、使用typedef,编译器将STRING解释成类型的标识符,该类型是指向 char 的指针
3、使用typedef,STRING name, sign;相当于char *name, *sign;,声明的两个变量都是指针
4、但如果使用#define,STRING name, sign;会相当于char *name, sign;,则只有 name 是指针还可以把
typedef用于结构typedef struct complex{ //此处 complex 标识名可省略 float real; float imag; } CONPLEX; struct complex num1; COMPLEX num2;此外,
typedef更常用于给复杂的类型命名,如typedef char (* FRPTC())[5] TYPENAME;
其他复杂的声明
C 允许用户自定义数据形式。虽然我们常用的是一些简单的形式,但是根据需要有时也会用到一些复杂的形式
复杂声明可使用的符号
符号 含义 * 表示一个指针 () 表示一个函数 [] 表示一个数组 一些复杂声明的示例
int board[8][8]; // 声明一个指向 int 数组的数组 int **ptr; // 声明一个指向指针的指针,被指向的指针指向 int int *risks[10]; // 声明一个内含10个元素的数组,每个元素都是一个指向 int 的指针 int (*rusk)[10]; // 声明一个指向数组的指针,该数组内含10个 int 类型的值 int *oof[3][4]; // 声明一个3*4的二维数组,每个元素都是指向 int 的指针 int (*uuf)[3][4]; // 声明一个指向3*4二维数组的指针,该数组中内含 int 类型的值 int (*uof[3])[4]; // 声明一个内含3个元素的数组,其中每个指针都指向一个内含4个 int 类型值的数组符号优先级
1、要看懂以上的声明,需要注意符号的优先级
2、数组名后面的[]和()具有相同优先级,他们比*优先级更高
3、[]和()优先级相同,因此正常情况下,自左向右看类型声明黄金法则
详见我的另一篇博文,点击跳转:类型声明黄金法则
对于这种复杂声明,使用
typedef的作用就逐渐明显了
函数指针
通过上一节的学习可知,可以声明一个指向函数的指针。通常,函数指针用作另一个函数的参数,告诉该函数要使用哪一个函数
函数指针简介与声明
1、假设有一个指向 int 类型变量的指针,该指针就存储着这个int 类型变量存储在内存位置的地址。同样,函数也有地址,因为函数的机器语言实现由载入内存的代码组成,指向函数的指针中存储着函数代码的起始处地址
2、声明一个数据指针时,必须声明指针所指向的数据类型。对于声明函数指针,必须声明指针指向的的函数类型。为此,要指明函数签名,即函数的返回类型和形参类型
3、例如现有函数原型void ToUpper(char *);,声明函数指针应为void (*pf)(char *);。注意由于运算符优先级必须要使用圆括号,否则void *pf(char *);意为pf 是一个返回字符指针的函数使用函数指针
void ToUpper(char *); void ToLower(char *); int round(double); void (*pf)(char *); pf = ToUpper; // 有效,ToUpper是该类型函数的地址 pf = ToLower; // 有效,ToUpper是该类型函数的地址 pf = round; // 无效,round与指针类型不匹配 pf = ToLower(); // 无效,ToLower()不是地址 pf = ToUpper; char mis[] = "Nina Metier"; (*pf)(mis); // 语法1 pf(mis); // 语法21、声明了函数指针后,可以把类型匹配的函数地址赋给它。在这种上下文中,函数名可以用作表示函数的地址
2、既然可以用数据指针访问数据,就可以用函数指针访问函数。只是有两种逻辑上不一致的语法能这样做
3、语法 1中,由于pf 指向ToUpper函数,那么*pf就相当于ToUpper函数。所以(*pf)(mis)与ToUpper(mis)等效
4、语法 2中,由于函数名是指针,那么指针和函数名可以互换使用(从 pf 的赋值表达式就能看出 ToUpper 和 pf 是等价的)。因此pf(mis)和ToUpper(mis)等效函数指针作为参数
1、作为函数的参数是数值指针最常见的用法之一,函数指针亦如此。考虑以下函数原型:
void show(void (*fp)(char *), char *str);
2、它声明了两个形参,fp和str。fp是一个函数指针,str是一个数据指针。更具体地说,fp指向的函数接受char *类型,返回类型为 void;str指向一个char 类型的值
3、可以这样调用函数:show(ToUpper, mis);。在函数内仍可以通过函数指针 fp来调用函数:(*fp)(mis);
位操作
章节概要:二进制数、位、字节;二进制整数;有符号整数;二进制浮点数;其他进制数;八进制;十六进制;进制赋值;C 按位运算符;按位逻辑运算符;移位运算符;常用用法;掩码;打开位;关闭位;切换位;检查位的值;乘除次幂;位字段;简介与声明;位字段的使用;位字段越界问题;位字段示例;对齐特性;对齐特性介绍;
_Alignof运算符;_Alignas说明符;使用示例
二进制数、位、字节
二进制整数
1、通常,1 字节(1 byte)包含8 位(8 bits)。C 语言用字节表示存储系统字符集所需的大小,所以 C 字节可能是8 位、9 位、16 位或其他值
2、不过,描述存储器芯片和数据传输率中所用的字节指的是8 位字节。简化起见,我们假定1 字节是8 位(计算机界常用八位组这个术语特指8 位字节)
3、可以从左往右给这 8 位分别编号7~0。在一字节中,编号是 7的位称为高阶位,编号是 0的位称为低阶位,每一位的编号对应2 的相应指数
4、8 位字节能表示的最大的数是11111111,即255;能表示的最小的数是00000000,即0
5、因此一字节可存储0~255 范围内共256 种值,程序可以用1 字节存储自-128 至 127同样256 种值
有符号整数
符号量表示法
1、如何表示有符号整数取决于硬件,而不是 C 语言
2、也许表示有符号数最简单的办法是用 1 位(如高阶位)存储符号,剩下 7 位表示数字本身。用这种符号量表示法,表示的范围为-127~127
3、这种方法的缺点是有两个 0,即 +0 和 -0,很容易混淆,而且用两个位组合表示一个数字有些浪费二进制补码
1、二进制补码避免了这个问题,是当今最常用的系统
2、二进制补码用 1 字节中的后 7 位表示0~127,通常高阶位设置为 0,表明值为正。如果高阶位是 1,则表明值为负,然后从一个9 位组合的100000000(即二进制的 256)减去一个负数的位组合,结果是该负值的量
3、假设一个负值的位组合是10000000。作为一个无符号整数,该组合表示 128;作为一个有符号整数,该组合表示的值为负(高阶位是 1),值为100000000 - 10000000,该数位-128。类似的,10000001则表示-127,11111111则表示-1。这种方法可以表示-128~127 范围内的数
4、要得到一个二进制补码数的相反数,最简单的方法是反转每一位然后+1。如1 是 00000001,则表示-1应为11111110+1,即11111111二进制反码
1、二进制反码通过反转位组合中的每一位形成一个负数。例如00000001 是 1,11111110 即为-1
2、但这种方法也有一个-0,且仅能表示-127~127 之间的数
二进制浮点数
浮点数分两部分存储:二进制小数和二进制指数
二进制小数
1、一个普通的浮点数 0.527,表示如下:
5/10 + 2/100 + 7/1000。从左往右,各分母都是10 的递增次幂
2、类似的,在二进制小数中,使用2 的递增次幂作为分母
3、所以二进制小数 .101表示为1/2 + 0/4 + 1/8,换为十进制为0.5 + 0 + 0.125,即0.625
4、许多分数不能用十进制精确表示(如 1/3),同样的,许多分数也不能用二进制精确表示。二进制表示法只能精确表示多个 1/2 的幂的和,像1/3或2/5就不能精确表示浮点数表示法
1、为了在计算机中表示一个浮点数,要留出若干位(因系统而异)存储二进制分数,其他位存储指数
2、一般而言,数字的实际值是由二进制小数乘以2 的指定次幂组成
3、在实际计算时,一个浮点数*4,那么二进制小数不变,而是指数*2,二进制分数不变
4、如果一份浮点数乘以一个不是 2 的幂的数,会改变小数部分,如有必要,也会改变指数部分
其他进制数
计算机界通常使用八进制计数系统和十六进制计数系统。因为8 和 16都是2 的幂,比十进制更接近计算机的二进制系统
八进制
1、八进制指八进制计数系统。该系统基于 8 的幂,用0~7 表示数字,满八进一
2、了解八进制最简单的办法是,每个八进制位对应3 个二进制位。八进制转二进制时,每一位对应3 位二进制位,通过二进制对应 2 的幂凑出这一位八进制的值
3、例如,八进制的6转换二进制为110(4+2+0),八进制的35转换二进制为011101(三位拆开看,0+2+1,4+0+1)。左侧的 0 可以省略,中间和右侧的 0 不能省略十六进制
1、十六进制指十六进制计数系统。该系统基于 16 的幂,用0~9表示正常的0~9,用A~F表示10~15,满十六进一
2、因此十进制的17用十六进制表示为11(16+1),十进制的33表示为21(16*2+1),十进制的30表示为1E(16+14)
3、每个十六进制位对应4 个二进制位,因此两个十六进制位恰好对应一个8 位字节,此外十六进制与二进制的转换方法与八进制类似
4、例如十六进制E1转换二进制为11100001(四位拆开看,8+4+2+0,0+0+0+1)进制赋值
1、为变量赋值时可以分别使用
0b、0o、0x表示赋值的数分别为二进制、八进制、十六进制
2、例如可以这样写:num = 0b1001、num = 0o1007、num = 0x100F
C 按位运算符
C 提供按位逻辑运算符和移位运算符。在下面的例子中,为了方便理解,使用二进制计数法写出值
按位逻辑运算符
4 个按位逻辑运算符都用于整型数据,包括char。之所以叫做按位运算,是因为这些操作针对每一个位进行,不影响它左右两边的位
按位取反:
~1、一元运算符
~可以将二进制中的1 变成 0,0 变成 1。如表达式~(10011010)的结果为 01100101
2、假设变量 val已被赋值2。在二进制中,00000010表示2,那么~val的值是11111101,即253
3、注意,只是使用运算符不会改变 val 的值,只是创建了一个可以使用或赋值的新值:newval = ~val。如果需要改变val 的值需要对 val 赋值:val = ~val按位与:
&1、二元运算符
&通过逐位比较两个运算对象,生成一个新值
2、对于每个位,只有两个运算对象中相应的位都为 1时,对应结果位的值为 1
3、如表达式(10010011) & (00111101)的结果为 00010001按位或:
|1、二元运算符
|通过逐位比较两个运算对象,生成一个新值
2、对于每个位,只要两个运算对象中相应的位至少有一个为 1时,对应结果位的值为 1
3、如表达式(10010011) | (00111101)的结果为 10111111按位异或:
^1、二元运算符
^通过逐位比较两个运算对象,生成一个新值
2、对于每个位,两个运算对象中相应的位不同时,对应结果位的值为 1
3、如表达式(10010011) ^ (00111101)的结果为 10101110对于
&、|、^运算符,同样也有复合运算符&=、|=、^=
补充:按位运算的性质
1、异或
^:有结合律(a ^ (b ^ c) = (a ^ b) ^ c)和交换律(a ^ b = b ^ a),没有分配律
2、常用的异或结论:a ^ 0 = a,a ^ a = 0,在方程中常会用来消元或移项
3、加法结论:a + b = 2 * (a & b) + (a ^ b),因为a ^ b是无进位加法,a & b可以获取需要进位的位,2 * (a & b)等同于将需要进位的位左移一位。该结论常用于证明a + b >= a ^ b,因为在非负整数前提下a & b >= 0移位运算符
下面介绍 C 的移位运算符,移位运算符向左或向右移动位。示例中同样使用二进制数便于理解
左移运算符:
<<1、左移运算符将其左侧的运算对象每一位的值,向左移动指定位数
2、左侧运算对象移出左末尾端的值丢失,用0填补空缺位置
3、如表达式(10001010) << 2的结果为 00101000右移运算符:
>>1、右移运算符将其左侧的运算对象每一位的值,向右移动指定位数
2、左侧运算对象移出右末尾端的值丢失。对于无符号类型,用0填补空缺位置;对于有符号类型,结果取决于机器,空出的位置可用 0 填充,或者用符号位(即最左端的位)副本填充
3、如表达式(10001010) >> 2的结果可能为 00100010 或 11100010示例程序:数字转为二进制
#include <stdio.h> #include <limits.h> // 提供 CHAR_BIT 的定义,CHAR_BIT 表示 char 中的位数 // 整数转换为二进制字符串 char *itobs(int n, char *ps) { int i; int size = CHAR_BIT * sizeof(int); for (i = size - 1; i >= 0; i--, n >>= 1) ps[i] = (01 & n) + '0'; ps[size] = '\0'; // 添加空字符 } // 4位一组显示二进制字符串 void show_bstr(char *str) { int i = 0; while (str[i]) // 不是空字符串 { putchar(str[i]); // 每4位添加空格 if (++i % 4 == 0 && str[i]) putchar(' '); } } int main(void) { char bin_str[CHAR_BIT * sizeof(int) + 1]; // CHAR_BIT * sizeof(int) 表示 int 类型的位数,+1 留出一位给空字符 int number; puts("输入一个数字:"); while (scanf("%d", &number) == 1) { itobs(number, bin_str); printf("%d is ", number); show_bstr(bin_str); putchar('\n'); } return 0; }1、
itobs()函数中有对01 & n求值。01是一个八进制掩码,其只有0 号位为 1,因此01 & n就是n 最后一位的值(值为 1 或 0)
2、但对于数组而言,需要的是字符而不是数值,因此该值+ '0'(或加上对应 ASCII 码值 48)即可完成转换。其结果存放在数组倒数第二个元素中(size - 1)
3、然后,循环执行i--和n >>= 1,。i--移动到数组前一个元素,n>>=1使所有位右移 1。进入下一轮迭代,处理的是n中新的最右端的值,将其结果存储在倒数第三个元素中,以此类推示例程序:切换一个值的后 n 位
// 该函数可被上个示例调用 int invert_end(int num, int bits) { int mask = 0; int bitval = 1; while (bits-- > 0) { mask |= bitval; bitval <<= 1; } return num ^ mask; }1、
~运算符切换一个字节的所有位,而不是选定的少数位。但是^运算符可用于切换单个位
2、while循环用于创建所需的掩码 mask。起初,mask所有位都为 0,第一轮循环将mask的0 号位设置为1,第二轮将1 号位设置为1,以此类推
3、循环bits次,mask的后 bits 位就都被设置为 1。最后,num ^ mask运算即得所需结果
运算符常用用法
掩码
按位与运算符常用于掩码。所谓掩码指的是一些设置为开(1)或关(0)的位组合
掩码的认识与使用
1、假设定义符号常量MASK为2,其二进制为00000010,研究该语句:
flags = flags & MASK;
2、使用按位与运算符任何位与 0 组合都得 0,因此对该语句只有1 号位的值不变(因为 MASK 只有 1 号位为 1)。这个过程叫做使用掩码,因为掩码中的 0 隐藏了 flags 中相应的位
3、可以这样类比,把掩码中的0 看做不透明,1 看做透明。因此只有MASK 为 1 的位才可见
打开位(设置位)
有时,需要打开一个值的特定位,同时保持其他位不变。这种情况可以使用按位或运算符
打开位的使用
1、对于
flags = flags | MASK;语句,可以通过设置 MASK 的值来控制打开 flags 的特定位
2、因为使用|运算符,任何位与 0 组合,结果都为本身;任何位与 1 组合,结果都为 1
3、例如需要设置 flags 的1 和 3 号位为开(1),则可以设置MASK为10(二进制为 00001010),通过flags |= MASK;实现
关闭位(清空位)
和打开特定的位类似,有时也需要在不影响其他位的情况下关闭指定的位
关闭位的使用
1、对于
flags = flags & ~MASK;语句,可以通过设置 MASK 的值来控制关闭 flags 的特定位
2、因为使用&运算符,任何位与 1 组合,结果都为本身;任何位与 0 组合,结果都为 0
3、例如需要设置 flags 的1 和 3 号位为关(0),则可以设置MASK为10(二进制为 00001010),通过flags &= ~MASK;实现
4、根据个人喜好,也可以不使用~MASK而直接使用 MASK,这种表示方法便以 0 标记需要关闭的位,MASK应为11110101,语句为flags &= MASK;
切换位
切换位指的是打开已关闭的位,或关闭已打开的位。这种情况可以使用按位异或运算符
切换位的使用
1、对于
flags ^= MASK;语句,可以通过设置 MASK 的值来切换指定位的状态
2、因为使用^运算符,任何位与 1 组合,结果都会切换(1 变 0,0 变 1);任何位与 0 组合,结果都不变
3、例如需要切换 flags 的1 和 3 号位的状态(0),则可以设置MASK为10(二进制为 00001010),通过flags ^= MASK;实现
检查位的值
有时需要检查确认某位的值,例如flags 的 1 号位是否为 1,不能像下面这样直接比较(即使 flags 的 1 号位为 1,其他位也会导致结果为假)
if (flags == MASK) puts("Wow!"); // 不能正常工作必须先覆盖 flags 的其他位,只用 1 号位比较
int flags, MASK1, MASK0; // MASK1 用于比较flags 1号位是否为 1,MASK0 用于比较1号位是否为 0 flags = 0b1011; MASK1 = 0b0010; MASK0 = 0b1101; // 比较flags的 1号位是否为 1 if((flags & MASK1) == MASK1) // & 优先级比 == 低,所以需要括号 puts("Wow!"); // 比较flags的 1号位是否为 0 if((flags | MASK0) == MASK0) puts("Wow!");
乘除次幂
移位运算符针对2 的幂提供快速有效的乘除法(类似十进制移动小数点快速乘除 10)
number << n; // number 乘以 2 的 n次幂 number >> n; // number 为非负时,number 除以 2 的 n次幂
位字段
简介与声明
1、操控位的第二种方法是位字段。位字段是一个signed int或unsigned int类型变量中的一组相邻的位
2、位字段通过一个结构声明来建立,该结构声明为每个字段提供标签,并确定该字段的宽度
3、随后,可通过普通的结构成员运算符.单独给这些字段赋值
4、由于每个字段恰好为 1 位,所以只能赋值 1 或 0。结构变量被存储在int 大小的内存单元中,但是在本例中只使用了其中 4 位// 建立一个 4个 1位 的字段: struct { unsigned int autfd : 1; unsigned int bldfc : 1; unsigned int undln : 1; unsigned int itals : 1; } prnt; // 为字段单独赋值: prnt.itals = 0; prnt.undln = 1;位字段的使用
带有位字段的结构提供一种记录设置的方便途径。许多设置(如字体的粗体或斜体)就是简单的二选一,例如开或关、真或假等。如果只需要使用 1 位,就不需要使用整个变量
有时,某些设置也有多个选择,因此需要多位来表示。这没问题,字段不限制 1 位大小,可以使用如下的示例。只是,要确保赋值不超过字段可容纳范围
// 创建 2个 2位 的字段和 1个 8位 的字段: struct { unsigned int code1 : 2; // 2位 为 2位二进制,即可表示 2^2 个数,范围为 0~3 unsigned int code2 : 2; unsigned int code3 : 8; } prcode; // 赋值: prcode.code1 = 0; prcode.code2 = 3; prcode.code3 = 102;
位字段越界问题
1、如果声明的总位数超过了一个 unsigned int 类型的大小,会用到下一个 unsigned int 类型的存储位置
2、一个字段不允许跨越两个unsigned int之间的边界。编译器会自动移动跨界的字段,保持unsigned int的边界对齐
3、一旦发生这种情况,第一个 unsigned int中会留下一个未命名的“洞”。可以使用未命名的字段宽度来填充未命名的洞;可以使用一个宽度为 0 的未命名字段迫使下一个字段与下一个整数对齐
4、示例中,stuff.field1和stuff.field2之间,有一个2 位的空隙;stuff.field3将存储在下一个 unsigned int 中
5、字段存储在一个 int 中的顺序取决于机器。另外,不同的机器中两个字段边界的位置也有区别。由于这些原因,位字段通常都不容易移植struct { unsigned int field1 : 1; unsigned int : 2; unsigned int field2 : 1; unsigned int : 0; unsigned int field3 : 1; } stuff;位字段示例
打印方框属性
1、在屏幕上表示一个方框的属性。为简化问题,假设方框具有如下几种属性
2、方框是透明或不透明的
3、填充色:黑、红、绿、黄、蓝、紫、青、白
4、边框可见或隐藏
5、边框颜色:与填充色相同的可能
6、边框使用实线、点线或虚线示例程序
#include <stdio.h> #include <stdbool.h> /* 线的样式 */ #define SOLID 0 #define DOTTED 1 #define DASHED 2 /* 三原色 */ #define BLUE 4 #define GREEN 2 #define RED 1 /* 混合色 */ #define BLACK 0 #define YELLOW (RED | GREEN) #define MAGENTA (RED | BLUE) #define CYAN (BLUE | GREEN) #define WHITE (RED | GREEN | BLUE) // 定义颜色的字符串 const char *colors[8] = {"black", "red", "green", "yellow", "blue", "magenta", "cyan", "white"}; // 定义位字段 struct box_props { bool opaque : 1; // 1 为透明,0 为不透明 unsigned int fill_color : 3; // 左侧位表示蓝色,中间位绿色,右侧位红色,通过三原色调色表示其他色 unsigned int : 4; // 填充位 bool show_border : 1; // 1 为可见,0 为不可见 unsigned int border_color : 3; // 同 fill_color unsigned int border_style : 2; // 0、1、2分别表示实线、点线、虚线 unsigned int : 2; // 填充位 }; // 显示设置的函数 void show_setting(struct box_props *pb) { printf("Box is %s.\n", pb->opaque == true ? "opaque" : "transparent"); printf("The fill color is %s.\n", colors[pb->fill_color]); printf("Border %s.\n", pb->show_border == true ? "shown" : "not shown"); printf("The border color is %s.\n", colors[pb->border_color]); printf("The border style is "); switch (pb->border_style) { case SOLID: printf("solid.\n"); break; case DOTTED: printf("dotted.\n"); break; case DASHED: printf("dashed.\n"); break; default: printf("unknown.\n"); } } int main(void) { /* 创建并初始化 box_props 结构 */ struct box_props box = {true, YELLOW, true, GREEN, DASHED}; printf("Original box settings:\n"); show_setting(&box); box.opaque = false; box.fill_color = WHITE; box.border_color = MAGENTA; box.border_style = SOLID; printf("\nModified box settings:\n"); show_setting(&box); return 0; }
对齐特性
对齐特性介绍
1、C11的对齐特性比用位填充字节更自然,它们还代表 C 在处理硬件相关问题上的能力。在这种上下文中,对齐指的是如何安排对象在内存中的位置
2、例如,为了效率最大化,系统可能要把一个double 类型值存储在4 字节内存地址上,但却允许把char存储在任意地址
3、大多数程序员都对对齐不以为然,但是,有些情况又受益于对齐控制。例如把数据从一个硬件位置转移到另一个位置,或者调用指令同时操作多个数据项_Alignof 运算符
1、
_Alignof运算符给出一个类型的对齐要求,在关键字_Alignof后面的圆括号写上类型名即可:size_t d_align = _Alignof(float);
2、假设d_align的值是 4,意思是float 类型对象的对齐要求是 4。也就是说,4是存储该类型值相邻地址的字节数
3、一般而言,对齐值都应该是2 的非负整数次幂。较大的对齐值被称为stricter或stronger,较小的对齐值被称为weaker_Alignas 说明符
1、
_Alignas说明符指定一个变量或一个类型的对齐值。但是,不应该要求该值小于基本对齐值
2、例如,如果float 类型的基本对齐值是 4,就不该请求其对齐值为1 或 2
3、该说明符用作声明的一部分,说明符后面的圆括号内包含对齐值的类型:_Alignas(double) char c1;、_Alignas(8) char c2;、char _Alignas(double) c_arr[sizeof(double)];
4、注意,Clang 3.2 版本要求_Alignas(type)说明符在类型说明符后面,如上第三个示例。但后来Clang 3.3 版本也支持了前两种在后的顺序,GCC 4.7.3 版本也能识别这两种顺序使用示例
#include <stdio.h> int main(void) { double dx; char ca; char cx; double dz; char cb; char _Alignas(double) cz; // 设置变量 cz 的对齐值为double类型的对齐值 printf("char alignment: %zd\n", _Alignof(char)); // 利用_Alignof()获取char类型对齐值 printf("double alignment: %zd\n", _Alignof(double)); // 利用_Alignof()获取double类型对齐值 printf("cz alignment: %zd\n", _Alignof(cz)); // 利用_Alignof()获取cz类型对齐值 printf("&dx: %p\n", &dx); printf("&ca: %p\n", &ca); printf("&cx: %p\n", &cx); printf("&dz: %p\n", &dz); printf("&cb: %p\n", &cb); printf("&cz: %p\n", &cz); return 0; }char alignment: 1 double alignment: 8 cz alignment: 8 &dx: 000000000061FE18 &ca: 000000000061FE17 &cx: 000000000061FE16 &dz: 000000000061FE08 &cb: 000000000061FE07 &cz: 000000000061FE00
C 预处理器和 C 库
章节概要:翻译程序的第一步;明示常量:
#define;明示常量简介;记号;重定义常量;在#define中使用参数;用宏参数创建字符串:#运算符;预处理器粘合剂:##运算符;变参宏:...和__VA_ARGS__;文件包含:#include;使用头文件;头文件常用形式;头文件的使用价值;其他指令;#undef指令;从 C 预处理器角度看已定义;条件编译;预定义宏;#line和#error;#pragma;泛型选择_Generic;函数说明符;内联函数inline;_Noreturn说明符;C 库;数学库math.h;类型变体;tgmath.h库;通用工具库stdlib.h;断言库assert.h;字符串库string.h;可变参数库stdarg.h
翻译程序的第一步
在预处理之前,编译器必须对该程序进行一些翻译处理
1、首先,编译器把源代码中出现的字符映射到源字符集。该过程处理多字节字符和三字符序列——字符拓展让 C 更加国际化
2、编译器定位每个反斜杠后面跟着换行符的实例(注意此处的换行符指的是按下Enter在源代码中换行产生的字符,而不是符号表征\n),并删除它们。也就是说,将后面示例中的多个物理行转换成一个逻辑行
3、编译器把文本划分成预处理记号序列、空白序列和注释序列(记号是由空格、制表符或换行符分隔的项)。这里要注意的是,编译器将用空格替换每一条注释
4、最后,程序已经准备好进入预处理阶段,预处理器查找一行中以#开始的预处理指令// 多个物理行 printf("That's wond\ erful!\n"); // 将被替换为一个逻辑行 printf("That's wonderful!\n"); // 源码中的注释 int/*这是一条注释*/fox; // 将被替换为空格 int fox;
明示常量:#define
#define预处理器指令和其他预处理器指令一样,以#作为一行的开始。之前我们大量使用#define指令来定义明示常量(符号常量),但该指令还有许多其他用途明示常量简介
1、
#define指令可以出现在源文件的任何地方,其定义从指令出现处到文件末尾有效
2、预处理器指令从#开始运行,到后面的第一个换行符为止。也就是说,指令的长度仅限一行(然而,预处理开始前,编译器会把多个物理行处理为一行逻辑行,所以可以使用\换行)
3、每行#define都由三部分组成。第一部分是#define指令本身;第二部分是选定的缩写,也称为宏;第三部分称为替换列表或替换体
4、有些宏代表值,这些宏被称为类对象宏,C 语言还有类函数宏,稍后讨论。宏的名称中不允许有空格,且必须遵循 C 变量命名规则
5、一旦预处理器在程序中找到宏的实例后,就会用替换体代替该宏(也有例外)。从宏变成最终替换文本的过程称为宏展开简单示例
#include <stdio.h> #define TWO 2 // 反斜杠利用预处理前的翻译处理规则,把定义延续到下一行 #define OW "Consistency is the last refuge of the unimagina\ tive. - Oscar Wilde\n" #define FOUR TWO*TWO #define PX printf("X is %d.\n", x); #define FMT "X is %d.\n" int main(void) { int x = TWO; // 调用类函数宏 PX PX; x = FOUR; // 调用 FMT 字符串 printf(FMT, x); printf("%s", OW); // 字符串内并不会调用宏,仅为正常字符 printf("TWO: OW\n"); return 0; }X is 2. X is 4. Consistency is the last refuge of the unimaginative. - Oscar Wilde TWO: OW记号
1、从技术角度看,可以把宏的替换体看做是记号型字符串,而不是字符型字符串
2、C预处理器记号是宏定义的替换体中单独的词,用空白把这些词分开
3、例如#define FOUR 2*2中,该宏定义有一个记号,即2*2;在#define SIX 2 * 3中,则有三个记号,即2、*、3
4、如果预处理器把该替换体解释为字符型字符串,则用2 * 3替换SIX,即额外的空格是替换体的一部分。如果将其解释为记号型字符串,则用3 个的记号2、*、3(将原先空格视为各记号的分隔符)来替换SIX
5、实际应用中,也有一些 C 编译器把宏替换体视为字符串而不是记号。只有在更复杂的情况下,二者的区别才有实际意义重定义常量
1、假设先把 LIMIT 定义为 20,稍后在该文件中又把它定义为 25,这个过程称为重定义常量
2、不同的实现采用不同的重定义方案,除非新定义与旧定义相同,否则可能将其视为错误。另外一些实现允许重定义,但会给出警告
3、ANSI标准采用第一种方案,即新旧定义完全相同才允许重定义。此处的相同指相同的记号,如#define FOUR 2*2与#define FOUR 2 * 2并不相同
4、如果需要重定义宏,可以使用#undef指令(稍后介绍)
在 #define 中使用参数
简介概述
1、在
#define中使用参数可以创建外形和作用与函数类似的类函数宏
2、带有参数的宏看起来很像函数,因为这样的宏也使用圆括号
3、类函数宏定义的圆括号内可以有一个或多个参数,随后这些参数出现在替换体中示例程序
#include <stdio.h> #define SQUARE(X) X *X int main(void) { int x = 5; int z; printf("x = %d\n", x); z = SQUARE(x); printf("SQUARE(x): %d\n", z); z = SQUARE(2); printf("SQUARE(x): %d\n", z); z = SQUARE(x + 2); printf("SQUARE(x + 2): %d\n", z); z = SQUARE(++x); printf("SQUARE(++x): %d\n", z); return 0; }x = 5 SQUARE(x): 25 SQUARE(x): 4 SQUARE(x + 2): 17 SQUARE(++x): 421、前两行的结果与预期相符,但第三行的
SQUARE(x + 2)的结果为17,你可能认为其结果是7*7 = 49。实际原因是,预处理器不做计算、不求值,只替换字符序列
2、因此预处理器把出现 x 的地方都替换为 x+2,即SQUARE(x + 2)表达式的值为 5+2*5+2 = 17。要解决这个问题,需要将宏定义改为#define SQUARE(x) (x)*(x),这样表达式的值为(5+2)*(5+2) = 49。因此,使用足够多的括号可以确保运算和结合的正确顺序
3、尽管如此,还是无法避免最后一种情况,SQUARE(++x)变成了++x*++x,递增了两次 x。此处运算为6*7 = 42,有些编译器会在乘法运算之前完成第二次递增,结果可能为7*7 = 49。但无论哪种解释,结果都不是我们想要的6*6 = 36,因此应避免用++x等递增递减运算符作为宏参数用宏参数创建字符串:#运算符
引入
1、有
#define PSQR(X) printf("the square of X is %d", ((X) * (X)));的宏定义
2、假设这样使用宏:PSQR(8),输出为the square of X is 64
3、此时双引号字符串内的X被视为普通文本,而不是一个可被替换的记号#运算符1、C 允许在字符串中包含宏参数。在类函数宏的替换体中,
#作为一个预处理运算符,可以把记号转换成字符串
2、例如如果X是一个宏形参,那么#X就是转换为字符串 X 的形参名。这个过程称为字符串化
3、例如有#define PSQR(X) printf("the square of " #X " is %d", ((X) * (X)));的定义
4、此时定义y=5,PSQR(y);的输出为the square of y is 25;PSQR(2 + 4);的输出为the square of 2 + 4 is 36
预处理器粘合剂:##运算符
1、与
#类似,##运算符可以用于类函数宏的替换部分。而且,##还可用于类对象宏的替换部分
2、##把两个记号组合成一个记号。例如有#define XNAME(N) x ## N的定义
3、此时XNAME(y)将展开为xy;XNAME(4)将展开为x4变参宏:…和__VA_ARGS__
1、一些函数(如
printf())接受数量可变的参数。stdvar.h头文件提供了工具(稍后介绍),让用户自定义带可变参数的函数
2、C99/C11也对宏提供了这样的工具,通过把宏参数列表中最后的参数写成...来实现这一功能。这样,预定义宏__VA_ARGS__可用在替换部分中,表明省略号代表什么
3、例如有#define PR(X, ...) printf("Message " #X ":" __VA_ARGS__)的定义
4、此时PR(1, "hello");的输出为Message 1: hello;PR(2)的输出为Message 2:
文件包含:#include
简介概述
1、当预处理器发现
#include指令时,会查看后面的文件名,并把文件的内容包含到当前文件中(即替换源文件中的#include指令)
2、#include有两种形式:#include <stdio.h>和#include "mystuff.h",即尖括号和双引号
3、尖括号告诉预处理器在标准系统目录中查找文件,双引号告诉预处理器首先在当前目录中查找,后查找标准系统目录
4、集成开发环境(IDE)也有标准路径或系统头文件的路径。许多IDE提供菜单选项,指定用尖括号时的查找路径。使用双引号时有些编译器会搜索源代码文件所在目录,有的会搜索当前工作目录,有的会搜索项目文件所在目录
5、ANSI C不为文件提供统一的目录模型,因为不同计算机所用系统不同。一般而言,命名文件的方法因系统而异,但是尖括号和双引号的规则与系统无关
6、C 语言习惯用.h后缀表示头文件,这些文件包含需要放在程序顶部的信息。头文件经常包含一些预处理器指令
7、包含一个大型头文件不一定显著增加程序大小。在大部分情况下,头文件的内容是编译器生成最终代码时所需要的信息,而不是添加到最终代码中的材料使用头文件
浏览任何一个标准头文件都可以了解头文件的基本信息,头文件中最常用的形式如下
头文件常用形式
1、明示常量:例如头文件
stdio.h中定义的EOF、NULL和BUFSIZE(标准 I/O 缓冲区大小)
2、宏函数:例如getchar()通常用getc(stdin)定义,而getc()经常用于定义较复杂的宏,头文件ctype.h通常包含ctype 系列函数的宏定义
3、函数声明:例如头文件string.h,包含字符串系列函数的函数声明
4、结构模板定义:标准 I/O 函数使用FILE 结构,该结构中包含了文件和文件缓冲区相关的信息。FILE 结构在头文件stdio.h中
5、类型定义:标准 I/O 函数使用指向 FILE 的指针作为参数。通常,头文件stdio.h用#define或typedef把FILE定义为指向结构的指针。类似的,size_t和time_t定义在头文件中头文件的使用价值
1、许多程序员都在程序中使用自己开发的标准头文件。如果开发一系列相关的函数或结构,那么这种方法特别有价值
2、另外,还可以使用头文件声明外部变量供其他文件共享。在源代码中定义一个文件作用域的外部链接变量int a = 0;,然后在与之关联的头文件中进行引用式声明extern int a;,这样这行代码便会出现在包含了该头文件的其实文件中
3、需要包含头文件的另一种情况是,使用具有文件作用域、内部链接和const限定符的变量或数组。const防止值被意外修改,内部链接static意味着每个包含该头文件的文件都获得一份副本。因此不需要在一个文件中进行定义式声明,在其他文件中进行引用式声明
其他指令
#undef 指令
1、
#undef指令用于取消已定义的#define指令
2、也就是说,假如有#define LIMIT 400,可以通过#undef LIMIT移除上面的定义。现在就可以把LIMIT重新定义为一个新值
3、如果想使用一个名称,又不确定之前是否已经使用过,为安全起见,可以先用#undef取消定义从 C 预处理器角度看已定义
#define LIMIT 1000 // LIMIT是已定义的 #define GOOD // GOOD是已定义的 #define A(X) ((-(X))*(X)) // A是已定义的 int q; // q不是宏,因此是未定义的 #undef GOOD // GOOD取消定义,是未定义的1、预处理器在识别标识符时,遵循与 C 相同的规则(标识符的命名规则)
2、当预处理器在预处理器指令中发现一个标识符时,会将该标识符当做已定义的或未定义的。
3、这里的已定义表示由预处理器定义。如果标识符是同一个文件中由前面的#define创建的一个宏名,而且没有用#undef关闭,那么该标识符是已定义的
4、如果标识符不是宏,假设是一个文件作用域的C 变量,那么该标识符对预处理器而言就是未定义的条件编译
可以使用其他指令创建条件编译。也就是说,可以使用这些指令告诉编译器根据编译时的条件而执行或忽略信息(或代码)块
#ifdef、#else、#endif指令// 使用语法 #ifdef MAVIS // 如果已经用 #define 定义了 MAVIS,则执行下面的指令 #include "horse.h" #define STABLES 5 #else // 如果没有用 #define 定义 MAVIS,则执行下面的指令 #include "cow.h" #define STABLES 15 #endif // 实际使用示例 #define JUST_CHECKING 1 int total = 0; for(int i = 1; i <= LIMIT; i++) { total += 2 * i*i + 1; #ifdef JUST_CHECKING printf("i=%d total=%d\n", i, total); #endif }1、这里使用的较新的编译器和 ANSI 标准支持的缩进格式。如果使用旧的编译器,则必须左对齐所有指令或至少左对齐
#号
2、#ifdef指令说明,如果预处理器已定义了后面的标识符,则执行#else或#endif指令之前的所有指令
3、如果预处理器未定义后面的标识符,且有#else指令,则执行#else和#endif之间的所有代码#ifndef指令1、
#ifndef指令与#ifdef指令用法类似,也可以和#else、#ifdef一起使用,但他们的逻辑相反
2、#ifndef判断后面的标识符是否是未定义的,常用于定义之前未定义的常量#if和#elif指令1、
#if指令很像C 语言的if,后面跟整型常量表达式,如果表达式为非零,则表达式为真。同样#elif也很像C 语言的else if
2、较新的编译器提供另一种方法测试名称是否已定义,即用#if defined (VAX)代替#ifdef VAX
3、这里的defined是一个预处理运算符,如果它的参数用#defined定义过,则返回 1,否则返回 0。这种方法的好处是可以和#elif一起使用
预定义宏
C 规定了一些预定义宏,如下表:
宏 含义 __DATE__ 预处理的日期(Mmm dd yyyy 形式的字符串字面量,如 Nov 23 2013) __FILE__ 表达当前源代码文件名的字符串字面量 __LINE__ 表示当前源代码文件中行号的整型常量 __STDC__ 设置为 1 时,表明实现遵循 C 标准 __STDC_HOSTED__ 本机环境设置为 1,否则设置为 0 __STDC_VERSION__ 支持 C99 标准,设置为 199901L;支持 C11 标准,设置为 201112L __TIME__ 翻译代码的时间,格式为 hh:mm:ss C99提供
__func__的预定义标识符,它展开为一个代表函数名的字符串(该函数包含该标识符)。那么,__func__必须具有函数作用域而不是文件作用域,因此__func__是预定义标识符而不是预定义宏
#line 和 #error
#line指令重置__LINE__和__FILE__宏报告的行号和文件名,可以这样使用:#line 1000 // 把当前行号重置为 1000 #line 10 "cool.c" // 把当前行号重置为 10,文件名重置为 cool.c#error指令让预处理器发出一条错误信息,该消息包含指令中的文本。如果可能的话,编译过程应该中断,可以这样使用:#if __STDC_VERSION__ != 201112L #error Not C11 #endif
#pragma
1、在现在的编译器中,可以通过命令行参数或IDE 菜单修改编译器的一些设置。
#pragma把编译器指令放入源代码中
2、例如在开发C99时,标准被称为C9X,可以使用下面的编译指示让编译器支持C9X:#pragma c9x on
3、一般而言,编译器都有自己的编译指示集。例如,编译指示可能用于控制分配给自动变量的内存量,或者设置错误检查的严格程度,或者启用非标准语言特性等
4、C99还提供_Pragma预处理器运算符,该运算符把字符串转换成普通的编译指示。该运算符不使用#符号,所以可以把它作为宏展开的一部分
5、例如_Pragma("nonstandardtreatmenttypeB on")等价于#pragma nonstandardtreatmenttypeB on泛型选择 _Generic
引入
1、在程序设计中,泛型编程指那些没有特定类型,但是一旦指定一种类型,就可以转换成指定类型的代码
2、例如在C++模板中可以创建泛型算法,然后编译器根据指定的类型自动使用实例化代码
3、但是 C 没有这种功能。然而C11新增了一种表达式,叫做泛型选择表达式,可根据表达式的类型选择一个值
4、泛型选择表达式不是预处理器指令,但是在一些泛型编程中它常作#define宏定义的一部分_Generic1、这是一个泛型选择表达式的示例:
_Generic(x, int:0, float:1, double:2, default:3)
2、_Generic是C11的关键字,后面的圆括号中包含多个用逗号分隔的项。第一个项是一个表达式,后面的每个项都由一个类型、一个冒号和一个值组成
3、第一个项的类型匹配哪个标签,整个表达式的值就是该标签后的值。如上面例子的x为int 类型,则值为int:后的值(即 0),如果没有类型匹配的标签,表达式的值就是default:后的值
4、泛型选择语句与switch语句类似,只是前者用表达式的类型匹配标签,后者用表达式的值匹配标签
5、下面是一个把泛型选择语句与宏定义组合的例子:/* 使用 \符号 把一条逻辑行分为多条物理行 */ #define MYTYPE(X) _Generic((X),\ int: "int",\ float: "float",\ double: "double",\ default: "other"\ )
函数说明符
内联函数简介
1、通常,函数调用都有一定的开销,因为函数的调用过程包含建立调用、传递参数、跳转到函数代码返回
2、使用宏使代码内联,可以避免这样的开销。C99还提供另一种方法:内联函数
3、C99标准中对其的叙述是:把函数变成内联函数意味着尽可能快地调用该函数,其具体效果由实现定义。因此把函数变成内联函数,编译器可能会用内联代码替换函数调用,并执行一些其他的优化,也可能不起作用创建内联函数
#include <stdio.h> inline static void eatline() // 内联函数定义/原型 { while(getchar() != '\n') continue; }1、创建内联函数的定义有多种方法,标准规定一个具有内部链接的函数可以成为内联函数,还规定内联函数的定义与调用该函数的代码必须在同一文件
2、因此,最简单的办法是使用函数说明符inline和存储类别说明符static来创建内联函数
3、由于并未给内联函数预留单独的代码块,所以无法获得内联函数的地址(实际上可以获得,不过这样做之后,编译器会生成一个非内联函数)。另外,内联函数无法在调试器中显示
4、内联函数应该比较短小,较长的函数变成内联并为节约多少时间,因为执行函数体的时间比调用函数的时间长得多_Noreturn 函数
1、C99新增
inline关键字时,它是唯一的函数说明符。后来C11新增了第二个函数说明符_Noreturn
2、_Noreturn表明调用完成后函数不返回主函数。exit()函数是_Noreturn函数的一个示例,一旦调用exit(),它便不会再返回主调函数
3、_Noreturn的目的是告诉用户和编译器,这个特殊的函数不会把控制返回主调程序。告诉用户避免滥用该函数,通知编译器可优化这些代码
C 库
最初,并没有官方的 C 库。后来基于 UNIX 的 C 实现成为了标准,ANSI C委员会主要以这个标准为基础,开发了一个官方的标准库。在意识到 C 语言应用范围扩大后,委员会重新定义了这个库,使之可以应用于其他系统
数学库 math.h
函数原型 描述(1 弧度 = 180/π = 57.296°) double acos(double x) 返回余弦值为 x 的角度(0 ~ π 弧度) double asin(double x) 返回正弦值为 x 的角度(-π/2 ~ π/2 弧度) double atan(double x) 返回正切值为 x 的角度(-π/2 ~ π/2 弧度) double atan2(double y, double x) 返回正切值为 y/x 的角度(-π/2 ~ π/2 弧度) double cos(double x) 返回 x 的余弦值,x 的单位为弧度 double sin(double x) 返回 x 的正弦值,x 的单位为弧度 double tan(double x) 返回 x 的正切值,x 的单位为弧度 double exp(double x) 返回 x 的指数函数的值 double log(double x) 返回 x 的自然对数值 double log10(double x) 返回 x 的以 10 为底的对数值 double pow(double x, double y) 返回 x 的 y 次幂 double sqrt(double x) 返回二次根下 x 的值 double cbrt(double x) 返回三次根下 x 的值 double ceil(double x) 返回不小于 x 的最小整数值 double fabs(double x) 返回 x 的绝对值 double floor(double x) 返回不大于 x 的最大整数值 类型变体
1、基本的浮点型数学函数接受double 类型的参数,并返回 double 类型的值。当然,也可以把float或long double参数传递给这些函数,它们也能正常工作
2、这样做很方便,但不是最好的处理方式。例如如果不需要双精度,float单精度速度会更快;long double 类型的值传给double可能会损失精度,值可能不是原来的值
3、C 标准专门为float和long double提供了标准函数,即原函数名后加上f或l后缀。因此sqrtf()是sqrt()的float 版本,sqrtl()是sqrt()的long double 版本
4、可以利用C11新增的泛型选择表达式定义一个泛型宏,根据参数类型选择合适的数学函数版本,如下:#include <stdio.h> #include <math.h> // 主体为 _Generic(X) (X),注意分辨,_Generic部分用于选择版本(即函数名),与后面的(X)拼接形成函数 #define SQRT(X) _Generic((X),\ long double: sqrtl,\ float: sqrtf,\ default: sqrt)(X) // 这样定义,在调用时只需要调用 SQRT(X) 就可以自动选择最合适的版本tgmath.h 库
1、C99提供的
tgmath.h头文件中定义了泛型类型宏,其效果与上面类型变体的程序示例类似
2、tgmath.h创建一个泛型类型宏,与原来 double 版本的函数名同名。其会根据参数类型自动选择展开对应版本
3、complex.h中声明了与复数运算相关的函数,例如csqrtf()、csqrt()、csqrtl(),也分别对应不同版本。如果提供这些支持,tgmath.h中的sqrt()宏也能展开为相应的复数平方根函数
4、如果包含tgmath.h,要调用sqrt()函数而不是sqrt()宏,可以把被调用的函数名括起来:(sqrt)(x)通用工具库 stdlib.h
exit()和atexit()函数引入
1、在前面的章节已经使用过
exit()函数。而且,在main()返回系统时将自动调用exit()
2、ANSI 标准还新增了一些不错的功能,注重最重要的是可以指定在执行exit()时调用的特定函数
3、atexit()通过注册要在退出时调用的函数来提供这一特性,atexit()函数接受一个函数指针作为参数atexit()的用法1、函数使用函数指针。要使用
atexit()函数,只需把退出时要调用的函数地址传递给atexit()即可(函数名作为函数参数时相当于函数地址)
2、传入参数后,atexit()注册函数列表中的函数,当调用exit()时就会执行这些函数。ANSI保证,在这个列表中至少可以放 32 个函数
3、最后调用exit()时,exit()会执行这些函数。执行顺序与列表中函数顺序相反,即最后添加的函数最先执行
4、atexit()注册的函数应该不带任何参数且返回类型为 void。通常这些函数会执行一些清理任务,如更新监视程序的文件或重置环境变量程序示例
#include <stdio.h> #include <stdlib.h> void sign_off(void) { puts("Thus terminates another magnificent program from"); puts("Seesaw Software"); } void too_bad(void) { puts("Seesaw Software extends its heartfelt condolences"); puts("to you upon the failure of your program"); } int main(void) { int n; atexit(sign_off); // 注册 sign_off 函数 puts("Enter an integer:"); if (scanf("%d", &n) != 1) { puts("That's no integer!"); atexit(too_bad); // 注册 too_bad 函数 exit(EXIT_FAILURE); } printf("%d is %s\n", n, (n % 2 == 0) ? "even" : "odd"); return 0; }Enter an integer: 212 212 is even Thus terminates another magnificent program from Seesaw SoftwareEnter an integer: a That's no integer! Seesaw Software extends its heartfelt condolences to you upon the failure of your program Thus terminates another magnificent program from Seesaw Software
qsort()函数qsort()的用法1、对较大型的数组而言,快速排序算法是最有效的排序算法之一。快速排序算法在 C 实现的名称是
qsort()
2、qsort()函数排序数组的数据对象,其原型为void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
3、第一个参数是指针,指向待排序数组的首元素(void 类型指针,可以引入任何类型数组)
4、第二个参数是待排序项的数量。函数原型将该值转换为 size_t 类型
5、第三个参数是待排序数组每个元素的大小(由于第一个参数转换为 void 指针,所以函数不知道每个元素的大小,因此需要补偿该信息)
6、第四个参数是一个指向函数的指针,指向一个自定义的比较函数,用于确定排序的顺序
7、自定义的比较函数应接受两个参数,分别指向待比较两项的指针。返回值为int 类型,返回正数则告知qsort()交换,相等返回 0,返回负数则不操作(见示例程序)程序示例
/* 程序自动随机生成一组浮点数数组,并排序 */ #include <stdio.h> #include <stdlib.h> #define NUM 40 // 数组元素数 // 随机生成数组 void fillarray(double ar[], int n) { for (int index = 1; index < n; index++) ar[index] = (double)rand() / ((double)rand() + 0.1); } // 打印数组 void showarray(double ar[], int n) { int index; for (index = 0; index < n; index++) { printf("%9.4f ", ar[index]); if (index % 6 == 5) putchar('\n'); } if (index % 6 != 0) putchar('\n'); } // 自定义排序函数,按从小到大排序 int mycomp(const void *p1, const void *p2) { // 要使用指向对应类型(double)的指针来访问这两个值 const double *a1 = (const double *)p1; const double *a2 = (const double *)p2; // 如果此处符号改为 > ,则从大到小排序 if (*a1 < *a2) return -1; else if (*a1 == *a2) return 0; else return 1; } int main(void) { double vals[NUM]; fillarray(vals, NUM); puts("Random list:"); showarray(vals, NUM); qsort(vals, NUM, sizeof(double), mycomp); puts("\nSorted list:"); showarray(vals, NUM); return 0; }Random list: 0.0000 0.0022 0.2390 1.2191 0.3910 1.1021 0.2027 1.3835 20.2830 0.2508 0.8880 2.2179 25.4866 0.0236 0.9308 0.9911 0.2507 1.2802 0.0939 0.9760 1.7217 1.2054 1.0326 3.7892 1.9635 4.1137 0.9241 0.9971 1.5582 0.8955 35.3798 4.0579 12.0460 0.0096 1.0109 0.8506 1.1529 2.3614 1.5876 0.4825 Sorted list: 0.0000 0.0022 0.0096 0.0236 0.0939 0.2027 0.2390 0.2507 0.2508 0.3910 0.4825 0.8506 0.8880 0.8955 0.9241 0.9308 0.9760 0.9911 0.9971 1.0109 1.0326 1.1021 1.1529 1.2054 1.2191 1.2802 1.3835 1.5582 1.5876 1.7217 1.9635 2.2179 2.3614 3.7892 4.0579 4.1137 12.0460 20.2830 25.4866 35.3798
断言库 assert.h
assert()宏1、
assert.h断言库是一个辅助调试程序的小型库
2、assert()宏接受一个整形表达式作为参数。如果表达式求值为假,assert()则在标准错误流(stderr)中写入一条错误信息,并调用abort()函数(定义在stdlib.h)终止程序
3、assert()是为了标识出程序中某些条件为真的关键位置,如果为假则终止程序。终止程序后会显示失败的测试、包含测试的文件名和行号
4、使用assert()有几个好处:它不仅能自动标识文件和出问题的行号,还能无需更改代码做到自动开启或关闭
5、如果认为已经排除了 bug,可以把#define NDEBUG宏写在#include <assert.h>前面,重新编译后就会禁用所有assert()语句_Static_assert宏1、
assert()是在运行时进行检查。C11新增的_Static_assert()可以在编译时检查
2、因此,assert()会导致运行中的程序终止,而_Static_assert()会导致程序无法通过编译
3、_Static_assert()接受两个参数:第一个是整型常量表达式,第二个是一个字符串
4、如果第一个表达式求值为假,编译器会显示字符串并且不编译程序
5、使用示例:_Static_assert(CHAR_BIT == 16, "16-bit char falsely assumed")(包含limits.h)
字符串库 string.h
引入
1、不能把一个数组赋给另一个数组,所以要通过循环把数组中的每个元素赋给另一个数组相应的元素
2、有一个例外的情况:使用strcpy()和strncpy()函数来处理字符数组。此外memcpy()和memmove()函数提供类似的方法处理任何类型的数组memcpy()与memmove()1、两个函数的原型:
void *memcpy(void *restrict s1, const void *restrict s2, size_t n);与void memmove(void *s1, const void *s2, size_t n);
2、这两个函数都从s2指向的位置拷贝 n 字节到s1指向的位置,且都返回 s1 的值
3、memcpy()的参数带关键字restrict,即其假设两个内存区域之间没有重叠;而memmove()不做这样的假设,所以拷贝过程类似先把所有字节拷贝到一个临时缓存区,再拷贝到最终目的地
4、如果使用memcpy()时两区域出现重叠,该行为是未定义的。这意味着函数可能正常工作,也可能失败
5、由于函数被设计用于任何数据类型,所以使用指向 void 的指针。因此,第三个参数的字节数应指明待拷贝字节数,如10 * sizeof(double)
可变参数库 stdarg.h
本章前面提到过变参宏,而
stdarg.h头文件为函数提供了一个类似的功能,但用法较为复杂,必须按如下步骤进行:1、提供一个使用省略号的函数原型
2、在函数定义中创建一个va_list类型的变量
3、用宏把该变量初始化为一个参数列表
4、用宏访问参数列表
5、用宏完成清理工作提供一个使用省略号的函数原型
void f1(int n, ...); // 有效 int f2(const char *s, int k, ...); // 有效 char f3(char c1, ..., char c2); // 无效,省略号不在最后 double f4(...); // 无效,没有形参 /*---------------------------------------------------------*/ f1(2, 200, 400); // 2表示省略号部分接受 2个额外参数 f1(4, 13, 117, 18, 23) // 4表示省略号部分接受 4个额外参数1、这种函数原型应该有一个形参列表,其中至少有一个形参和一个省略号(省略号应在最右侧)
2、最右边的形参(即省略号左边的形参)有着特殊的作用,标准用parmN这个术语来描述该形参(f1()中 parmN 为 n,f2()中 parmN 为 k)
3、传递给parmN 形参的实际参数是省略号部分代表的参数数量,如示例中的调用创建一个 va_list 类型变量并初始化参数列表
double sum(int lim, ...) { va_list ap; // 声明一个存储参数的对象 va_start(ap, lim); // 把 ap 初始化为参数列表 /* 后续代码 */ }1、声明在
stdarg.h中的va_list类型代表一种用于存储形参对应的形参列表中省略号部分的数据对象
2、变参函数的定义起始部分类似上述示例,该例中lim是parmN 形参,表明变参列表中参数数量
3、然后使用va_start()宏,将参数列表拷贝到va_list变量中。宏接受两个参数:va_list变量和parmN 形参。如该例为va_start(ap, lim);访问参数列表内容与清理工作
1、访问参数列表的内容涉及到另一个宏
va_arg()。其接受两个参数:va_list变量和一个类型名
2、表示类型的参数指定返回的类型,注意要与传入参数类型一一对应
3、第一次调用va_arg()返回参数列表第 1 项,第二次调用返回第 2 项,以此类推
4、最后,应使用val_end()完成清理,释放动态分配的内存,释放后将不能通过被释放的va_list变量访问列表,如有需要访问则需要重新执行va_start()
5、但因为val_arg()不提供返回之前参数的方法,所以有必要保存va_list类型变量的副本。使用C99新增的va_copy()接受两个va_list变量,将第二个参数拷贝给第一个参数
高级数据表示
章节概要:研究数据表示;结构数组的局限;从数组到链表;优化指针数组;链表引入;使用链表;抽象数据类型(ADT);建立抽象;建立接口;实现接口;使用接口;队列 ADT;定义队列 ADT;建立接口;实现接口;测试队列;用队列进行模拟;链表和数组与查找方式;链表和数组的性质对比;访问元素的方式;顺序查找;二分查找;二分查找的原理;二分查找的优势;二分查找的实现;二叉查找树;二叉树简介;二叉树 ADT;建立接口;实现接口;使用接口;树的思想
研究数据表示
本章总览
1、学习计算机语言和学习音乐、木工或工程学一样,首先要学会使用工具。对目前为止,我们也一直都在学习各种编程技能
2、然而,如果要提高到更高层次,工具是次要的,真正的挑战是设计和创建一个项目
3、本章将重点介绍这个更高的层次,涉及的内容可能会比较难,但这些内容十分有价值
4、本章还会介绍一些算法,即操控数据的方法,并进一步研究设计数据类型的过程。这是一个把算法和数据表示相匹配的过程,期间会用到一些常见的数据形式,如队列、列表、二叉树
5、本章还将介绍抽象数据类型(ADT)的概念。抽象数据类型以面向问题而不是面向语言的方式,把解决问题的方法和数据表示结合起来。理解ADT可以为学习面向对象程序设计和C++语言做好准备问题引入
1、我们来处理一个数据表示的示例。假设要编写一个程序,让用户输入一年内看过的所有电影,要存储每部影片的各种信息(片名、年份、导演、主演、片长、种类等)
2、建议使用一个结构存储每部电影,一个数组存储一年内看过的电影。为简单起见,我们假定结构只有两个成员:片名和评级
3、对此,我们按照这种思路编写如下程序:/* 使用一个结构数组 */ #include <stdio.h> #include <string.h> #define TSIZE 45 // 存储片名的数组大小 #define FMAX 5 // 影片的最大数量 // 定义结构模板,标记为 film struct film { char title[TSIZE]; int rating; }; // 之前自定义的 s_gets() 函数 char *s_gets(char *str, int n) { int i = 0; char *ret_val; ret_val = fgets(str, n, stdin); if (ret_val) { while (str[i] != '\0' && str[i] != '\n') i++; if (str[i] == '\n') str[i] = '\0'; else while (getchar() != '\n') continue; } return ret_val; } int main(void) { // 定义结构数组 struct film movies[FMAX]; int i = 0, j; puts("输入电影名:"); while (i < FMAX && s_gets(movies[i].title, TSIZE) != NULL && movies[i].title[0] != '\0') { puts("输入评分<0-10>:"); scanf("%d", &movies[i++].rating); while (getchar() != '\n') continue; puts("输入下一部电影名(或换行退出):"); } if (i == 0) printf("没有写入数据"); else { printf("获取的电影表格:\n"); for (j = 0; j < i; j++) printf("电影:%s, 评分:%d\n", movies[j].title, movies[j].rating); } return 0; }结构数组的局限
1、该程序创建了一个结构数组,然后把用户输入的数据存储在数组中
2、这样设计程序有点问题。首先,电影名的字符数组大小和整个结构数组大小可能会不够。当然可以增加,但程序却会浪费很多空间
3、另外,一些编译器对自动存储类别变量(如 movie)的内存数量做了默认限制,大型数组可能会超过默认设置的值。可以把数组声明为静态或外部数组,或者设置编译器使用更大的栈,但这样并不能从根本解决问题
4、程序真正的问题是数据表示不够灵活,在运行时再确定所需内存量会更好。为此,应使用动态内存分配,这样便可以更灵活地分配大小:#define TSIZE 45 // 存储片名的数组大小 struct film { char title[TSIZE]; int rating; }; // ... int n,i; struct film *movies; // 声明指向结构的指针 // ... printf("输入电影的数量:\n"); scanf("%d", &n); movies = (struct film *)malloc(n * sizeof(struct film)); // 使用 malloc() 分配内存
从数组到链表
进一步优化
1、对于上面的例子,我们可以进一步优化。最理想的情况是,用户可以不确定的添加数据(而不是事先指定输入多少项),也不用分配多余的空间
2、这可以通过在输入每一项后点调用malloc()函数分配能储存该项的空间。如果用户输入 300 部,就调用 300 次malloc()
3、不过,我们又制造了另一个麻烦。如果调用一次malloc()直接分配 300 个film 结构,分配的是连续的内存块,只需要用一个单独的指向 struct 变量的指针,指向第一个结构,就能通过数组表示法访问块中的每个结构。而现在调用 300 次malloc(),无法保证每次调用malloc()都能分配到连续的内存块,因此你可能需要300 个指针,每个指针指向一个单独存储的结构
4、一种解决方法是创建一个大型的指针数组,并在分配新结构时逐个为这些指针赋值(如示例)
5、但我们并不打算用这种方法。虽然如果用不完 500 个指针,这种办法也节约了大量内存,因为500 个指针的数组比500 个结构的数组所占内存少得多。尽管如此,也还是会浪费一些空间,而且还是有数量上限/* 并不完美的解决方案 */ #define TSIZE 45 // 存储片名的数组大小 #define FMAX 500 // 影片的最大数量 struct film { char title[TSIZE]; int rating; }; // ... struct film *movies[FMAX]; // 定义结构指针数组 int i; // ... movies[i] = (struct film *)malloc(sizeof(struct film));优化指针数组
1、对于上面的问题,还有一种更好的方法。每次使用
malloc()为新结构分配空间时,也为新指针分配空间
2、但是,这样还得需要另一个指针来跟踪新分配的指针;同样,这个用于跟踪新指针的指针本身,又需要一个指针来跟踪
3、因此要重新定义结构才能解决这个潜在的问题。即每个结构中,都包含指向下一个结构的指针。然后创建新结构时,可以把该结构的地址存储在上一个结构的指针中
4、简言之,可以这样定义结构:#define TSIZE 45 // 存储片名的数组大小 struct film { char title[TSIZE]; int rating; struct film *next; // 存储下一个结构位置的指针 };链表引入
1、虽然结构不能含有与本身类型相同的结构,但可以含有同类型结构的指针。这种定义是定义链表的基础,链表中的每一项都包含着在何处能找到下一项的信息
2、学习链表的代码前,先从概念上理解一个链表。假设用户输入的片名为Modern TImes,等级为10
3、程序将为第 1 个 film 类型的结构分配空间,将字符串拷贝到title 成员,数值拷贝到rating 成员。为了表明该结构后面没有其他结构,程序要把指针变量 next设置为NULL(空指针)
4、当然,还需要一个单独的指针存储第一个结构的指针(struct film *head;),该指针被称为头指针。头指针指向链表中的第一项
5、现在,假设用户输入第二部电影,则程序为第 2 个 film 类型的结构分配空间,把新结构的地址存储在上一个结构(即第一个结构)的next 成员中(擦写了之前的 NULL 值),并把第二个结构中的next 成员设置为 NULL,表明该结构目前是链表最后一个结构
6、以此类推,通过头指针访问第一个结构,就能一个个访问 next 成员来访问下一个结构,直到最后一个结构的next 为 NULL
使用链表
示例程序
#include <stdio.h> #include <stdlib.h> // 提供 malloc() 的原型 #include <string.h> // 提供 strcpy() 的原型 #define TSIZE 45 // 存储片名的数组大小 // 定义结构模板,标记为 film struct film { char title[TSIZE]; int rating; struct film *next; // 指向链表中的下一个结构 }; // 之前定义的 s_gets() 函数 char *s_gets(char *str, int n) { int i = 0; char *ret_val; ret_val = fgets(str, n, stdin); if (ret_val) { while (str[i] != '\n' && str[i] != '\0') i++; if (str[i] == '\n') str[i] = '\0'; else while (getchar() != '\n') continue; } return ret_val; } int main(void) { struct film *head = NULL; // 链表头指针(第一个结构的位置) struct film *prev, *current; // 上一个结构指针与当前结构指针 char input[TSIZE]; // 临时存储电影名 // 收集并存储信息 puts("输入第一个电影的名字:"); // 输入input无误 且 首字符不为\0 while (s_gets(input, TSIZE) != NULL && input[0] != '\0') { current = (struct film *)malloc(sizeof(struct film)); // 为当前指针 current 分配一个 struct film 大小的空间用来存储结构 if (head == NULL) // 如果 current 是第一个结构 head = current; // 将 head 头指针指向 current 的位置 else // 如果是后续的结构 prev->next = current; // 上一个结构中的 next 指针指向当前 current 的位置 current->next = NULL; // 将当前结构的 next 成员设置为 NULL,表明是当前链表的最后一个元素 strcpy(current->title, input); // 将临时存储电影名的 input 的内容复制到当前结构的 title 成员 puts("输入你的评分<1-10>:"); scanf("%d", ¤t->rating); while (getchar() != '\n') continue; puts("输入下一个电影名(或换行退出)"); prev = current; // 将表示上一个结构位置的指针 prev 指向 current } // 打印电影列表 if (head == NULL) // 头指针仍然为NULL,则没有结构 printf("没有数据写入"); else printf("这是你的电影列表:\n"); current = head; // 让 current 指向 head 头指针 while (current != NULL) // 只要 current 不是 NULL 空指针(即不是链表最后一个元素) { printf("电影:%s 评分:%d\n", current->title, current->rating); current = current->next; // 让 current 指向 next 成员所指向的下一个结构的位置 } // 完成任务,释放内存 current = head; // 让 current 指向 head 头指针 while (current != NULL) { head = current->next; // 提前让 head 指向下一个结构的位置 free(current); // 释放 current 的内存 current = head; // 让 current 指向提前准备好的指向下一个结构位置的 head } return 0; }继续反思
1、程序还有些许的不足。例如程序没有检查
malloc()是否成功请求到内存,也无法删除链表中的项。不过这些不足可以弥补,例如添加代码检查malloc()返回值是否是 NULL(返回 NULL 说明未成功获得内存)。如果需要删除链表中的项,还需要额外编写更多代码
2、因此,这种用特定方法解决特定问题,并在需要时才添加相关功能的编程方式通常不是最好的解决方案。另一方面,通常无法预料程序要完成的所有任务
3、如果要修改程序,首先应该强调最初的设计,并简化其他细节。上面的示例并没有遵循这个原则,它把概念模型和代码细节混在一起
4、例如程序的概念模型是在一个链表中添加项,但程序却把一些细节放在最明显的位置(例如malloc()、current->next 指针等等处理细节),没有突出接口
5、如果程序能以某种方式强调给链表添加项,并隐藏具体处理细节会更好。把用户接口和代码细节分开的程序,更容易理解和更新。我们下面就会学习有关内容
抽象数据类型(ADT)
引入
1、在编程时,应根据编程问题匹配合适的数据类型。前例中每个链表项由一个字符串和一个 int 值构成,C 中没有直接与之匹配的基本类型,所以我们定义了一个结构来代表单独的项
2、本质上,我们使用C 语言的功能设计了一种符合程序要求的新数据类型,只是我们的做法并不系统。现在我们将使用更系统的方法定义数据类型
3、什么是类型?类型指两类信息:属性和操作。例如,int 类型的属性是它代表一个整数值,因此它共享整数的属性;允许对int 类型进行的算术操作有:改变类型值符号、相加、相减、相乘、相除、取模。当声明一个 int 类型变量时,就表明了只可对此变量进行这些操作
4、假设要定义一个新的数据类型。首先,必须提供存储数据的方法,例如设计一个结构;其次,必须提供操纵数据的方法
5、前例程序用链接的结构存储信息,通过代码实现了如何添加和显示信息,尽管如此,并未清楚表明正在创建一个新类型定义新类型的方法
1、计算机科学领域开发了一种定义新类型的好方法,用三个步骤完成从抽象到具体的过程:
2、提供类型属性和相关操作的抽象描述。这些描述既不能依赖特定的实现,也不能依赖特定的编程语言。这种正式的抽象描述被称为抽象数据类型(ADT)
3、开发一个实现 ADT的编程接口。也就是说,指明如何存储数据和执行所需操作的函数。例如 C 中,可以提供结构定义和操纵该结构的函数原型。这些作用于用户定义类型的函数相当于C 基本类型的内置运算符。需要使用该新类型的程序员可以使用这个接口进行编程
4、编写代码实现接口。这一步至关重要,但是使用该新类型的程序员无需了解具体的实现细节建立抽象
分析链表类型
从根本上看,电影项目所需的是一个项链表。每一项包含电影名和评级。你所需的操作是向链表末尾添加新项和显示链表内容。我们把需要处理这些需求的抽象类型叫做链表
链表具有哪些属性?链表应该能存储多个项,而且这些项以某种方式排列,这样才能描述链表的第一项、第二项或最后一项
链表应提供一些操作,如:
1、初始化一个空链表
2、在链表末尾添加一个新项
3、确定链表是否为空
4、确定链表是否已满
5、确定链表中的项数
6、访问链表中的每一项执行一些操作,如显示该项对该电影程序来说,暂时不需要其他操作,但一般的链表还应该包含以下操作:
1、在链表任意位置插入一个项
2、移除链表中的一个项
3、在链表中检索一个项(不改变链表)
4、用另一个项替换链表中的一个项
5、在链表中搜索一个项
该类型总结如下,下一步是为该链表 ADT开发一个C 接口
/* 类型名: 简单链表 类型属性: 可以存储一系列项 类型操作: 初始化链表为空 确定链表为空 确定链表已满 确定链表中的项数 在链表末尾添加项 遍历链表,处理链表中的项 请空链表 */
建立接口
接口数据类型
这个简单链表的接口有两个部分,第一部分是描述如何表示数据,第二部分是描述实现 ADT 操作的函数
接口设计应尽量与ADT 的描述保持一致,因此,应该用某种通用的 Item 类型而不是一些特殊类型(如 int 或 struct film)
可以用 C 的
typedef功能来定义所需的 Item 类型#define TSIZE 45 // 存储片名的数组大小 struct film { char title[TSIZE]; int rating; }; // 将 film 结构设置别名 Item typedef struct film Item;然后,就可以在定义的其余部分使用 Item 类型,如果以后需要其他数据形式的链表,可以重新定义 Item 类型,而不必更改其余的接口定义
进一步设计如何存储项
在之前链表的示例程序中用链式结构处理得很好,所以在这里我们也用相同的方法(链表的实现中,每一个链节叫做节点 node)
// 将 node 结构设置别名为 Node typedef struct node { Item item; // 包含 film 结构 struct node * next; // 指向下一个结构 } Node; // 将指向 Node 的指针(实际就是一个链表)设置别名 List,表示指向链表开始处的指针 typedef Node * List;是否有其他方法定义List 类型?例如,还可以添加一个变量,记录项数(稍后程序示例会使用这种,现在仍使用前面的方法定义 List 类型)
typedef struct list { Node *head; // 指向链表头的指针 int size; // 链表中的项数 } List;因此,
List movies;创建了该链表所需类型的指针 movies。这里要着重理解声明创建了一个链表,而不是一个指向节点的指针或一个结构
隐藏实现细节
movies代表的确切数据应该是接口层次不可见的实现细节
例如,程序启动后应把头指针初始化为NULL,你的实现细节应如下
movies = NULL; // 稍后你会发现 List 类型的结构实现(即第二种定义List类型的方法)会更好,应该这样初始化 movies.head = NULL; movies.size = 0;而使用该类型的程序员不需要知道List 类型变量的实现细节,只需要使用你提前设计好的
InitializeList()函数来初始化链表即可这是数据隐藏的一个示例,数据隐藏是一个从编程的更高层次隐藏数据表示细节的艺术
为了指引用户使用,你需要在拟定的
InitializeList()函数前提供一些注释帮助使用者使用函数/* 操作:初始化一个链表 前置条件:plist指向一个链表 后置条件:链表初始化为空 */ void InitializeList(List *plist);
接口头文件示例(使用
#ifndef防止多次包含一个头文件)/* list.h 简单链表类型的接口头文件 */ // 使用 #ifndef 检测是否 LIST_H_ 未定义,防止多次包含同一个文件,注意 #endif 在该头文件末尾 #ifndef LIST_H_ // 此处预处理器定义 LIST_H_,如果再次重复调用该头文件,#ifndef 将使得这部分代码不会执行 #define LIST_H_ #include <stdbool.h> /* 特定程序的声明 */ #define TSIZE 45 // 存储片名的数组大小 struct film { char title[TSIZE]; int rating; }; /* 一般类型定义 */ typedef struct film Item; typedef struct node { Item item; struct node *next; } Node; typedef Node * List; /* 函数原型 */ /* 操作:初始化一个链表 前提条件:plist 指向一个链表 后置条件:链表初始化为空 */ void InitializeList(List *plist); /* 操作:确定链表是否为空,plist 指向一个已初始化的链表 后置条件:如果链表为空,返回 true,否则返回 false */ bool ListIsEmpty(List *plist); /* 操作:确定链表是否已满,plist 指向一个已初始化的链表 后置条件:如果链表已满,返回 true,否则返回 false */ bool ListIsFull(List *plist); /* 操作:确定链表中的项数,plist 指向一个已初始化的链表 后置条件:该函数返回链表中的项数 */ unsigned int ListItemCount(const List *plist); /* 操作:在链表末尾添加项 前提条件:item 是一个待添加至链表的项,plist 指向一个已初始化的链表 后置条件:如果可以,该函数在链表末尾添加一个项,且返回 true,否则返回 false */ bool AddItem(Item item, List *plist); /* 操作:把函数作用于链表的每一项 前提条件:plist 指向一个已初始化的链表,pfun 指向一个函数(该函数接受一个Item类型的参数,且无返回值) 后置条件:pfun 指向的函数作用于链表中的每一项一次 */ void Traverse(const List *plist, void(*pfun)(Item item)); /* 操作:释放已分配的内存(如果有的话),plist 指向一个已初始化的链表 后置条件:释放了为链表分配的所有内存,链表设置为空 */ void EmptyTheList(List *plist); #endif
实现接口
说明
1、当然,我们还必须实现 List 接口。C 方法是把函数定义和具体实现统一放在
list.c文件中
2、然后,整个程序由list.h(定义数据结构和提供用户接口的原型)、list.c(提供函数代码实现接口)、film.c(把链表接口应用于特定编程问题的源代码文件)组成
3、下面,演示了list.c的一种实现,要运行整个电影程序,需要把film.c和list.c一起编译和链接示例程序
/* list.c 支持链表操作的函数 */ #include <stdio.h> #include <stdlib.h> #include "list.h" // 局部函数 static void CopyToNode(Item item, Node *pnode) { pnode->item = item; // 拷贝结构 } /* 接口函数 */ // 把链表设置为空 void InitializeList(List *plist) { *plist = NULL; } // 如果链表为空,返回 true bool ListIsEmpty(List *plist) { if (*plist == NULL) return true; else return false; } // 如果链表已满,返回 true bool ListIsFull(List *plist) { Node *pt; bool full; pt = (Node *)malloc(sizeof(Node)); if (pt == NULL) full = true; else full = false; free(pt); return full; } // 返回节点的数量 unsigned int ListItemCount(const List *plist) { unsigned int count = 0; Node *pnode = *plist; // 设置链表的开始 while (pnode != NULL) { ++count; pnode = pnode->next; // 设置下一个节点 } return count; } // 创建存储项的节点,并将其添加至由 plist 指向的链表末尾(较慢的实现) bool AddItem(Item item, List *plist) { Node *pnew; Node *scan = *plist; pnew = (Node *)malloc(sizeof(Node)); if (pnew == NULL) return false; // 内存分配失败时退出函数 CopyToNode(item, pnew); pnew->next = NULL; if (scan == NULL) // 如果 scan(即plist)为空链表,就说明是链表第一个项 *plist = pnew; // 把 pnew 放在链表的开头 else { while (scan->next != NULL) scan = scan->next; // 找到链表的末尾 scan->next = pnew; } return true; } // 访问每个节点并执行 pfun 指向的函数 void Traverse(const List *plist, void (*pfun)(Item item)) { Node *pnode = *plist; // 设置链表的开始 while (pnode != NULL) { (*pfun)(pnode->item); // 把函数应用于链表中的项 pnode = pnode->next; // 前进到下一项 } } /* 释放由 malloc() 分配的内存 */ // 设置链表的指针为 NULL void EmptyTheList(List *plist) { Node *psave; while (*plist != NULL) { psave = (*plist)->next; // 保存下一个节点的地址 free(*plist); // 释放当前节点 *plist = psave; // 前进至下一节点 } }
使用接口
说明
1、我们的目标是,这个接口编写程序,但是不必知道具体的实现细节(如函数的具体实现细节)
2、在编写具体函数之前,我们需要重新设计一下电影程序。由于接口要使用List和Item类型,所以该程序也应该使用这些类型程序示例
/* film.c 电影程序 */ /* 与 list.c 一起编译 */ #include <stdio.h> #include <stdlib.h> // 提供 exit() 的原型 #include "list.h" // 定义 List、Item void showmovies(Item item) { printf("电影:%s 评分:%d\n", item.title, item.rating); } char *s_gets(char *str, int n) { char *ret_val; int i = 0; ret_val = fgets(str, n, stdin); if (ret_val) { while (str[i] != '\0' && str[i] != '\n') i++; if (str[i] == '\n') str[i] = '\0'; else while (getchar() != '\n') continue; } return ret_val; } int main(void) { List movies; Item temp; // 初始化 InitializeList(&movies); if (ListIsFull(&movies)) { fprintf(stderr, "没有空余内存\n"); exit(1); } // 获取用户输入并存储 puts("输入第一个电影名:"); while (s_gets(temp.title, TSIZE) != NULL && temp.title[0] != '\0') { puts("输入你的评分:"); scanf("%d", &temp.rating); while (getchar() != '\n') continue; if (AddItem(temp, &movies) == false) { fprintf(stderr, "内存分配错误\n"); break; } if (ListIsFull(&movies)) { fprintf(stderr, "列表已满\n"); break; } puts("输入下一个电影名(或换行退出):"); } // 显示 if (ListIsEmpty(&movies)) printf("没有数据写入\n"); else { printf("这是你的电影列表:\n"); Traverse(&movies, showmovies); } printf("你一共添加了%d个电影\n", ListItemCount(&movies)); // 清理 EmptyThelist(&movies); printf("再见!\n"); system("pause"); }
队列 ADT
定义队列 ADT
分析队列类型
1、队列是具有两个特殊属性的链表
2、第一,新项只能添加到链表末尾。从这方面看,队列和简单链表类似
3、第二,只能从链表的开头移除项
4、队列是一种先进先出(first in first out,缩写为 FIFO)的数据形式/* 类型名: 队列 类型属性: 可以存储一系列项 类型操作: 初始化列表为空 确定队列为空 确定队列已满 确定队列中的项数 在队列末尾添加项 在队列开头删除或恢复项 清空队列 */
建立接口
实现接口数据表示
确定队列中使用何种 C 数据形式
1、有可能是数组。数组的优点是方便使用,而且向数组末尾添加项很简单
2、问题是如何从队列的开头删除项。类比于排队买票的队列,从队列的开头删除一个项包括拷贝数组首元素的值和把数组剩余各项依次向前移动一个位置
3、编程实现这个过程很简单,但是会浪费大量的计算机时间
4、第二种解决数组队列删除问题的方法是改变队列首端的位置,其余元素不动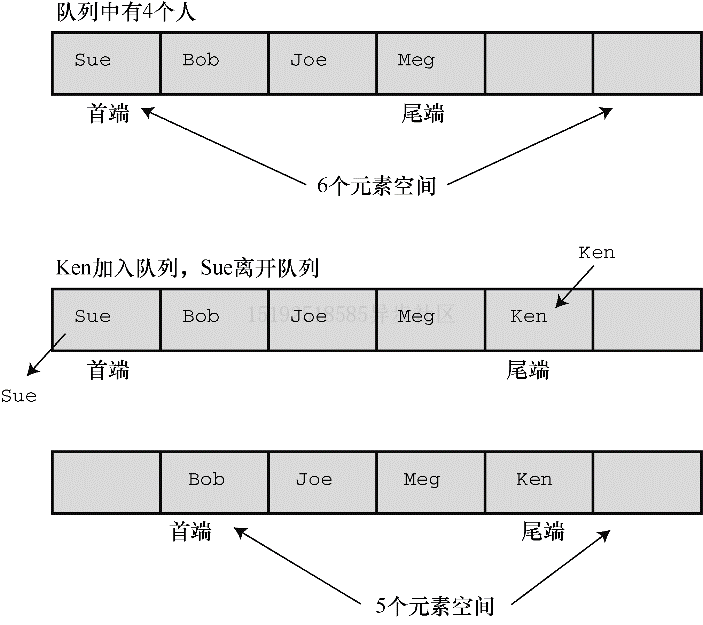
进一步优化数组队列的模型
1、解决这种问题的一个好方法是,使数组成为环形。这意味着把数组的首尾相连,即数组的首元素紧跟在最后一个元素后面
2、这样,当到达数组末尾时,如果首元素空出,就可以把新添加的项存储到这些空出的元素中
3、可以想象在一张条形的纸上画出数组,然后把数组的收尾粘起来形成一个环。当然要做一些标记,以免尾端超过首端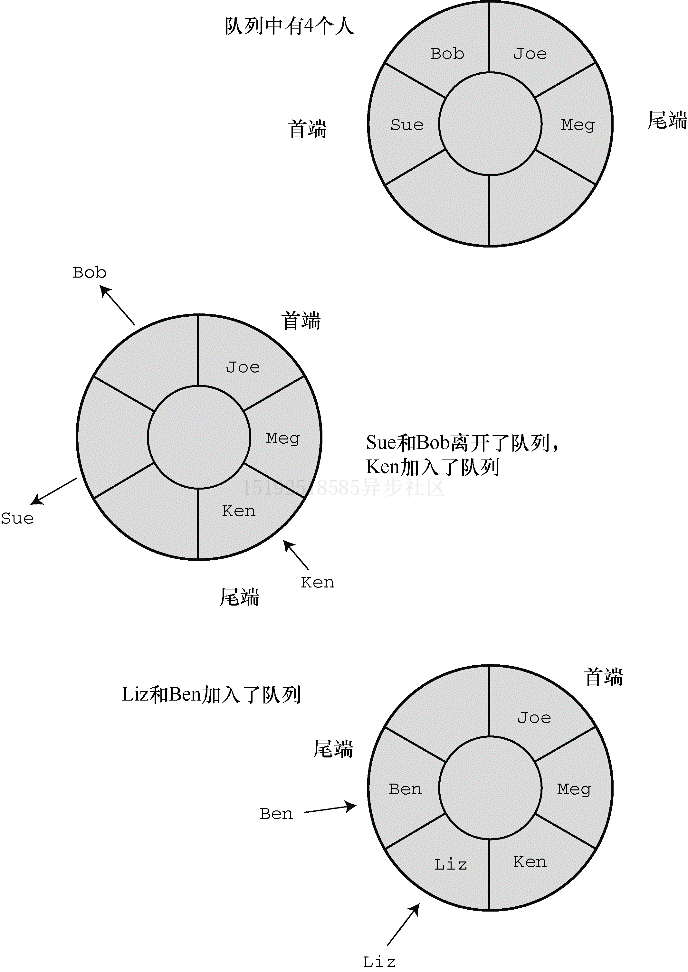
使用链表实现接口数据表示
另一种方法是使用链表。好处是删除首项时不必移动其他元素,只需重置头指针指向新的首元素
由于我们已经讨论过链表,所以采用这个方案。我们用一个整数队列进行测试:
typedef int Item;链表由节点构成,所以下一步是定义节点
typedef struct node { Item item; struct node *next; } Node;对队列而言,要保存首尾项,还可以使用指针来完成。另外可以用一个计数器来记录队列中的项数。因此结构成员如下
typedef struct queue { Node *front; // 指向队列首项的指针 Node *rear; // 指向队列尾项的指针 int items; // 队列中的项数 } Queue;
接口头文件示例
/* queue.h 队列的接口头文件 */ #ifndef QUEUE_H_ #define QUEUE_H_ #include <stdbool.h> // 在这里插入 Item 类型的定义,例如 typedef int Item; // 用于 use_q.c // 或者 typedef struct item{int gumption; int charisma;} Item; typedef struct node { Item item; struct node *next; } Node; typedef struct queue { Node *front; // 指向队列首项的指针 Node *rear; // 指向队列尾项的指针 int items; // 队列中的项数 } Queue; /* 操作:初始化队列 前提条件:pq 指向一个队列 后置条件:队列被初始化为空 */ void InitializeQueue(Queue *pq); /* 操作:检查队列是否已满 前提条件:pq 指向一个已被初始化的队列 后置条件:如果队列已满则返回 true,否则返回 false */ bool QueueIsFull(Queue *pq); /* 操作:检查队列是否为空 前提条件:pq 指向一个已被初始化的队列 后置条件:如果队列为空则返回 true,否则返回 false */ bool QueueIsEmpty(Queue *pq); /* 操作:确定队列中的项数 前提条件:pq 指向一个已被初始化的队列 后置条件:返回队列中的项数 */ int QueueItemCount(Queue *pq); /* 操作:在队列末尾添加项 前提条件:pq 指向一个已被初始化的队列,item 是要被添加在队列末尾的项 后置条件:如果队列不为空,item 将被添加在队列的末尾,函数返回 true;否则,队列不改变,函数返回 false */ bool EnQueue(Item item, Queue *pq); /* 操作:从队列开头删除项 前提条件:pq 指向一个已被初始化的队列 后置条件:如果队列不为空,队列首端的 item 将被拷贝到 *pitem 中并被删除,函数返回 true;如果该操作使得队列为空,则重置队列为空;如果执行该操作前队列为空,函数返回 false */ bool DeQueue(Item *pitem, Queue *pq); /* 操作:清空队列 前提条件:pq 指向一个已被初始化的队列 后置条件:队列被清空 */ void EmptyTheQueue(Queue *pq); #endif
实现接口
示例程序
/* queue.c 队列类型函数的实现 */ #include <stdio.h> #include <stdlib.h> #include "queue.h" // 局部函数 static void CopyToNode(Item item, Node *pn) { pn->item = item; } static void CopyToItem(Node *pn, Item *pi) { *pi = pn->item; } // 实现功能函数 void InitializeQueue(Queue *pq) { pq->front = pq->rear = NULL; pq->items = 0; } bool QueueIsFull(Queue *pq) { return pq->items == MAXQUEUE; } bool QueueIsEmpty(Queue *pq) { return pq->items == 0; } int QueueItemCount(Queue *pq) { return pq->items; } bool EnQueue(Item item, Queue *pq) { Node *pnew; // 如果队列已满,返回 false if (QueueIsFull(pq)) return false; pnew = (Node *)malloc(sizeof(Node)); // 为 pnew 分配内存 // 如果内存分配错误(空指针) if (pnew == NULL) { fprintf(stderr, "无法分配内存!\n"); exit(1); } CopyToNode(item, pnew); // 将值拷贝给 pnew pnew->next = NULL; // 让 pnew 的 next 指针成员指向 NULL if (QueueIsEmpty(pq)) // 如果 pq 本来就为空 pq->front = pnew; // 项位于队列的首端,即首个项 else // 否则则不是首项 pq->rear->next = pnew; // 当前队列尾端 rear 的 next 指针指向 pnew 进行链接 pq->rear = pnew; // 记录队列尾端的位置,更新队列尾端指针 rear 指向 pnew pq->items++; // 队列项数+1 return true; } bool DeQueue(Item *pitem, Queue *pq) { Node *pt; // 如果 pq 本来就为空 if (QueueIsEmpty(pq)) return false; CopyToItem(pq->front, pitem); // 将 pq 的首元素拷贝给 pitem pt = pq->front; // 用 pt 记录目前首元素位置 pq->front = pq->front->next; // 将首元素设置为下一个元素的位置 free(pt); // 释放原先首元素的位置 pq->items--; // 队列项数-1 // 如果删除后队列没有元素了,就初始化队列,将未操作清空的末尾设置为空 if (pq->items == 0) pq->rear = NULL; return true; } void EmptyTheQueue(Queue *pq) { Item dummy; // 临时指针 while (!QueueIsEmpty(pq)) DeQueue(&dummy, pq); }
测试队列
说明
1、在重要程序中使用一个新的设计之前(如,队列包),应该先测试该设计
2、测试的一种方法是,编写一个小程序,这样的程序称为驱动程序,其唯一用途是进行测试
3、注意编写的驱动程序必须链接所需要的queue.c,即多文件编译一起进行编译驱动程序示例
/* use_q.c 驱动程序测试 Queue 接口 */ /* 与 queue.c 一起编译 */ #include <stdio.h> #include "queue.h" // 定义 Queue、Item int main(void) { Queue line; Item temp; char ch; InitializeQueue(&line); puts("测试队列界面,输入a添加值,输入d删除值,输入q退出程序"); while ((ch = getchar()) != 'q') { if (ch != 'a' && ch != 'd') // 忽略其他输入 continue; // 如果为 a 则添加,否则即删除 if (ch == 'a') { printf("输入一个对应队列元素类型的值(该程序为整数):"); scanf("%d", &temp); // 如果队列未满则添加,已满则提示 if (!QueueIsFull(&line)) { EnQueue(temp, &line); printf("成功将%d写入队列\n", temp); } else puts("队列已满,未成功写入"); } else { if (QueueIsEmpty(&line)) puts("队列已经为空!\n"); else { DeQueue(&temp, &line); printf("成功将%d从队列删除\n", temp); } } printf("队列中有%d个元素\n", QueueItemCount(&line)); puts("输入a添加值,输入d删除值,输入q退出程序"); } EmptyTheQueue(&line); puts("队列已正常清空释放,程序退出"); return 0; }
用队列进行模拟
引入
1、经过测试,队列没问题。现在,我们用它来做一些有趣的事情。许多现实生活情景都涉及队列,我们可以用队列包模拟这些情景
2、假设某人在商业街设置了一个提供建议的摊位,顾客可以购买1 分钟、2 分钟、3 分钟的建议。为确保交通畅通,商业街规定每个摊位前排队等待的顾客最多 10 人
3、假设顾客都是随机出现的,并且他们花在咨询上的时间也是随机选择的。那么摊主平均每小时要接待多少顾客?每位顾客平均要花多少时间?排队等待的顾客有多少人?分析
1、首先,要确定队列里放什么。我们可以定义一个结构,存放顾客加入排队的时间和咨询所需的时间,并用该结构替换原队列包中的 Item 类型(如后示例)。因此应按需修改
queue.h和queue.c(必要步骤)
2、这里有一种方法,让时间以 1 分钟为单位递增。每递增 1 分钟,就检查是否有新顾客到来,如果有且队列未满,就将其加入队列;如果队列已满,就让该顾客离开。为了做统计,要记录顾客总数和被拒顾客数
3、接下来,处理队列的首端。如果队列不为空且前面的顾客没有在咨询,则删除首端的项;如果摊主正忙,则不用让任何人离开队列。注意,该项中存储着顾客加入队列的时间,把该时间与当前时间比较,就得出该顾客在队列中的等待时间。该项还存储着需要咨询的分钟数,因此还需要一个变量存储这个数值,每次循环,这个记录等待时间的变量应递减 1typedef struct item { long arrive; // 记录顾客加入队列的时间 int processtime; // 该顾客咨询所需要花费的时间 } Item;示例程序(此处演示如何使用队列模拟,
queue.h和queue.c须自行修改)/* mall.c 使用 Queue 接口 */ /* 与 queue.c 一起编译(注意需要自行修改) */ #include <stdio.h> #include <stdlib.h> // 提供 rand() 和 srand() 的原型 #include <time.h> // 提供 time() 的原型 #include "queue.h" // 已更改 Item 的 typedef #define MIN_PER_HR 60.0 // 每小时的分钟数 // 是否有新顾客到来 // x 是顾客到来的平均时间。如果1分钟内有顾客到来,则返回 true bool newcustomer(double x) { if (rand() * x / RAND_MAX < 1) return true; else return false; } // 设置顾客参数 // when 是顾客到来的时间。该函数返回一个 Item 结构,该顾客到达的时间设置为 when,咨询时间设置为 1~3 的随机值 Item customertime(long when) { Item cust; cust.processtime = rand() % 3 + 1; cust.arrive = when; return cust; } int main(void) { Queue line; Item temp; // 新的顾客数据 int hours; // 模拟的小时数 int perhour; // 每小时平均多少位顾客 long cycle, cyclelimit; // 循环计数器、计数器的上限 long turnaways = 0; // 因队列已满被拒的顾客数 long customers = 0; // 加入队列的顾客数 long served = 0; // 在模拟期间咨询过的顾客数 long sum_line = 0; // 累积的队列总长 int wait_time = 0; // 从当前时间到摊主空闲所需的时间 double min_per_cust; // 顾客到来的平均时间 long line_wait = 0; // 队列累计的等待时间 InitializeQueue(&line); srand((unsigned int)time(0)); // rand() 随机初始化 puts("输入你要模拟的时长:"); scanf("%d", &hours); cyclelimit = MIN_PER_HR * hours; puts("输入每小时平均多少位顾客:"); scanf("%d", &perhour); min_per_cust = MIN_PER_HR / perhour; // 每次迭代对应1分钟的行为 for (cycle = 0; cycle < cyclelimit; cycle++) { // 随机生成这1分钟有没有顾客 if (newcustomer(min_per_cust)) { // 队列已满则让顾客离开并计数 if (QueueIsFull(&line)) turnaways++; // 队列未满则随机生成顾客信息,并将其添加到队列中 else { customers++; temp = customertime(cycle); EnQueue(temp, &line); } } // 如果摊主目前空闲 且 队列不为空 if (wait_time <= 0 && !QueueIsEmpty(&line)) { DeQueue(&temp, &line); // 删除首元素并将其信息拷贝至 temp wait_time = temp.processtime; // 记录摊主接下来多少分钟不空闲 line_wait += cycle - temp.arrive; // 将该顾客的等待时间累加到队列等待总时长中 served++; } // 如果摊主不空闲 if (wait_time > 0) wait_time--; sum_line += QueueItemCount(&line); // 将这一分钟队列的总长累加到队列总长中 } if (customers > 0) { printf("成功排队:%ld\n", customers); printf("成功接待:%ld\n", served); printf("离开顾客:%ld\n", turnaways); printf("平均队列长度:%.2f", (double)sum_line / cyclelimit); printf("平均等待时间:%.2f", (double)line_wait / served); } else puts("没有顾客!"); EmptyTheQueue(&line); puts("已清理队列,成功退出"); return 0; }
链表和数组与查找方式
链表和数组的性质对比
数据形式 优点 缺点 数组 C 直接支持;提供随机访问 需要编译时确定大小;插入和删除元素很费时 链表 运行时确定大小;快速插入和删除元素 不能随机访问;用户必须提供编程支持 访问元素的方式
1、对数组而言,使用数组下标就能直接访问任意元素,这叫做随机访问
2、对链表而言,必须从链表的首节点开始,逐个移动到要访问的节点,这叫做顺序访问
3、当然,也可以顺序访问数组,只需按顺序递增遍历数组即可顺序查找
1、假设要查找列表中的特定项,一种算法是从列表开头按顺序查找,这叫做顺序查找
2、如果该项并未按某种顺序排列,则只能顺序查找
3、如果待查找的项不在列表中,也必须查找完所有项才能得知其不在列表中(这种情况下,可以使用并发编程,同时查找列表中不同的部分)
4、我们可以先排序列表,以改进顺序查找。这样,就不必查找排在待查找项后面的项
5、例如一个按字母顺序排序的列表中查找Susan,如果直到Sylvia都没有找到,就可以退出查找了,因为Susan应排在 Sylvia 前面二分查找
对于一个已排序的列表,用二分查找比顺序查找好得多
二分查找的原理
1、首先,假设把待查找的项称为目标项,而且假设列表中的各项按字母排序
2、然后,比较列表的中间项和目标项。如果两者相等,则找到目标项,查找结束;如果不相等,假设目标项在列表中的话,如果中间项排在目标项前面,那目标项一定在列表的后半部分,反之则一定在前半部分。无论哪种情况,两项的比较结果都确定了下次查找的范围只有列表的一半
3、接着,继续使用这种方法,把需要查找的剩下的一半的中间项与目标项比较,继续缩小一半范围
4、以此类推,直到找到目标项或发现列表中没有目标项为止
二分查找的优势
1、这种方法非常有效率。假如有127 个项,顺序查找平均要进行 64 次比较才能得出结果,而二分查找则至多只用 7 次比较
2、一般而言,n 次比较能处理有 2n -1 个元素的数组。所以项数越多,越能体现二分查找的优势二分查找的实现
1、用数组实现二分查找很简单,因为可以使用数组下标确定数组任意部分的中点,只要把这部分首下标和尾下标进行相加并除 2即可。比较后确定新范围,再获取中点继续比较,以此类推
2、这体现了随机访问的特性,可以从一个位置跳至另一个位置,不用依次访问中间的项
3、但是,链表只支持顺序访问,不能跳至中间节点,所以链表中无法使用二分查找
4、如果需要一种既支持频繁插入和删除项又支持频繁查找的数据形式,数组和链表都不能胜任。这种情况下,应使用二叉查找树
二叉查找树
二叉树简介
1、二叉查找树是一种结合了二分查找策略的链接结构。二叉树的每个节点都包含一个项和两个指向其他子节点的指针(如后图)
2、二叉树中的每个节点都包含两个子节点,即左节点和右节点,其顺序按如下规定:左节点的项在父节点的项前面,右节点的项在父节点的项后面
3、树的顶部为根,树具有分层组织,所以以这种方式存储的数据也以等级或层次组织。一般而言,每级都有上一级和下一级。如果二叉树是满的,那么每一级的节点数都是上一级节点数的两倍
4、二叉树的每个节点都是其后代节点的根,该节点与其后代节点构成了一个子树
5、假设要在二叉树中查找一个项。如果目标项在根节点前面,就只需查找左子树,反之只需查找右子树。因此,每次比较就排除半个树
二叉树 ADT
/* 类型名: 二叉查找树 类型属性: 二叉树要么是空节点的集合(空树),要么是有一个根节点的节点集合 每个节点都有两个子树,叫左子树和右子树 每个子树本身也是一个二叉树,也有可能是空树 二叉查找树是一个有序的二叉树,每个节点包含一个项 左子树的所有项都在根节点项的前面,右子树的所有项都在根节点项的后面 类型操作: 初始化树为空 确定树是否为空 确定树是否已满 确定树中的项数 在树中添加一个项 在树中删除一个项 在树中查找一个项 在树中访问一个项 清空树 */建立接口
实现接口数据表示
1、原则上,可以用多种方法实现二叉查找树,甚至可以通过操纵数组下标用数组实现
2、但是,实现二叉查找树最直接的方法是通过指针动态分配链式节点接口头文件示例
/* tree.h 二叉查找树的接口头文件 */ // 树中不允许有重复的项 #ifndef TREE_H_ #define TREE_H_ #include <stdbool.h> // 根据具体情况重新定义 Item #define SLEN 20 typedef struct item { char petname[SLEN]; char petkind[SLEN]; } Item; #define MAXITEMS 10 typedef struct trnode { Item item; struct trnode *left; // 指向左分支的指针 struct trnode *right; // 指向右分支的指针 } Trnode; typedef struct tree { Trnode *root; // 指向根节点的指针 int size; // 树的项数 } Tree; /* 操作:初始化树 前提条件:ptree 指向一个树 后置条件:树被初始化为空 */ void InitializeTree(Tree *ptree); /* 操作:检查树是否为空 前提条件:ptree 指向一个树 后置条件:如果树为空则返回 true,否则返回 false */ bool TreeIsEmpty(Tree *ptree); /* 操作:检查树是否已满 前提条件:ptree 指向一个树 后置条件:如果树已满则返回 true,否则返回 false */ bool TreeIsFull(Tree *ptree); /* 操作:确定树的项数 前提条件:ptree 指向一个树 后置条件:返回树的项数 */ int TreeItemCount(Tree *ptree); /* 操作:在树中添加一个项 前提条件:pi 是待添加项的地址,ptree 指向一个已初始化的树 后置条件:如果可以添加,该函数将在树中添加一个项,并返回 true;否则返回 false */ bool AddItem(Item *pi, Tree *ptree); /* 操作:从树中查找一个项 前提条件:pi 指向一个项,ptree 指向一个已初始化的树 后置条件:如果在树中找到指定项,则返回 true;否则返回 false */ bool InTree(Item *pi, Tree *ptree); /* 操作:从树中删除一个项 前提条件:pi 是删除项的地址,ptree 指向一个已初始化的树 后置条件:如果从树中成功删除一个项,则返回 true;否则返回 false */ bool DeleteItem(Item *pi, Tree *ptree); /* 操作:把函数应用于树中的每一项 前提条件:ptree 指向一个树,pfun 指向一个函数,该函数接受一个 Item 类型的参数且无返回值 后置条件:pfun 指向的这个函数为树中的每一项执行一次 */ void Traverse(Tree *ptree, void (*pfun)(Item item)); /* 操作:清空树中的所有内容 前提条件:ptree 指向一个已被初始化的树 后置条件:树被清空 */ void DeleteAll(Tree *ptree); #endif
实现接口
添加项
添加项的实现思路
1、在树中添加一个项,首先要检查是否有空余位置。由于我们定义二叉树时规定其中的项不重复,所以还要检查树中是否已有该项
2、通过这两步检查后,便可创建一个新节点,把待添加项拷贝到该节点中,并设置节点的左指针和右指针都为NULL,这表明该节点没有子节点
3、然后,更新Tree结构的size成员,统计新增一项
4、接下来,必须找出应该把这个新节点放在树中哪个位置。如果树为空,则应设置根节点指针指向该新节点;否则,遍历树找到合适位置存放节点
5、注意该函数中仍使用了一些静态函数来实现功能,这些函数将在后续说明bool AddItem(Item *pi, Tree *ptree) { Trnode *new_node; if (TreeIsFull(ptree)) { fprintf(stderr, "树已满!\n"); return false; } if (SeekItem(pi, ptree).child != NULL) { fprintf(stderr, "添加的项重复!\n"); return false; } new_node = MakeNode(pi); // 指向新节点 if (new_node == NULL) { fprintf(stderr, "无法分配内存!\n"); return false; } // 成功创建了一个新节点 ptree->size++; if (ptree->root == NULL) // 如果根为空 ptree->root = new_node; // 则这是第一个项,令根节点指向该节点 else // 否则 AddNode(new_node, ptree->root); // 在树中添加节点 return true; }部分静态函数的实现思路
static Trnode *MakeNode(Item *pi) { Trnode *new_node; new_node = (Trnode *)malloc(sizeof(Trnode)); // 分配内存 if(new_node != NULL) // 如果内存成功分配,就初始化新节点 { new_node->item = *pi; new_node->left = NULL; new_node->right = NULL; } return new_node; } static void AddNode(Trnode *new_node, Trnode *root) { // ToLeft() 和 ToRight() 判断该左移还是右移 if (ToLeft(&new_node->item, &root->item)) { if (root->left == NULL) // 空子树 root->left = new_node; // 在此处添加节点 else // 否则 AddNode(new_node, root->left); // 继续处理该子树 } else if (ToRight(&new_node->item, &root->item)) { if (root->right == NULL) root->right = new_node; else AddNode(new_node, root->right); } else { fprintf(stderr, "AddNode() 函数执行错误!\n"); exit(1); } } static bool ToLeft(Item *i1, Item *i2) { // 比对字符串 int comp1; // 比对 petname,如果 i1 的小于 i2 的,则 comp1 小于 0 if ((comp1 = strcmp(i1->petname, i2->petname)) < 0) return true; // 如果 petname 相同,则比对 petkind 的字符串 else if (comp1 == 0 && strcmp(i1->petkind, i2->petkind) < 0) return true; else return false; }
查找项
查找项的数据类型
1、3 个接口函数都要在树中查找特定项:
AddItem()、InTree()和DeleteItem()。这些函数的实现中使用SeekItem()函数进行查找
2、DeleteItem()有一个额外的要求:该函数要知道待删除项的父节点,以便在删除子节点后更新父节点指向子节点的指针
3、因此,我们设计SeekItem()函数返回的结构包含两个指针:一个指向包含项的节点(未找到则为 NULL),一个指向父节点(如果该节点为根节点,则没有父节点,则为 NULL)。因此,结构类型定义如下:typedef struct pair { Trnode *parent; // 指向查找项的父节点 Trnode *child; // 指向查找项 } Pair;查找项的实现思路
1、
SeekItem()函数可以用递归的方式实现。但为了介绍更多技巧,我们这里使用while循环处理查找
2、开始时,SeekItem()设置look.child指向该树根节点。然后沿着目标项应在的路径(通过ToLeft()和ToRight()导航)重置look.child指向后续的子树,同时设置look.parent指向后续的父节点
3、如果没有找到匹配的项,look.child设置为NULL。如果在根节点找到,look.parent设置为NULL(根节点没有父节点)static Pair SeekItem(Item *pi, Tree *ptree) { Pair look; look.parent = NULL; look.child = ptree->root; if (look.child == NULL) return look; while (look.child != NULL) { if (ToLeft(pi, &(look.child->item))) { look.parent = look.child; look.child = look.child->left; } else if (ToRight(pi, &(look.child->item))) { look.parent = look.child; look.child = look.child->right; } else // 如果前两种都不满足,那必然相等 break; // 打断循环,look.child 就是目标项节点,已找到 } return look; // 返回的是一个结构 }
删除项
删除项是最复杂的任务,因为必须重新连接剩余子树形成有效的树
删除节点的子节点情况讨论
没有子节点
1、待删除的节点没有子节点,这样的节点被称为叶节点,这种情况最简单
2、只需要把父节点的指针重置为NULL,并使用free()释放已删除节点的内存
一个子节点
1、删除带有一个子节点的情况比较复杂。删除该节点会导致其子树与其他部分脱离
2、为了修正这种情况,要把被删除节点的父节点中存储该节点的地址更新为该节点子树的地址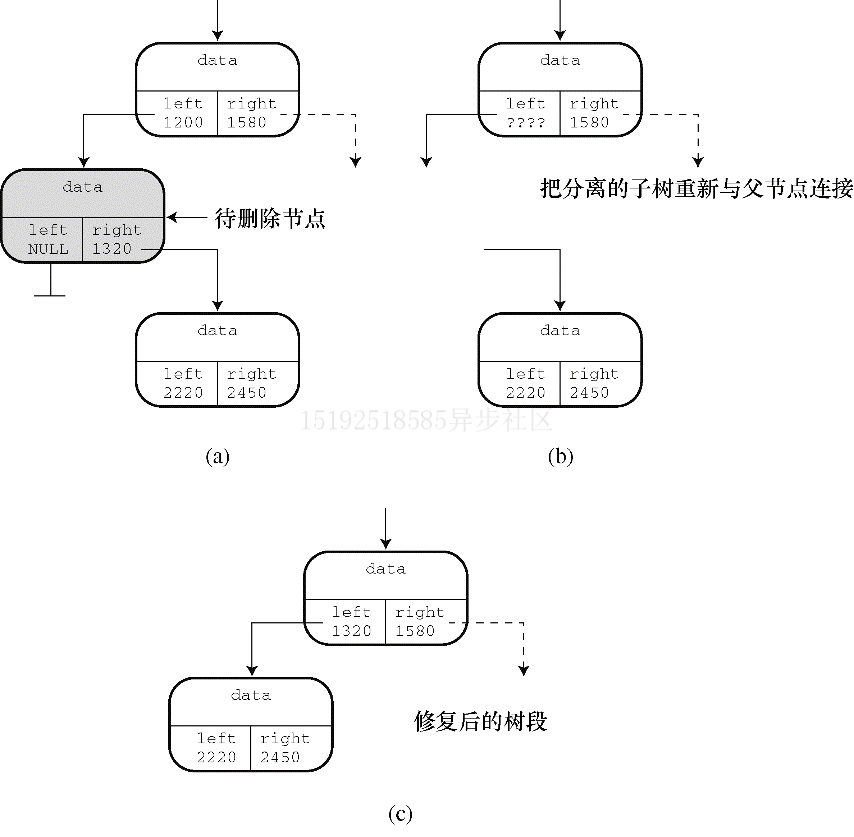
两个子节点
1、最后一种情况是删除有两个子树的节点。其中一个子树(如左子树)可以连接在被删除节点之前链接的位置,但是另一个子树怎么处理?
2、牢记树的基本设计:左子树所有项都在父节点项的前面,右子树所有项都在父节点项的后面。也就是说,右子树所有项都在左子树所有项的后面
3、而且,因为该右子树曾经是被删除节点的父节点的左子树中的一部分,所以该右节点所有项都在被删除节点的父节点项的前面
4、该右子树的头的位置应该在被删除节点的父节点前面,因此要沿着父节点的左子树向下找,同时这些项又在被删除节点的左子树所有项后面
5、因此要查看左子树的右支是否有新节点的空位。如果没有,就要沿着左子树的右支向下找,直到找到一个空位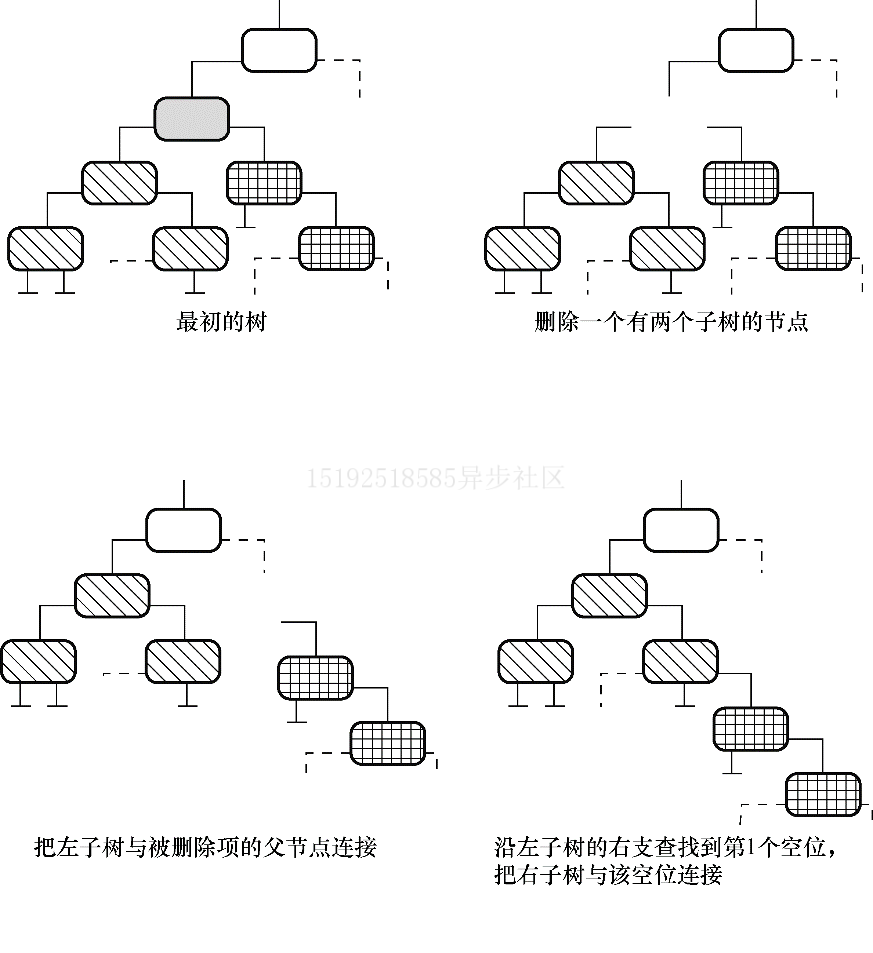
删除项的实现思路
删除一个节点
1、删除节点要注意两点:程序必须标识待删除节点的父节点;为了修改指针,代码必须把该指针的地址传给执行删除任务的函数
2、第一点稍后讨论,先分析第二点。要修改的指针本身是Trnode *类型,即指向 Trnode 的指针;由于该函数的参数是该指针的地址,所以参数类型是Trnode **,即指向指针的指针
3、我们分为三种情况讨论:没有左子节点的节点、没有右子节点的节点、有两个子节点的节点。其中前两种情况同时成立则包含了两个节点都没有的情况static void DeleteNode(Trnode **ptr) // ptr 是指向目标节点的父节点指针成员的地址 { Trnode *temp; if ((*ptr)->left == NULL) { temp = *ptr; *ptr = (*ptr)->right; free(temp); } else if ((*ptr)->right == NULL) { temp = *ptr; *ptr = (*ptr)->left; free(temp); } // 被删除的节点有两个子节点 else { // 找到重新连接右子树的位置 for (temp = (*ptr)->left; temp->right != NULL; temp = temp->right) continue; temp->right = (*ptr)->right; temp = *ptr; *ptr = (*ptr)->left; free(temp); } }删除一个项
1、剩下的问题是把一个节点与特定项相关联。可以使用
SeekItem()函数来完成
2、回忆一下,该函数返回一个结构,包含两个指针:一个指向父节点,一个指向包含特定项的节点
3、然后就可以通过父节点的指针获得相应的地址传给DeleteNode()函数bool DeleteItem(Item *pi, Tree *ptree) { Pair look; look = SeekItem(pi, ptree); if (look.child == NULL) return false; if (look.parent == NULL) DeleteNode(&ptree->root); // 删除根节点 else if (look.parent->left == look.child) DeleteNode(&look.parent->left); else DeleteNode(&look.parent->right); ptree->size--; return true; }
遍历树
遍历树的实现思路
1、遍历树比遍历链表更复杂,因为每个节点都有两个分支。这种分支特性很适合使用分而治之的递归来处理
2、对于每个节点,执行遍历任务的函数都要做如下工作:处理节点中的项、处理左子树(递归调用)、处理右子树(递归调用)
3、可以把遍历分为两个函数来完成:Traverse()和InOrder()。注意InOrder()函数处理左子树,然后处理项,最后处理右子树。这种遍历树的顺序是按字母排序进行的static void InOrder(Trnode *root, void (*pfun)(Item item)) { if (root != NULL) { // 递归 InOrder(root->left, pfun); (*pfun)(root->item); InOrder(root->right, pfun); } } void Traverse(Tree *ptree, void (*pfun)(Item item)) { if (ptree != NULL) InOrder(ptree->root, pfun); }
清空树
清空树的实现思路
1、清空树基本上和遍历树过程相同,即清空树的代码也要访问每个节点,而且要用
free()释放内存
2、除此之外,还要重置 Tree 类型结构的成员,表明该树为空
3、DeleteAll()函数负责处理 Tree 类型结构,并把释放内存的任务交给DeleteAllNodes()函数static void DeleteAllNodes(Trnode *root) { Trnode *pright; if (root != NULL) { pright = root->right; // 递归 DeleteAllNodes(root->left); free(root); DeleteAllNodes(pright); } } void DeleteAll(Tree *ptree) { if (ptree != NULL) DeleteAllNodes(ptree->root); ptree->root = NULL; ptree->size = 0; }
完整的实现接口示例
/* tree.c 二叉查找树类型函数的实现 */ #include <stdio.h> #include <string.h> #include <stdlib.h> #include "tree.h" //局部数据类型 typedef struct pair { Trnode *parent; Trnode *child; } Pair; // 局部函数 static void InOrder(Trnode *root, void (*pfun)(Item item)) { if (root != NULL) { // 递归 InOrder(root->left, pfun); (*pfun)(root->item); InOrder(root->right, pfun); } } static void DeleteAllNodes(Trnode *root) { Trnode *pright; if (root != NULL) { pright = root->right; // 递归 DeleteAllNodes(root->left); free(root); DeleteAllNodes(pright); } } static bool ToLeft(Item *i1, Item *i2) { // 比对字符串 int comp1; // 比对 petname,如果 i1 的小于 i2 的,则 comp1 小于 0 if ((comp1 = strcmp(i1->petname, i2->petname)) < 0) return true; // 如果 petname 相同,则比对 petkind 的字符串 else if (comp1 == 0 && strcmp(i1->petkind, i2->petkind) < 0) return true; else return false; } static bool ToRight(Item *i1, Item *i2) { // 比对字符串 int comp1; // 比对 petname,如果 i1 的大于 i2 的,则 comp1 大于 0 if ((comp1 = strcmp(i1->petname, i2->petname)) > 0) return true; // 如果 petname 相同,则比对 petkind 的字符串 else if (comp1 == 0 && strcmp(i1->petkind, i2->petkind) > 0) return true; else return false; } static void AddNode(Trnode *new_node, Trnode *root) { // ToLeft() 和 ToRight() 判断该左移还是右移 if (ToLeft(&new_node->item, &root->item)) { if (root->left == NULL) // 空子树 root->left = new_node; // 在此处添加节点 else // 否则 AddNode(new_node, root->left); // 继续处理该子树 } else if (ToRight(&new_node->item, &root->item)) { if (root->right == NULL) root->right = new_node; else AddNode(new_node, root->right); } else { fprintf(stderr, "AddNode() 函数执行错误!\n"); exit(1); } } static Trnode *MakeNode(Item *pi) { Trnode *new_node; new_node = (Trnode *)malloc(sizeof(Trnode)); // 分配内存 if (new_node != NULL) { new_node->item = *pi; new_node->left = NULL; new_node->right = NULL; } return new_node; } static Pair SeekItem(Item *pi, Tree *ptree) { Pair look; look.parent = NULL; look.child = ptree->root; if (look.child == NULL) return look; while (look.child != NULL) { if (ToLeft(pi, &(look.child->item))) { look.parent = look.child; look.child = look.child->left; } else if (ToRight(pi, &(look.child->item))) { look.parent = look.child; look.child = look.child->right; } else // 如果前两种都不满足,那必然相等 break; // 打断循环,look.child 就是目标项节点,已找到 } return look; // 返回的是一个结构 } static void DeleteNode(Trnode **ptr) // ptr 是指向目标节点的父节点指针成员的地址 { Trnode *temp; if ((*ptr)->left == NULL) { temp = *ptr; *ptr = (*ptr)->right; free(temp); } else if ((*ptr)->right == NULL) { temp = *ptr; *ptr = (*ptr)->left; free(temp); } // 被删除的节点有两个子节点 else { // 找到重新连接右子树的位置 for (temp = (*ptr)->left; temp->right != NULL; temp = temp->right) continue; temp->right = (*ptr)->right; temp = *ptr; *ptr = (*ptr)->left; free(temp); } } // 实现功能函数 void InitializeTree(Tree *ptree) { ptree->root = NULL; ptree->size = 0; } bool TreeIsEmpty(Tree *ptree) { if (ptree->root == NULL) return true; else return false; } bool TreeIsFull(Tree *ptree) { if (ptree->size == MAXITEMS) return true; else return false; } int TreeItemCount(Tree *ptree) { return ptree->size; } bool AddItem(Item *pi, Tree *ptree) { Trnode *new_node; if (TreeIsFull(ptree)) { fprintf(stderr, "树已满!\n"); return false; } if (SeekItem(pi, ptree).child != NULL) { fprintf(stderr, "添加的项重复!\n"); return false; } new_node = MakeNode(pi); // 指向新节点 if (new_node == NULL) { fprintf(stderr, "无法分配内存!\n"); return false; } // 成功创建了一个新节点 ptree->size++; if (ptree->root == NULL) // 如果根为空 ptree->root = new_node; // 则这是第一个项,令根节点指向该节点 else // 否则 AddNode(new_node, ptree->root); // 在树中添加节点 return true; } bool InTree(Item *pi, Tree *ptree) { return (SeekItem(pi, ptree).child == NULL) ? false : true; } bool DeleteItem(Item *pi, Tree *ptree) { Pair look; look = SeekItem(pi, ptree); if (look.child == NULL) return false; if (look.parent == NULL) DeleteNode(&ptree->root); // 删除根节点 else if (look.parent->left == look.child) DeleteNode(&look.parent->left); else DeleteNode(&look.parent->right); ptree->size--; return true; } void Traverse(Tree *ptree, void (*pfun)(Item item)) { if (ptree != NULL) InOrder(ptree->root, pfun); } void DeleteAll(Tree *ptree) { if (ptree != NULL) DeleteAllNodes(ptree->root); ptree->root = NULL; ptree->size = 0; }
使用接口(实现宠物俱乐部花名册)
/* petclub.c 使用二叉树接口 */ /* 与 tree.c 一起编译 */ #include <stdio.h> #include <string.h> #include <ctype.h> #include "tree.h" char *s_gets(char *str, int n) { char *ret_val; int i = 0; ret_val = fgets(str, n, stdin); if (ret_val) { while (str[i] != '\0' && str[i] != '\n') i++; if (str[i] == '\n') str[i] = '\0'; else while (getchar() != '\n') continue; } return ret_val; } // 将字符串转换为大写 void uppercase(char *str) { while (*str) { *str = toupper(*str); str++; } } // 打印成员 void printitem(Item item) { printf("宠物:%-19s 品种:%-19s\n", item.petname, item.petkind); } char menu(void) { int ch; puts("\n宠物俱乐部成员程序"); puts("输入对应字母选择功能:"); puts("a) 添加一只宠物 l) 显示宠物菜单"); puts("n) 显示宠物数量 f) 查找宠物"); puts("d) 删除一只宠物 q) 退出程序"); while ((ch = getchar()) != EOF) { while (getchar() != '\n') // 处理输入队列多余内容 continue; ch = tolower(ch); // 统一转换为小写 // strchr() 确定 "alfndq" 中是否包含 ch 对应字符,并返回对应位置指针,如果不包含则返回 NULL if (strchr("alfndq", ch) == NULL) puts("请输入a,l,f,n,d,q:"); else break; } if (ch == EOF) ch = 'q'; // 退出程序 return ch; } void addpet(Tree *pt) { Item temp; if (TreeIsFull(pt)) puts("俱乐部成员已满!"); else { puts("输入宠物的名字:"); s_gets(temp.petname, SLEN); puts("输入宠物的品种:"); s_gets(temp.petkind, SLEN); uppercase(temp.petname); uppercase(temp.petkind); AddItem(&temp, pt); } } void showpets(Tree *pt) { if (TreeIsEmpty(pt)) puts("没有成员!"); else Traverse(pt, printitem); } void findpet(Tree *pt) { Item temp; if (TreeIsEmpty(pt)) { puts("没有成员!"); return; // 退出函数 } puts("输入要查找的宠物名称:"); s_gets(temp.petname, SLEN); puts("输入该宠物的品种:"); s_gets(temp.petkind, SLEN); uppercase(temp.petname); uppercase(temp.petkind); printf("%s(%s) ", temp.petname, temp.petkind); if (InTree(&temp, pt)) printf("已在俱乐部中\n"); else printf("不在俱乐部中\n"); } void droppet(Tree *pt) { Item temp; if (TreeIsEmpty(pt)) { puts("没有成员!"); return; // 退出函数 } puts("输入要删除的宠物名称:"); s_gets(temp.petname, SLEN); puts("输入该宠物的品种:"); s_gets(temp.petkind, SLEN); uppercase(temp.petname); uppercase(temp.petkind); printf("%s(%s) ", temp.petname, temp.petkind); if (DeleteItem(&temp, pt)) printf("已经删除\n"); else printf("本就不在俱乐部中\n"); } int main(void) { Tree pets; char choice; InitializeTree(&pets); while ((choice = menu()) != 'q') { switch (choice) { case 'a': addpet(&pets); break; case 'l': showpets(&pets); break; case 'f': findpet(&pets); break; case 'n': printf("俱乐部中共有 %d 只宠物\n", TreeItemCount(&pets)); break; case 'd': droppet(&pets); break; default: puts("switch() 执行错误!"); } } DeleteAll(&pets); puts("已成功释放内存,运行结束"); return 0; }树的思想
二叉查找树的缺陷
1、二叉查找树也有一些缺陷。例如二叉查找树只有在满员(或平衡)时效率最高
2、假设用户按字母顺序输入数据,那么每个新节点都应该被添加到右边(如下图),查找这种不平衡的树并不比查找链表要快
避免串状树
1、避免串状树的方法之一是在创建树时多加注意。如果树或子树的一边或另一边不太平衡,就需要重新排列节点使之恢复平衡。与此类似,可能在进行删除操作后也要重新排列树
2、德国数学家 Adel’son-Vel’skii 和 Landis 发明了一种算法来解决这个问题,根据他们的算法创建的树称为AVL 树
3、因为要重构,所以创建一个平衡的树要花费更多时间,但这样的树可以确保搜索效率最大化存储相同项的思路
1、你可能需要一个能存储相同项的二叉查找树。例如在分析文本时,统计某个单词出现的次数
2、一种方法是把 Item 定义为包含一个单词和一个数字的结构。第一次遇到这个单词时将其添加到树中,并且该单词计数器+1;下一次遇到时直接找到该节点并递增计数器。使用这种方法修改二叉查找树的特性,并不费多少功夫
附录
章节概要:C 运算符;ANSI C 库函数、宏和类型;拓展整数类型
inttypes.h;拓展字符支持
C 运算符
运算符优先级
运算符(优先级从高至低) 结合律 ++(后缀) –(后缀) ()(函数调用) [] {}(复合字面量) . -> 从左往右 ++(前缀) –(前缀) -(负号) +(正号) *(解引用) &(取址) ~(按位取反) !(逻辑非) sizeof _Alignof(类型名) 从右往左 (类型名)(强制类型转换) 从右往左 * / % 从左往右 +(加) -(减) 从左往右 << >> 从左往右 < > <= >= 从左往右 == != 从左往右 & 从左往右 ^ 从左往右 | 从左往右 && 从左往右 || 从左往右 ?:(条件(三目)运算符) 从右往左 = += -= *= /= %= &= |= ^= <<= >>= 从右往左 ,(逗号运算符) 从左往右 算术运算符
算术运算符 作用 + 把右边的值加到左边的值上 + 作为一元运算符,生成一个大小和符号都与右边值相同的值 - 从左边的值中减去右边的值 - 作为一元运算符,生成一个与右边值大小相等符号相反的值 * 把左边的值乘以右边的值 / 把左边的值除以右边的值;如果两个运算对象都是整数,其结果要被截断 % 得左边值除以右边值时的余数 ++ ++把右边变量的值加 1(前缀模式),或把左边变量的值加 1(后缀模式) – –把右边变量的值减 1(前缀模式),或把左边变量的值减 1(后缀模式) 关系运算符
关系运算符 作用 < 小于 <= 小于等于 > 大于 >= 大于等于 == 等于 != 不等于 赋值(复合)运算符
赋值(复合)运算符 作用 = 把它右边的值赋给其左边的左值 += 把左边的变量加上右边的量,并把结果存储在左边的变量中 -= 从左边的变量中减去右边的量,并把结果存储在左边的变量中 *= 把左边的变量乘以右边的量,并把结果存储在左边的变量中 /= 把左边的变量除以右边的量,并把结果存储在左边的变量中 %= 得到左边量除以右边量的余数,并把结果存储在左边的变量中 &= 把 L & R 的值赋给左边的量,并把结果存储在左边的变量中 |= 把 L | R 的值赋给左边的量,并把结果存储在左边的变量中 ^= 把 L ^ R 的值赋给左边的量,并把结果存储在左边的变量中 >>= 把 L >> R 的值赋给左边的量,并把结果存储在左边的变量中 <<= 把 L << R 的值赋给左边的量,并把结果存储在左边的变量中 逻辑运算符
逻辑运算符 作用 && 逻辑与 || 逻辑或 ! 逻辑非 按位运算符
按位运算符 作用 ~(按位取反) 它通过翻转运算对象的每一位得到一个值 &(按位与) 只有当两个运算对象中对应的位都为 1 时,它生成的值中对应的位才为 1 |(按位或) 只要两个运算对象中对应的位有一位为 1,它生成的值中对应的位就为 1 ^(按位异或) 只有两个运算对象中对应的位中只有一位为 1(不能全为 1),它生成的值中对应的位才为 1 <<(左移运算符) 把左边运算对象中的位向左移动得到一个值。移动的位数由该运算符右边的运算对象确定,空出的位用 0 填充 >>(右移运算符) 把左边运算对象中的位向右移动得到一个值。移动的位数由该运算符右边的运算对象确定,空出的位用 0 填充 条件(三目)运算符
条件(三目)运算符 作用 (关系表达式)?(语句 1):(语句 2) 如果关系表达式为真,则执行语句 1,否则执行语句 2 指针有关运算符
指针有关运算符 作用 &(地址运算符) 给出后面变量的地址 *(间接运算符、解引用运算符) 给出后面指针指向地址的值 结构和联合运算符
结构和联合运算符 作用 .(成员运算符) name.member 获取 name 结构中的 member 成员 ->(间接成员运算符、结构指针运算符) ptrname->member 获取 ptrname 所指向结构中的 member 成员
ANSI C 库函数、宏和类型
断言
assert.h宏
宏 描述 void assert (int exprs); 如果 exprs 为真,宏什么也不做。如果 exprs 为假,assert()就显示该表达式和其所在的行号和文件名。然后,assert()调用 abort() static_assert 展开为 _Static_assert。其中 _Static_assert(常量表达式,字符串字面量) 如果常量表达式为假,编译器给出包含字符串字面量的错误信息(C11)
复数
complex.h(C99)宏
宏 描述 complex 展开为类型关键字_Complex _Complex_I 展开为 const float _Complex 类型的表达式,其值的平方为-1 imaginary 如果支持虚数类型,展开为类型关键字_Imaginary _Imaginary_I 如果支持虚数类型,展开为 const float _Imaginary 类型的表达式,其值的平方为-1 I 展开为_Complex_I 或_Imaginary_I 函数(另有 float 和 long double 版本,在函数名后加上 f 或 l 即可切换,角度的单位是弧度)
函数原型 描述 double complex cacos(double complex z); 返回 z 的复数反余弦 double complex casin(double complex z); 返回 z 的复数反正弦 double complex catan (double complex z); 返回 z 的复数反正切 double complex ccos (double complex z); 返回 z 的复数余弦 double complex csin(double complex z); 返回 z 的复数正弦 double complex ctan(double complex z); 返回 z 的复数正切 double complex cacosh(double complex z); 返回 z 的复数反双曲余弦 double complex casinh(double complex z); 返回 z 的复数反双曲正弦 double complex catanh (double complex z); 返回 z 的复数反双曲正切 double complex ccosh(double complex z); 返回 z 的复数双曲余弦 double complex csinh(double complex z); 返回 z 的复数双曲正弦 double complex ctanh (double complex z); 返回 z 的复数双曲正切 double complex cexp(double complex z); 返回 e 的 z 次幂复数值 double complex clog(double complex z); 返回 z 的自然对数(以 e 为底)的复数值 double cabs(double complex z); 返回 z 的绝对值(或大小) double complex cpows (double complex z,double complex y); 返回 z 的 y 次幂 double complex csqrt (double complex z); 返回 z 的复数平方根 double carg(double complex z); 以孤度为单位返回 z 的相位角(或幅角) double cimag(double complex z); 以实数形式返回 z 的虚部 double complex conj(double complex z); 返回 z 的共轭复数 double complex cproj(double complex z); 返回 z 在黎曼球面上的投影 double complex CMPLX(double x,double y); 返回实部为 x、虚部为 y 的复数(C11) double creal(double complex z); 以实数形式返回 z 的实部
字符处理
ctype.h函数
函数原型 描述 int isalnum(int c); 如果 c 是字母或数字,则返回真 int isalpha(int c); 如果 c 是字母,则返回真 int isblank(int c); 如果 c 是空格或水平制表符,则返回真(C99) int iscntrl(int c); 如果 c 是控制字符(如 Ctr1+B),则返回真 int isdigit(int c); 如果 c 是数字,则返回真 int isgraph(int c); 如果 c 是非空格打印字符,则返回真 int islower(int c); 如果 c 是小写字符,则返回真 int isprint(int c); 如果 c 是打印字符,则返回真 int ispunct(int c); 如果 c 是标点字符(除了空格、字母、数字以外的字符),则返回真 int isspace(int c); 如果 c 是空白字符(空格、换行符、换页符、回车符、垂直或水平制表符,或者其他实现定义的字符),则返回真 int isxdigit(int c); 如果 C 是十六进制数字字符,则返回真 int isupper(int c); 如果 c 是大写字符,则返回真 int tolower(int c); 如果 c 是大写字符,则返回其小写字符;否则返回 c int toupper(int c); 如果 c 是小写字符,则返回其大写字符;否则返回 c
错误报告
errno.h宏
宏 含义 EDOM 函数调用中的域错误(参数越界) ERANGE 函数返回值的范围错误(返回值越界) EILSEQ 宽字符转换错误
浮点环境
fenv.h(C99)类型
类型 表示 fenv_t 整个浮点环境 fexcept_t 浮点状态标志集合 宏
标准异常宏 含义 FE_DIVBYZERO 抛出被零除异常 FE_INEXACT 抛出不精确值异常 FE_INVALID 抛出无效值异常 FE_OVERFLOW 抛出上溢异常 FE_UNDERFLOW 抛出下溢异常 FE_ALL_EXCEPT 实现支持的所有浮点异常的按位或 FE_DOWNWARD 向下舍入 FE_TONEAREST 向最近的舍入 FE_TOWARDZERO 趋 0 舍入 FE_UPWARD 向上舍入 FE_DFL_ENV 表示默认环境,类型是 const fenv_t * 函数
函数原型 描述 void feclearexcept(int excepts); 清理 excepts 表示的异常 void fegetexceptflag(fexcept_t *flagp,int excepts); 把 excepts 指明的浮点状态标志存储在 flagp 指向的对象中 void feraiseexcept (int excepts); 抛出 excepts 指定的异常 void fesetexceptflag(const fexcept_t *flagp,int excepts); 把 excepts 指明的浮点状态标志设置为 flagp 的值;在此之前,fegetexceptflag()调用应该设置 flagp 的值 int fetestexcept (int excepts); 测试 excepts 指定的状态标志;该函数返回指定状态标志的按位或 int fegetround (void); 返回当前的舍入方向 int fesetround(int round); 把舍入方向设置为 round 的值;当且仅当设置成功时,函数返回 0 void fegetenv (fenv_t *envp); 把当前环境存储至 envp 指向的位置中 int feholdexcept (fenv_t *envp); 把当前浮点环境存储至 envp 指向的位置中,清除浮点状态标志,然后如果可能的话就设置非停模式(nonstop mode).,在这种模式中即使发生异常也继续执行。当且仅当执行成功时,函数返回 0 void fesetenv(const fenv_t *envp); 建立 envp 表示的浮点环境;envp 应指向一个之前通过调用 fegetenv()、feholdexcept()或浮点环境宏设置的数据对象 void feupdateenv(const fenv_t *envp); 函数在自动存储区中存储当前抛出的异常,建立 envp 指向的对象表示的浮点环境,然后抛出已存储的浮点异常;envp 应指向一个之前通过调用 fegetenv()、feholdexcept()或浮点环境宏设置的数据对象
浮点特性
float.h宏
宏 含义 FLT_ROUNDS 默认舍入方案 FLT_EVAL_METHOD 浮点表达式求值的默认方案 FLT_HAS_SUBNORM 存在或缺少 float 类型的反常值 DBL_HAS_SUBNORM 存在或缺少 double 类型的反常值 LDBL_HAS_SUBNORM 存在或缺少 long double 类型的反常值 FLT_RADIX 指数表示法中使用的进制数(b),最小值为 2 FLT_MANT_DIG 以 FLT_RADIX 进制表示的 float 类型数的位数(模型中的 p) DBL_MANT_DIG 以 FLT_RADIX 进制表示的 double 类型数的位数(模型中的 p) LDBL_MANT_DIG 以 FLT_RADIX 进制表示的 long double 类型数的位数(模型中的 p) FLT_DECIMAL_DIG 在 b 进制和十进制相互转换不损失精度的前提下,float 类型的十进制数的位数(最小值是 6) DBL_DECIMAL_DIG 在 b 进制和十进制相互转换不损失精度的前提下,double 类型的十进制数的位数(最小值是 10) LDBL_DECIMAL_DIG 在 b 进制和十进制相互转换不损失精度的前提下,long double 类型的十进制数的位数(最小值是 10) DECIMAL_DIG 在 b 进制与十进制相互转换不损失精度的前提下,浮点类型十进制数的最大个数(最小值为 10) FLT_DIG 在不损失精度的前提下,float 类型可表示的十进制数位数(最小值为 6) DBL_DIG 在不损失精度的前提下,double 类型可表示的十进制数位数(最小值为 10) LDBL_DIG 在不损失精度的前提下,long double 类型可表示的十进制数位数(最小值为 10) FLT_MIN_EXP float 类型 e 表示法,指数的最小负正整数值 DBL_MIN_EXP double 类型 e 表示法,指数的最小负正整数值 LDBL_MIN_EXP long double 类型 e 表示法,指数的最小负正整数值 FLT_MIN_10_EXP 用 10 的 x 次幂表示规范化 float 类型数时,x 的最小负整数值(不超过-37) DBL_MIN_10_EXP 用 10 的 x 次幂表示规范化 double 类型数时,x 的最小负整数值(不超过-37) LDBL_MIN_10_EXP 用 10 的 x 次幂表示规范化 long double 类型数时,x 的最小负整数值(不超过-37) FLT_MAX_EXP float 类型 e 表示法,指数的最大正整数值 DBL_MAX_EXP double 类型 e 表示法,指数的最大正整数值 LDBL_MAX_EXP long double 类型 e 表示法,指数的最大正整数值 FLT_MAX_10_EXP 用 10 的 x 次幂表示规范化 float 类型数时,x 的最大正整数值(至少+37) DBL_MAX_10_EXP 用 10 的 x 次幂表示规范化 double 类型数时,x 的最大正整数值(至少+37) LDBL_MAX_10_EXP 用 10 的 x 次幂表示规范化 long double 类型数时,x 的最大正整数值(至少+37) FLT_MAX float 类型的最大有限值(至少 1E+37) DBL_MAX double 类型的最大有限值(至少 1E+37) LDBL_MAX long double 类型的最大有限值(至少 1E+37) FLT_EPSILON float 类型比 1 大的最小值与 1 的差值(不超过 1E-9) DBL_EPSILON double 类型比 1 大的最小值与 1 的差值(不超过 1E-9) LDBL_EPSILON long double 类型比 1 大的最小值与 1 的差值(不超过 1E-9) FLT_MIN 标准化 float 类型的最小正值(不超过 1E-37) DBL_MIN 标准化 double 类型的最小正值(不超过 1E-37) LDBL_MIN 标准化 long double 类型的最小正值(不超过 1E-37) FLT_TRUE_MIN float 类型的最小正值(不超过 1E-37) DBL_TRUE_MIN double 类型的最小正值(不超过 1E-37) LDBL_TRUE_MIN long double 类型的最小正值(不超过 1E-37)
整型格式转换
inttypes.h函数
函数原型 描述 intmax_t imaxabs(intmax_t j); 返回 j 的绝对值 imaxdiv_t imaxdiv(intmax_t numer,intmax_t denom); 单独计算 numer/denom 的商和余数,并把两个计算结果存储在返回的结构中 intmax_t strtoimax(const char *restrict nptr,char **restrict endptr,int base); 相当于 strtol()函数,但是该函数把字符串转换成 intmax_t 类型并返回该值 uintmax_t strtoumax(const char *restrict nptr,char **restrict endptr,int base); 相当于 strtoul()函数,但是该函数把字符串转换成 intmax_t 类型并返回该值 intmax_t wcstoimax(const wchar_t *restrict nptr,wchar_t **restrict endptr,int base); strtoimax()函数的 wchar_t 类型的版本 uintmax_t wcstoumax(const wchar_t *restrict nptr,wchar_t **restrict endptr,int base); strtoumax()函数的 wchar_t 类型的版本
可选拼写
iso646.h宏
宏 运算符 宏 运算符 宏 运算符 and && or_eq |= bitor | or || not != xor ^ not ! compl ~ xor_eq ^= and_eq &= bitand &
本地化
locale.h函数
函数原型 描述 char *setlocale(int category, const char *locale); 该函数把某些值设置为本地和 locale 指定的值。category 的值决定要设置哪些本地值(后附)。如果成功设置本地化,该函数将返回一个在新本地化中与指定类别相关联的指针;如果不能完成本地化请求,则返回空指针 struct lconv *localeconv(void); 返回一个指向 struct lconv 类型结构(后附)的指针,该结构中存储着当前的本地值 category 宏
宏 描述 NULL 本地化设置不变,返回指向当前本地化的指针 LC_ALL 改变所有的本地值 LC_COLLATE 改变 strcoll()和 strxfrm()所用的排列顺序的本地值 LC_CTYPE 改变字符处理函数和多字节函数的本地值 LC_MONETARY 改变货币格式信息的本地值 LC_NUMERIC 改变十进制小数点符号和格式化 I/O 使用的非货币格式本地值 LC_TIME 改变 strftime()所用的时间格式本地值 struct lconv 成员
成员变量 描述 char *decimal_point 非货币值的小数点字符 char *thousands_sep 非货币值中小数点前面的千位分隔符 char *grouping 一个字符串,表示非货币量中每组数字的大小 char *int_curr_symbol 国际货币符号 char *currency_symbol 本地货币符号 char *mon_decimal_point 贷币值的小数点符号 char *mon_thousands_sep 货币值的千位分隔符 char *mon_grouping 一个字符串,表示货币量中每组数字的大小 char *positive_sign 指明非负格式化货币值的字符串 char *negative_sign 指明负格式化货币值的字符串 char int_frac_digits 国际格式化货币值中,小数点后面的数字个数 char frac_digits 本地格式化货币值中,小数点后面的数字个数 char p_cs_precedes 如果该值为 1,则 currency_symbol 在非负格式化货币值的前面;如果该值为 0,则 currency_symbol 在非负格式化货币值的后面 char p_sep_by_space 如果该值为 1,则用空格把 currency_symbol 和非负格式化货币值隔开;如果该值为 0,则不用空格分隔 currency_symbol 和非负格式化货币值 char n_cs_precedes 如果该值为 1,则 currency_symbol 在负格式化货币值的前面;如果该值为 0,则 currency_symbol 在负格式化货币值的后面 char n_sep_by_space 如果该值为 1,则用空格把 currency_symbol 和负格式化货币值隔开;如果该值为 O,则不用空格分隔 currency_symbol 和负格式化货币值 char p_sign_posn 其值表示 positive_sign 字符串的位置:0 表示用圆括号把数值和货币符号括起来;1 表示字符串在数值和货币符号前面;2 表示字符串在数值和货币符号后面;3 表示直接把字符串放在货币前面;4 表示字符串紧跟在货币符号后面 char n_sign_posn 其值表示 negative_sign 字符串的位置,含义与 p_sign_posn 相同 char int_p_cs_precedes 如果该值为 1,则 int_currency_symbol 在非负格式化货币值的前面;如果该值为 O,则 int_currency_symbol 在非负格式化货币值的后面 char int_p_sep_by_space 如果该值为 1,则用空格把 int_currency_symbol 和非负格式化货币值隔开;如果该值为 0,则不用空格分隔 int_currency_symbol 和非负格式化货币值 char int_n_cs_precedes 如果该值为 1,则 int_currency_symbol 在负格式化货币值的前面;如果该值为 O,则 int_currency_symbol 在负格式化货币值的后面 char int_n_sep_by_space 如果该值为 1,则用空格把 int_currency_symbol 和负格式化货币值隔开;如果该值为 0,则不用空格分隔 int_currency_symbol 和负格式化货币值 char int_p_sign_posn 其值表示 positive_sign 相对于非负国际格式化货币值的位置 char int_n_sign_posn 其值表示 negative_sign 相对于负国际格式化货币值的位置
数学库
cmath.h宏
宏 描述 HUGE_VAL 正双精度常量,不一定能用浮点数表示;在过去,函数的计算结果超过了可表示的最大值时,就用它作为函数的返回值 HUGE_VALF 与 HUGE_VAL 类似,适用于 float 类型 HUGE_VALL 与 HUGE_VAL 类似,适用于 long double 类型 INFINITY 如果允许的话,展开为一个表示无符号或正无穷大的常量 float 表达式;否则,展开为一个在编译时溢出的正浮点常量 NAN 当且仅当实现支持 float 类型的 NaN 时才被定义(NaN 是 Not-a-Number 的缩写,表示“非数”,用于处理计算中的错误情况,如除以 0.0 或求负数的平方根) FP_INFINITE 分类数,表示一个无穷大的浮点值 FP_NAN 分类数,表示一个不是数的浮点值 FP_NORMAL 分类数,表示一个正常的浮点值 FP_SUBNORMAL 分类数,表示一个低于正常浮点值的值(精度被降低) FP_ZERO 分类数,表示 0 的浮点值 FP_FAST_FMA (可选)如果已定义,对于 double 类型的运算对象,该宏表明 fma()函数与先乘法运算后加法运算的速度相当或更快 FP_FAST_FMAF (可选)如果已定义,对于 double 类型的运算对象,该宏表明 fmaf()函数与先乘法运算后加法运算的速度相当或更快 FP_FAST_FMAL (可选)如果已定义,对于 long double 类型的运算对象,该宏表明 fmall()函数与先乘法运算后加法运算的速度相当或更快 FP_ILOGB0 整型常量表达式,表示 ilogn(0)的返回值 FP_ILOGBNAN 整型常量表达式,表示 ilogn(NaN)的返回值 MATH_ERRNO 展开为整型常量 1 MATH_ERREXCEPT 展开为整型常量 2 math_errhandling 值为 MATH_ERRNO、MATH_ERREXCEPT 或这两个值的按位或 函数(C99 另有 float 和 long double 版本,在函数名后加上 f 或 l 即可切换,常量 FLT_RADIX 表示内部浮点表示法中幂的底数)
函数原型 描述 int classify(real-floating x); C99 宏,返回适合 x 的浮点分类值 int isfinite(real-floating x); C99 宏,当且仅当 x 为有穷时返回一个非 0 值 int isfin(real-floating x); C99 宏,当且仅当 x 为无穷时返回一个非 0 值 int isnan (real-floating x); C99 宏,当且仅当 x 为 NaN 时返回一个非 0 值 int isnormal(real-floating x); C99 宏,当且仅当 x 为正常数时返回一个非 0 值 int signbit(real-floating x); C99 宏,当且仅当 x 的符号为负时返回一个非 0 值 double acos (double x); 返回余弦为 x 的角度(0 ~ π 弧度) double asin(double x); 返回正弦为 x 的角度(-π/2 ~ π/2 弧度) double atan(double x); 返回正切为 x 的角度(-π/2 ~ π/2 弧度) double atan2(double y,double x); 返回正切为 y/x 的角度(-π ~ π 弧度) double cos(double x); 返回 x(弧度)的余弦值 double sin(double x); 返回 x(弧度)的正弦值 double tan (double x); 返回 x(弧度)的正切值 double cosh(double x); 返回 x 的双曲余弦值 double sinh(double x); 返回 x 的双曲正弦值 double tanh(double x); 返回 x 的双曲切值 double exp(double x); 返回 e 的 x 次幂(ex) double exp2(double x); 返回 2 的 x 次幂(2x) double expml(double x); 返回 ex-1(C99) double frexp(double v,int *pt_e); 把 v 的值分成两部分,一个是返回的规范化小数;一个是 2 的幂,存储在 pt_e 指向的位置上 int ilogb(double x); 以 signed int 类型返回 x 的指数(C99) double ldexp(double x,int p); 返回 x 乘以 2 的 p 次幂(即 x*2p) double log(double x); 返回 x 的自然对数 double log10(double x); 返回以 10 为底 x 的对数 double log1p(double x); 返回 log(1+x)(C99) double log2(double x); 返回以 2 为底 x 的对数(C99) double logb(double x); 返回 FLT_RADIX 为底 x 的有符号对数(C99) double modf(double x,double *p); 把 x 分成整数部分和小数部分,两部分的符号相同,返回小数部分,并把整数部分存储在 p 所指向的位置上 double scalbn(double x,int n); 返回 x*FLT_RADIXn(C99) double scalbln(double x,long n); 返回 x*FLT_RADIXn(C99) double hypot(double x,double y); 返回 x 平方与 y 平方之和的平方根(C99) double pow(double x,double y); 返回 x 的 y 次幂 double sqrt(double x); 返回 x 的平方根 double cbrt(double x); 返回 x 的立方根(C99) double erf(double x); 返回 x 的误差函数(C99) double lgamma (double x); 返回 x 的伽马函数绝对值的自然对数(C99) double tgamma(double x); 返回 x 的伽马函数(C99) double fabs (double x); 返回 x 的绝对值 double ceil(double x); 返回不小于 x 的最小整数值(向上取整) double floor(double x); 返回不大于 x 的最大整数值(向下取整) double nearbyint (double x); 以浮点格式把 x 四舍五入为最接近的整数;使用浮点环境指定的舍入规则(C99) double rint(double x); 与 nearbyint()类似,但是该函数会抛出“不精确”异常 long int lrint (double x); 以 long int 格式把 x 舍入为最接近的整数;使用浮点环境指定的舍入规则(C99) longlong int llrint(double x); 以 long long int 格式把 x 舍入为最接近的整数;使用浮点环境指定的舍入规则(C99) double round(double x); 以浮点格式把 x 舍入为最接近的整数,总是四舍五入 long int lround(double x); 与 round()类似,但是该函数返回值的类型是 long int longlong int llround(double x); 与 round()类似,但是该函数返回值的类型是 long long int double trunc (double x); 以浮点格式把 x 舍入为最接近的整数,其结果的绝对值不大于 x 的绝对值(C99) int fmod(double x,double y); 返回 x/y 的小数部分,如果 y 不是 0,则其计算结果的符号与 x 相同,而且该结果的绝对值要小于 y 的绝对值 double remainder(double x,double y); 返回 × 除以 y 的余数,IEC 60559 定义为 x-n*y,n 取与 x/y 最接近的整数;如果(n-x/y)的绝对值是 1/2,n 取偶数 double remquo(double x,double y,int *quo); 返回与 remainder()相同的值;把 x/y 的整数大小求模 2k的值存储在 quo 所指向的位置中,符号与 x/y 的符号相同,其中 k 为整数,至少是 3,具体值因实现而异(C99) double copysign(double x,double y); 返回 x 的大小和 y 的符号(C99) double nan(const char *tagp); 返回以 double 类型表示的 quiet NaN;nan(“n-char-seg”)与 strtod(“NAN(n-char-seq)”,(char**)NULL)等价;nan(“”)与 strtod(“NAN()”,(char**)NULL)等价。如果不支持 quiet NaN,则返回 0 double nextafter(double x,double y); 返回 x 在 y 方向上可表示的最接近的 double 类型值;如果 x 等于 y,则返回 x(C99) double nexttoward(double x,long double y); 与 nextafter()类似,但该函数的第 2 个参数是 long double 类型;如果 x 等于 y,则返回转换为 double 类型的 y(C99) double fdim(double x,double y); 如果大于 y,则返回 x-y 的值;如果 x 小于或等于 y,则返回 0(C99) double fmax(double x,double y); 返回参数的最大值,如果一个参数是 NaN、另一个参数是数值,则返回数值(C99) double fmin(double x,double y); 返回参数的最小值,如果一个参数是 NaN、另一个参数是数值,则返回数值(C99) double fma(double x,double y, double z); 返回三元运算(x*y)+z 的大小,只在最后舍入一次(C99) int isgreater(real-floating x, real-floating y); C99 宏,返回(x)>(y)的值,如果有参数是 NaN,不会抛出无效浮点异常 int isgreaterequal(real-floating x,real-floating y); C99 宏,返回(x)>=(y)的值,如果有参数是 NaN,不会抛出无效浮点异常 int isless(real-floating x,real-floating y); C99 宏,返回(x)<(y)的值,如果有参数是 NaN,不会抛出无效浮点异常 int islessequal(real-floating x,real-floating y); C99 宏,返回(x)<=(y)的值,如果有参数是 NaN,不会抛出无效浮点异常 int islessgreater(real-floating x,real-floating y); C99 宏,返回(x)<(y) || (x)>(y)的值,如果有参数是 NaN,不会抛出无效浮点异常 int isunordered(real-floating x,real-floating y); 如果参数不按顺序排列(至少有一个参数是 NaN),函数返回 1;否则,返回 0
非本地跳转
setjmp.h函数
函数原型 描述 int setjmp(jmp_buf env); 把调用环境存储在数组 env 中,如果是直接调用,则返回 0;如果是通过 longjmp()调用,则返回非 0 void longjmp(jmp_buf env,int val); 恢复最近的 setjmp()调用(设置 env 数组)存储的环境;完成后,程序继续像调用 setjmp()那样执行该函数,返回 val(但是该函数不允许返回 0,会将其转换成 1)
对齐
stdalign.h宏
宏 描述 alignas 展开为关键字_Alignas alignof 展开为关键字_Alignof __alignas_is_defined 展开为整型常量 1,适用于#if __alignof_is_defined 展开为整型常量 1,适用于#if
可变参数
stdarg.h宏
宏 描述 void va_start(va_list ap,parmN); 该宏在 va_arg()和 va_end()使用 ap 之前初始化 ap,parmN 是形参列表中最后一个形参名的标识符 type va_arg(va_list ap,type); 该宏展开为一个表达式,其值和类型都与 ap 表示的形参列表的下一项相同,type 是该项的类型。每次调用该宏都前进到 ap 中的下一项 void va_end(va_list ap); 该宏关闭以上过程,可能导致 ap 在再次调用 va_start()之前不可用 void va_copy(va list dest,va list src); 该宏把 dest 初始化为 srt 当前状态的备份(C99)
布尔支持
stdbool.h宏
宏 描述 bool 展开为_Bool false 展开为整型常量 0 true 展开为整型常量 1 __bool_true_false_are_defined 展开为整型常量 1
通用定义
stddef.h类型
类型 描述 ptrdiff_t 有符号整数类型,表示两个指针之差 size_t 无符号整数类型,表示 sizeof 运算符的结果 wchar_t 整数类型,表示支持的本地化所指定的最大扩展字符集 宏
宏 描述 NULL 实现定义的常量,表示空指针 offsetof(type,member-designator) 展开为 size_t 类型的值,表示 type 类型结构的指定成员在该结构中的偏移量,以字节为单位。如果成员是一个位字段,该宏的行为是未定义的
整数类型
stdint.h精确宽度类型
typedef 名 属性 int8_t 8 位,有符号 intl6_t 16 位,有符号 int32_t 32 位,有符号 int64_t 64 位,有符号 uint8_t 8 位,无符号 uint16_t 16 位,无符号 uint32_t 32 位,无符号 uint64_t 64 位,无符号 最小宽度类型
typedef 名 属性 int_least8_t 至少 8 位,有符号 int_least16_t 至少 16 位,有符号 int_least32_t 至少 32 位,有符号 int_least64_t 至少 64 位,有符号 uint_least8_t 至少 8 位,无符号 uint_least16_t 至少 16 位,无符号 uint_least32_t 至少 32 位,无符号 uint_least64_t 至少 64 位,无符号 最快最小宽度类型
typedef 名 属性 int_fast8_t 至少 8 位有符号 int_fast16_t 至少 16 位有符号 int_fast32_t 至少 32 位有符号 int_fast64_t 至少 64 位有符号 uint_fast8_t 至少 8 位无符号 uint_fast16_t 至少 16 位无符号 uint_fast32_t 至少 32 位无符号 uint_fast64_t 至少 64 位无符号 最大宽度类型
typedef 名 属性 intmax_t 最大宽度的有符号类型 uintmax_t 最大宽度的无符号类型 可存储指针值的整数类型
typedef 名 属性 intptr_t 可存储指针值的有符号类型 uintptr_t 可存储指针值的无符号类型 整型常量
常量标识符 最小值 INTN_MIN 等于-(2n-1-1) INTN_MAX 等于 2n-1-1 UINTN_MAX 等于 2n-1-1 INT_LEASTN_MIN -(2n-1-1) INT_LEASTN_MAX 2n-1-1 UINT_LEASTN_MAX 2n-1 INT_FASTN_MIN -(2n-1-1) INT_FASTN_MAX 2n-1-1 UINT_FASN_MAX 2n-1 INTPTR_MIN -(215-1) INTPTR_MAX 215-1 UINTPTR_MAX 216-1 INTMAX_MIN -(215-1) INTMAX_MAX 263-1 UINTMAX_MAX 264-1 其他整型常量
常量标识符 含义 PTRDIFF_MIN ptrdiff_t 类型的最小值 PTRDIFF_MAX ptrdiff_t 类型的最大值 SIG_ATOMIC_MIN sig_atomic_t 类型的最小值 SIG_ATOMIC_MAX sig_atomic_t 类型的最大值 WCHAR_MIN wchar_t 类型的最小值 WCHAR_MAX wchar_t 类型的最大值 WINT_MIN wint_t 类型的最小值 WINT_MAX wint_t 类型的最大值 SIZE_MAX size_t 类型的最大值
标准 I/O 库
stdio.h函数
函数原型 描述 void clearerr(FILE *); 清除文件结尾和错误指示符 int fclose(FILE *); 关闭指定的文件 int feof(FILE *); 测试文件结尾 int ferror(FILE *); 测试错误指示符 int fflush(FILE *); 刷新指定的文件 int fgetc(FILE *); 获得指定输入流的下一个字符 int fgetpos(FILE *restrict,restrict); 存储文件位置指示符的 fpos_t*当前值 char fgets(char *restrict,restrict); 从指定流中获取下一行(或 int、FILE*指定的字符数) FILE fopen(const char *restrict,const char *restrict); 打开指定的文件 int fprintf(FILE *restrict,const char *restrict, …); 把格式化输出写入指定流 int fputc(int,FILE *); 把指定字符写入指定流 int fputs(const char *restrict,FILE *restrict); 把第 1 个参数指向的字符串写入指定流 size_t fread(void *restrict,size_t,size_t,FILE *restrict); 读取指定流中的二进制数据 FILE freopen(const char *restrict,const char *restrict,FILE *restrict); 打开指定文件,并将其与指定流相关联 int fscanf(FILE *restrict,const char *restrict,…); 读取指定流中的格式化输入 int fsetpos(FILE *,const fpos_t *); 设置文件位置指针指向指定的值 int fseek(FILE *long,int); 设置文件位置指针指向指定的值 long ftell(FILE *); 获取当前文件位置 size_t fwrite(const void *restrict,size_t,size_t,FILE *restrict); 把二进制数据写入指定流 int getc(FILE *); 读取指定输入的下一个字符 int getchar(); 读取标准输入的下一个字符 char gets(char *); 获取标准输入的下一行(C11 库已删除) void perror(const char*); 把系统错误信息写入标准错误中 int printf(const char *restrict,…); 把格式化输出写入标准输出中 int putc(int,FILE *); 把指定字符写入指定输出中 int putchar(int); 把指定字符写入指定输出中 int puts(const char *); 把字符串写入标准输出中 int remove(const char *) 移除已命名文件 int rename(const char *,const char *) 重命名文件 void rewind(FILE *) 设置文件位置指针指向文件开始处 int scanf(const char *restrict,…); 读取标准输入中的格式化输入 void setbuf(FILE *restrict,char *restrict); 设置缓冲区大小和位置 int setvbuf(FILE *restrict,char *restrict,int,size_t); 设置缓冲区大小、位置和模式 int snprintf(char *restrict,size_t n,const char *restrict,…); 把格式化输出中的前 n 个字符写入指定字符串中 int sprintf(char *restrict,const char *restrict,…); 把格式化输出写入指定字符串中 int sscanf(const char *restrict,const char *restrict,…); 把格式化输入写入指定字符串中 FILE *tmpfile(void); 创建一个临时文件 char *tmpnam(char *); 为临时文件生成一个唯一的文件名 int ungetc(int,FILE *) 把指定字符放回输入流中 int vfprintf(FILE *restrict,const char *restrict,va_list); 与 fprintf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表 int vprintf(const char *restrict,va_list); 与 printf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表 int vsnprintf(char *restrict,size_t n,const char *restrict,va_list); 与 snprintf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表 int vsprintf(char *restrict,const char *restrict,va_list); 与 sprintf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表 int vscanf(const char *restrict,va_list); 与 scanf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表 int vsscanf(const char *restrict,*restrict,va_list); 与 sscanf()类似,但该函数用一个 va_list 类型形参列表(由 va_start 初始化)代替变量参数列表
通用工具
stdlib.h类型
类型 描述 size_t sizeof 运算符返回的整数类型 wchar_t 用于表示宽字符的整数类型 div_t div()返回的结构类型,该类型中的 quot 和 rem 成员都是 int 类型 ldiv_t ldiv()返回的结构类型,该类型中的 quot 和 rem 成员都是 long 类型 lldiv_t lldiv()返回的结构类型,该类型中的 quot 和 rem 成员都是 1ong1ong 类型(C99) 常量
常量 描述 NULL 空指针(相当于 0) EXIT_FAILURE 可用作 exit()的参数,表示执行程序失败 EXIT_SUCCESS 可用作 exit()的参数,表示成功执行程序 RAND_MAX rand()返回的最大值(一个整数) MB_CUR_MAX 当前本地化的扩展字符集中多字节字符的最大字节数 函数
函数原型 描述 double atof(const char *nptr); 返回把字符串 nptr 开始部分的数字(和符号)字符转换为 double 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0 int atoi(const char *nptr); 返回把字符串 nptr 开始部分的数字(和符号)字符转换为 int 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0 int atol(const char *nptr); 返回把字符串 nptr 开始部分的数字(和符号)字符转换为 long 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0 double strtod (const char *restrict npt,char **restrict ept); 返回把字符串 npt 开始部分的数字(和符号)字符转换为 double 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0;如果转换成功,则把数字后第 1 个字符的地址赋给 ept 指向的位置;如果转换失败,则把 npt 赋给 ept 指向的位置 float strtof(const char *restrict npt,char **restrict ept); 与 strtod()类似,但是该函数把 npt 指向的字符串转换为 float 类型的值(C99) long double strtols(const char *restrict npt,char **restrict ept); 与 strtod()类似,但是该函数把 npt 指向的字符串转换成 long double 类型的值(C99) long strtol(const char *restrict npt, char **restrict ept,int base); 返回把字符串 npt 开始部分的数字(和符号)字符转换成 long 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0;如果转换成功,则把数字后第 1 个字符的地址赋给 ept 指向的位置;如果转换失败,则把 npt 赋给 ept 指向的位置;假定字符串中的数字以 base 指定的数为基数 longlong strtoll (const char *restrict npt,char **restrict ept,int base); 与 strtol()类似,但是该函数把 npt 指向的字符串转换为 long long 类型的值(C99) unsigned long strtoul (const char *restrict npt,char **restrict ept,int base); 返回把字符串 npt 开始部分的数字(和符号)字符转换为 unsigned long 类型的值,跳过开始的空白,遇到第 1 个非数字字符时结束转换;如果未发现数字则返回 0;如果转换成功,则把数字后第 1 个字符的地址赋给 ept 指向的位置;如果转换失败,则把 npt 赋给 ept 指向的位置;假定字符串中的数字以 base 指定的数为基数 unsigned long long strtoull(const char *restrict npt,char **restrict ept,int base); 与 strtoul()类似,但是该函数把 npt 指向的字符串转换为 unsigned long long 类型的值(C99) int rand(void); 返回 O~RAND_MAX 范围内的一个伪随机整数 void srand(unsigned int seed); 把随机数生成器种子设置为 seed,如果在调用 rand()之前调用 srand(),则种子为 1 void *aligned_alloc(size_t algn,size_t size); 为对齐对象 algn 分配 size 字节的空间,应支持 algn 对齐值,size 应该是 algn 的倍数(C11) void *calloc(size_t nmem,size_t size); 为内含 nmem 个成员的数组分配空间,每个元素占 size 字节大;空间中的所有位都初始化为 0;如果操作成功,该函数返回数组的地址,否则返回 NULL void *malloc(size_t size); 分配 size 字节的未初始化内存块;如果成功分配,该函数返回数组的地址,否则返回 NULL void *realloc(void *ptr,size_t size); 把 ptr 指向的内存块大小改为 size 字节,size 字节内的内存块内容不变。该函数返回块的位置,它可能被移动。如果不能重新分配空间,函数返回 NULL,原始块不变;如果 ptr 为 NULL,其行为与调用带 size 参数的 malloc()相同;如果 size 是 0,且 ptr 不是 NULL,其行为与调用带 ptr 参数的 free()相同 void free(void *ptr); 释放 ptr 指向的空间,ptr 应该是之前调用 calloc()、malloc()或 realloc()返回的值,或者 ptr 也可以是空指针,出现这种情况时什么也不做。如果 ptr 是其他值,其行为是未定义的 void abort(void); 除非捕获信号 SIGABRT,且相应的信号处理器没有返回,否则该函数将导致程序异常结束。是否关闭 I/0 流和临时文件,因实现而异。该函数执行 raise(SIGABRT) int atexit(void(*func)(void)); 注册 func 指向的函数,使其在程序正常结束时被调用。实现应支持注册至少 32 个函数,并根据它们注册顺序的逆序调用。如果注册成功,函数返回 0;否则返回非 0 int at_quick_exit(void (*func)(void)); 注册 func 指向的函数,如果调用 quick exit()则调用被注册的函数。实现应支持注册至少 32 个函数,并根据它们注册顺序的逆序调用。如果注册成功,函数返回 0;否则返回非 0(C11) void exit(int status); 该函数将正常结束程序。首先调用由 atexit()注册的函数,然后刷新所有打开的输出流、关闭所有的 I/0 流、关闭 tmpfile()创建的所有文件,并把控制权返回主机环境中;如果 status 是 0 或 EXIT SUCCESS,则返回一个实现定义的值,表明未成功结束程序 void _Exit(int status); 与 exit()类似,但是该函数不调用 atexit()注册的函数和 signal()注册的信号处理器,其处理打开流的方式依实现而异 char *getenv(const char *name); 返回一个指向字符串的指针,该字符串表示 name 指向的环境变量的值。如果无法匹配指定的 name,则返回 NULL _Noreturn void quick_exit(int status); 该函数将正常结束程序。不调用 atexit()注册的函数和 signal()注册的信号处理器。根据 at_quick_exit()注册函数的顺序,逆序调用这些函数。如果程序多次调用 quick_exit()或者同时调用 quick_exit()和 exit(),其行为是未定义的。通过调用_Exit(status)将控制权返回主机环境(C11) int system(const char *str); 把 str 指向的字符串传递给命令处理器(如 DOS 或 UNIX)执行的主机环境。如果 str 是 NULL 指针,且命令处理器可用,则该函数返回非 O,否则返回 0;如果 str 不是 NULL,返回值依实现而异 void *bsearch(const void *key,const void *base,size_t nmem,size_t size,int(*comp)(const void *,const void*)); 查找 base 指向的一个数组(有 nmem 个元素,每个元素的大小为 size)中是否有元素匹配 key 指向的对象。通过 comp 指向的函数比较各项,如果 key 指向的对象小于数组元素,那么比较函数将返回小于 0 的值;如果两者相等,则返回 0;如果 key 指向的对象大于数组元素,则返回大于 0 的值。该函数返回指向匹配元素的指针或 NULL(如果无匹配元素)。如果有多个元素匹配,未定义返回哪一个元素 void qsort(void *base,size_t nmem,size_t size,int(*comp)(const void*,const void*)); 根据 comp 指向的函数所提供的顺排列 base 指向的数组。该数组有 nmem 个元素,每个元素的大小是 size。如果第 1 个参数指向的对象小于数组元素,那么比较函数将返回小于 0 的值;如果两者相等,则返回 0;如果第 1 个参数指向的对象大于数组元素,则返回大于 0 的值 int abs (int n); 返回 n 的绝对值。如果 n 是负数但没有与之对应的正数,那么返回值是未定义的(当 n 是以二进制补码表示的 INT_MIN 时,会出现这种情况) long labs(int n); 返回 n 的绝对值,如果 n 是负数但没有与之对应的正数,那么返回值是未定义的(当 n 是以二进制补码表示的 LONG_MIN 时,会出现这种情况) long long llabs(int n); 返回 n 的绝对值,如果 n 是负数但没有与之对应的正数,那么返回值是未定义的(当 n 是以二进制补码表示的 LONG_LONG_MIN 时,会出现这种情况) div t_div(int numer,int denom); 计算 number 除以 denom 的商和余,把商和余数分别存储在 divt 结构的 quot 成员和 rem 成员中。对于无法整除的除法,商要趋零截断(即直接截去小数部分) ldiv_t ldiv(long numer,long denom); 计算 number 除以 denom 的商和余,把商和余数分别存储在 ldiv_t 结构的 guot 成员和 rem 成员中。对于无法整除的除法,商要趋零截断(即直接截去小数部分) lldiv_t lldiv(long numer,long denom); 计算 number 除以 denom 的商和余,把商和余数分别存储在 lldiv_t 结构的 quot 成员和 rem 成员中。对于无法整除的除法,商要趋零截断(即直接截去小数部分)(C99) int mblen(const char *s,size_t n); 返回组成 s 指向的多字节字符的字节数(最大为 n)。如果 s 指向空字符,该函数则返回 0;如果 s 未指向多字节字符,则返回-1;如果 s 是 NULL,且多字节根据状态进行编码,该函数则返回非 0,否则返回 0 int mbtowc(wchar_t *pw,const char *s,size_t n); 如果 s 不是 NULL,该函数确定了组成 s 指向的多字节字符的字节数(最大为 n),并确定字符的 wchar_t 类型编码。如果 pw 不是 NULL,则把类型编码赋给 pw 指向的位置。返回值与 mblen(s,n)相同 int wctomb(char *s,wchar_t wc); 把 wc 中的字符代码转换成相应的多字节字符表示,并将其存储在 s 指向的数组中,除非 s 是 NULL。如果 s 不是 NULL,且如果 wc 无法转换成相应的有效多字节字符,该函数返回-1;如果 wc 有效,该函数返回组成多字节的字节数;如果 s 是 NULL,且如果多字节字符根据状态进行编码,该函数则返回非 0,否则返回 0 size_t mbstowcs(wchar_t *restrict pwcs,const char *srestrict,size_t n); 把 s 指向的多字节字符数组转换成存储在 pwcs 开始位置的宽字符编码数组中,转换 pwcs 数组中的 n 个字符或转换到 s 数组的空字节停止。如果遇到无效的多字节字符,该函数返回(size_t)(-1),否则返回已填充的数组元素个数(如果有空字符,不包含空字符) size_t wcstombs(char *restricts,const wchart_t *restrict pwcs,size_t n); 把存储在 pwcs 指向数组中的宽字符编码序列转换成一个多字节字符序列,并把它拷贝到 s 指向的位置上,存储个字节或遇到空字符时停止转换。如果遇到无效的宽字符编码,该函数返回(size_t)(-1),否则返回已填充数组的字节数(如果有空字符,不包含空字符)
处理字符串
string.h函数
函数原型 描述 void *memchr(const void *s,int c,size_t n); 在 s 指向对象的前 n 个字符中查找是否有 c。如果找到,则返回首次出现 c 处的指针,如果未找到则返回 NULL int memcmp(const void *s1,const void *s2,size_t n); 比较 s1 指向对象中的前 n 个字符和 s2 指向对象的前 n 个字符,每个值都解释为 unsigned char 类型。如果 n 个字符都匹配,则两个对象完全相同;否则,比较两个对象中首次不匹配的字符对。如果两个对象相同,函数返回 0;如果在数值上第 1 个对象小于第 2 个对象,函数返回小于 0 的值;如果在数值上第 1 个对象大于第 2 个对象,函数返回大于 0 的值 void *memcpy(void *restrict s1,const void *restrict s2,size_t n); 把 s2 所指向位置上的 n 字节拷贝到 s1 指向的位置上,函数返回 s1 的值。如果两个位置出现重叠,其行为是未定义的 void *memmove(void *s1,const void *s2,size_t n); 把 s2 所指向位置上的 n 字节拷贝到 s1 指向的位置上,其行为与拷贝类似,返回 s1 的值。但是,如果出现局部重叠情况,该函数会先把重叠的内容拷贝至临时位置 void *memset (void *s,int v,size_t n); 把 v 的值(转换为 unsigned char)拷贝至 s 指向的前 n 字节中,函数返回 s char *strcat(char *restrict s1,const char *restrict s2); 把 s2 指向的字符串拷贝到 s1 指向字符串后面,s2 字符串的第 1 个字符覆盖 s1 字符串的空字符。该函数返回 s1 char *strncat(char *restrict s1,const char *restrict s2,size_t n); 把 s2 指向字符串的 n 个字符拷贝到 s1 指向的字符串后面(或拷贝到 s2 的空字符为止)。s2 字符串的第 1 个字符覆盖 s1 字符串的空字符。函数返回 s1 char *strcpy(char *restrict s1,const char *restrict s2); 把 s2 指向的字符串拷贝到 s1 指向的位置。函数返回 s1 char *strncpy(char *restrict s1,const char *restrict s2,size_t n); 把 s2 指向字符串的 n 个字符拷贝到 s1 指向的位置(或拷贝到 s2 的空字符为止)。如果在拷贝 n 个字符之前遇到空字符,则在拷贝字符后面添加若干个空字符,使其长度为 n;如果拷贝 n 个字符没有遇到空字符,则不添加空字符。函数返回 s1 int strcmp(const char *s1,const char *s2); 比较 s1 和 s2 指向的两个字符串。如果完全匹配,则两字符串相同,否则比较首次出现不匹配的字符对。通过字符编码值比较字符。如果两个字符串相同,函数返回 0;如果第 1 个字符串小于第 2 个字符串,函数返回小于 0 的值;如果第 1 个字符串大于第 2 个字符串,函数返回大于 0 的值 int strncmp(const char *s1,const char *s2,size_t n); 比较 s1 和 s2 指向数组中的前 n 个字符,或比较到第 1 个空字符位置。如果所有的字符对都匹配,则两个数组相同,否则比较两个数组中首次不匹配的字符对。通过字符编码值比较字符。如果两个数组相同,函数返回 0;如果第 1 个数组小于第 2 个数组,函数返回小于 0 的值;如果第 1 个数组大于第 2 个数组,函数返回大于 0 的值 int strcoll(const char *s1,const char *s2); 与 strcmp()类似,但是该函数使用当前本地化的 LC_COLLATE 类别(由 setlocale()函数设置)所指定的排序方式进行比较 size_t strxfrm(char *restrict s1,const char *restrict s2,size_t n); 转换 s2 中的字符串,并把转换后的前 n 个字符(包括空字符)拷贝到 s1 指向的数组中。用 strcmp()比较转换后的两个字符串的结果和用 strcoll()比较两个未转换字符串的结果相同。函数返回转换后的字符串长度(不包括末尾的空字符) char *strchr(const char *s,int c); 查找 s 指向的字符串中首次出现 c 的位置。空字符是字符串的一部分。函数返回一个指针,指向首次出现 c 的位置。如果没有找到指定的 c 则返回 NULL size_t strcspn(const char *s1,const char *s2); 返回 s1 中未出现 s2 中任何字符的最大起始段长度 size_t strspn(const char *s1,const char *s2); 返回 s1 中包含 s2 所有字符的最大起始段长度 char *strpbrk(const char *s1,const char *s2); 返回一个指针,指向 s1 中与 s2 任意字符匹配的第 1 个字符的位置。如果未发现任何匹配的字符,函数返回 NULL char *strrchr(const char *s,int c); 在 s 指向的字符串中查找末次出现 c 的位置(即从 s2 右侧开始查找字符 c 首次出现的位置)。空字符是字符串的一部分。如果找到,函数返回指向该位置的指针;如果未找到,则返回 NULL char *strstr(const char *s1,const char *s2); 返回一个指针,指向 s1 中首次出现 s2 中字符序列(不包括结束的空字符)的位置。如果未找到,函数返回 NULL char *strtok(char *restrict s1,const char *restrict s2); 该函数把 s1 字符串分解为单独的记号。s2 字符串包含了作为记号分隔符的字符。按顺序调用该函数。第 1 次调用时,s1 应指向待分解的字符串。函数定位到非分隔符后的第 1 个记号分隔符,并用空字符替换它。函数返回一个指针,指向存储第 1 个记号的字符串。如果未找到记号,函数返回 NULL。在此次调用 strtok()查找字符串中的更多记号。每次调用都返回指向下一个记号的指针,如果未找到则返回 NULL char *strerror(int errnum); 返回一个指针,指向与存储在 errnum 中的错误号相对应的错误信息字符串(依实现而异) int strlen(const char *s); 返回字符串 s 中的字符数(末尾的空字除外)
通用数学函数
tgmath.h通用宏函数(不同库中可能有类型不同但功能类似的函数,该宏自动展开为对应类型)
1 2 3 4 5 6 acos asin atanb acosh asinh atanh cos sin tan cosh sinh tanh exp log pow sqrt fabs atan2 cbrt ceil copysign erf erfc exp2 expm1 fdim floor fma famx fmin fmod frexp hypot ilogb ldexp lgamma llrint llround log10 log1p log2 logb lrint lround nearbyint nextafter nexttoward remainder remquo rint round scalbn scalbln tgamma trunc carg cimag conj cproj creal
日期和时间
time.h类型
类型 描述 size_t sizeof 运算符返回的整数类型 clock_t 适用于表示时间的算术类型 time_t 适用于表示时间的算术类型 struct timespec 以秒和纳秒为单位存储指定时间间隔的结构(C11) struct tm 存储日历时间的各部分 timespec 结构成员
成员 描述 time_t tv_sec 秒(>=0) long tv_nsec 纳秒([0, 999999999]) tm 结构成员
成员 描述 int tm_sec 分后的秒(0-61) int tm_min 小时后的分(0-59) int tm_hour 小时(0-23) int tm_mday 一个月的天数(0-31) int tm_mon 一月后的月数(0-11) int tm_year 1900 年后的年数 int tm_wday 星期日开始的天数(0-6) int tm_yday 从 1 月 1 日开始的天数(0-365) int tm_isdst 夏令时标志(大于 0 说明夏令时有效,等于 0 说明无效,小于 0 说明信息不可用) 函数
函数原型 描述 clock_t clock(void); 该函数返回实现从开始执行程序到调用该函数时,处理器经过的最接近的时间。该函数的返回值除以 CLOCK_PER_SEC 得到以秒为单位的时间。如果时间不可用或无法表示,函数返回(clock_t)(-1) double difftime(time_t t1,time_t t0); 返回两个日历时间(t1-t0)的差值。该函数返回计算结果,单位是秒 time_t mktime(struct tm *tmptr); 把 tmptr 指向的结构中的分解时间转换为日历时间。其编码与 time()函数相同,但是结构改变了,以便对结构中超出范围的值进行调整(例如,2 分 100 秒会调整为 4 分 40 秒),而且把 tm_wday 和 tm_yday 设置为其他成员指定的值。如果无法表示日历时间,该函数返回(time_t)(-1);否则以 time_t 格式返回日历时间 time_t time(time_t *ptm) 返回当前日历时间,并将其存储在 ptm 指向的位置,假设 ptm 不是空指针。如果日期时间不可用,该函数返回(time_t)(-1) int timespec_get(struct timespec *ts,int base); 根据指定的时基,把 ts 指向的结构设置为当前日历时间。如果成功,返回 base(非 0 值),否则返回 0(C11) char *asctime(const struct tm *tmpt); 把 tmpt 指向的结构中的分解时间转换成”Thu Feb 26 1998\n\0”格式的字符串,并返回指向该字符串的指针 char *ctime(const time_t *ptm); 把 ptm 指向的结构中的分解时间转换成”Wed Aug 11 1999\n\0”格式的字符串,并返回指向该字符串的指针 struct tm *gmtime(const time_t *ptm); 把 ptm 指向的日历时间转换成协调世界时(UTC)表示的分解时间,返回一个指向结构的指针,该结构中储时间信息。如果 UTC 不可用,则返回 NULL struct tm *localtime(const time_t *ptm); 把 ptm 指向的日历时间转换成本地时间表示的分解时间,存储 tm 结构并返回指向该结构的指针 size_t strftime(char *restrict s,size_t max,const char *restrict fmt,const struct tm *restrict tmpt); 把字符串 fmt 拷贝到字符串 s 中,用 tmp 指向的分解时间结构中的合适数据替换 fmt 中的转换说明(见后表)。最多在 s 中放入 max 个字符。该函数返回放入 s 中的字符数(不包括空格);如果字符串中的字符数大于 max,函数返回 0,且 s 中的内容不确定 strftime()转换说明
转换说明 被替换为 %a 本地化的星期名称缩写 %A 本地化的星期名称全名 %b 本地化的月份名称缩写 %B 本地化的月份名称全名 %c 本地化指定的日期和时间 %C 年份的后两位数字(年份除以 100,取小数部分的数)(00-99) %d 十进制数表示的月份中的某天(01-31) %D 月/日/年,等价于“%m/%d/%y” %e 十进制数表示的月份中的某天,在仅一位的数字前有一个空格(1-31) %F 年-月-日,等价于“%Y-%m-%d” %g 基于周的年份的最后两位数字(00-99) %G 十进制数表示的基于周的年份 %h 等价于“%b” %H 十进制数(00-23)表示的小时(24 小时制) %I 十进制数(01-12)表示的小时(12 小时制) %j 十进制数表示的一年中的某天(001-366) %m 十进制数表示的月份(01-12) %n 换行符 %M 十进制数表示的分钟(00-59) %P 等价于本地 12 小时制中的 am/pm %r 本地的 12 小时制 %R 小时:分钟,等价于“%H:%M” %S 十进制数表示的秒(00-61) %t 水平制表符 %T 小时:分钟:秒,等价于“%H:%M:%S” %u ISO 8601 的星期数(1~7),星期一为 1 %U 一年中的周数(00~53),把星期天作为一周的第 1 天 %V ISO 8601 的一年周数(00~53),把星期天作为一周的第 1 天 %w 十进制表示的星期数(0~6),从星期天开始 %W 一年的周数(00~53),把星期一作为一周的第 1 天 %x 本地化日期表示 %X 本地化时间表示 %y 不带世纪的十进制年份(00~99) %Y 带世纪的十进制年份 %z 按照 ISO 8601 格式的相对 UTC 偏移(“-800”表示格林威治时间后的 8 小时,即是向西 8 小时),如果无可用信息则无替换字符 %Z 时区名,如果无可用信息则无替换字符 %% %(即百分号)
统一码工具
uchar.h(针对 UTF-16 和 UTF-32)类型
类型 描述 char16_t 使用 16 位字符的无符号整数类型(与 stdint.h 中的 unit_least16_t 相同) char32_t 使用 32 位字符的无符号整数类型(与 stdint.h 中的 unit_least32_t 相同) size_t sizeof 运算符(stddef.h)返回的整数类型 mbstate_t 非数组类型,可存储多字节字符序列和宽字符相互转换的转换状态信息 函数
函数原型 描述 size_t mbrto16(char16_t *restrict pwc,const char *restrict s,size_t n,mbstate_t *restrict ps); 与 mbrtowc()函数相同(wchar.h),但该函数是把字符转换为 char16_t 类型,而不是 wchar_t 类型 size_t mbrto32(char32_t *restrict pwc,const char -restrict s,size_t n,mbstate_t *restrict ps); 与 mbrto16()函数相同,但该函数是把字符转换为 char_32_t 类型 size_t c16rtomb (char *restrict s,wchar_t wc,mbstate_t *restrict ps); 与 wcrtobm()函数相同(wchar.h),但该函数转换的是 char_16_t 类型字符,而不是 wchar_t 类型 size_t c32rtomb (char *restrict s,wchar_t wc,mbstate_t *restrict ps); 与 wcrtobm()函数相同(wchar.h),但该函数转换的是 char_32_t 类型字符,而不是 wchar_t 类型
拓展多字节字符和宽字符工具
wchar.h(C99)类型
类型 描述 wchar_t 整数类型,可表示本地化支持的最大扩展字符集 wint_t 整数类型,可存储扩展字符集的任意值和至少一个不是扩展字符集成员的值 size_t sizeof 运算符返回的整数类型 mbstate_t 非数组类型,可存储多字节字符序列和宽字符之间转换所需的转换状态信息 struct tm 结构类型,用于存储日历时间的组成部分 宏
宏 描述 NULL 空指针 WCHAR_MAX wchar_t 类型可存储的最大值 WCHAR_MIN wchar_t 类型可存储的最小值 WEOF wint_t 类型的常量表达式,不与扩展字符集的任何成员对;相当于 EOF 的宽字符表示,用于指定宽字符输入的文件结尾 函数
函数原型 描述 wint_t btowc(int c); 如果在初始移位状态中 c(unsigned char)是有效的单字节字符,那么该函数返回宽字节表示;否则,返回 WEOF int wctob(wint_t c); 如果 c 是一个扩展字符集的成员,它在初始移位状态中的多字节字符表示的是单字节,该函数就返回一个转换为 int 类型的 unsigned char 的单字节表示;否则,函数返回 EOF int mbsinit(const mbstate_t *ps); 如果 ps 是空指针或指向一个指定为初始转换状态的数据对象,函数就返回非零值;否则,函数返回 0 size_t mbrlen(const char *restrict s,size_t n,mbstate_t *restrict ps); mbrlen()函数相当于调用 mbrtowc(NULL,s,n,ps!=NULL?ps:&internal),其中 internal 是 mbrlen()函数的 mbstate_t 对象,除非 ps 指定的表达式只计算一次 size_t mbrtowc(wchar_t *restrict pwc,const char *restrict s,size_t n,mbstate_t *restrict ps); 如果 s 是空指针,调用该函数相当于把 pwc 设置为空指针、把 n 设置为 1。如果 s 不是空指针,该函数最多检查字节以确定下一个完整的多字节字符所需的字节数(包括所有的移位序列)。如果该函数确定了下一个多字节字符的结束处且合法,它就确定了对应宽字符的值。然后,如果 pwc 不为空,则把值存储在 pwc 指向的对象中。如果对应的宽字符是空的宽字符,描述的最终状态就是初始转换状态。如果检测到空的宽字符,函数返回 0;如果检测到另一个有效宽字符,函数返回完整字符所需的字节数。如果字节不足以表示一个有效的宽字符,但是能表示其中的一部分,函数返回-2。如果出现编码错误,函数返回-1,并把 EILSEQ 存储在 errno 中,且不存储任何值 size_t wcrtomb(char *restrict s,wchar_t wc,mbstate_t *restrict ps); 如果 s 是空指针,那么调用该函数相当于把 wc 设置为空的宽字符,并为第 1 个参数使用内部缓冲区。如果 s 不是空指针,wcrtomb()函数则确定表示 wc 指定宽字符对应的多字节字符表示所需的字节数(包括所有移位序列),并把多字节字符表示存储在一个数组中(s 指向该数组的第 1 个元素),最多存储 MB_CUR_MAX 字节。如果 wc 是空的宽字符,就在初始移位状态所需的移位序列后存储一个空字节。描述的结果状态就是初始转换状态。如果 wc 是有效的宽字符,该函数返回存储多字节字符所需的字节数(包括指定移位状态的字节)。如果 wc 无效,函数则把 EILSEQ 存储在 errno 中,并返回-1 size_t mbsrtowcs(wchar_t *restrict dst,const char **restrict src,size_t len,mbstate_t *restrict ps); mbstrtows()函数把 src 间接指向的数组中的多字节字符序列转换成对应的宽字符序列,从口 s 指向的对象所描述的转换状态开始,一直转换到结尾的空字符(包括该字符并存储)或转换了 len 个宽字符。如果 dst 不是空指针,则待转换的字符将存储在 dst 指向的数组中。出现这两种情况时停止转换:如果字节序列无法构成一个有效的多字节字符,或者(如果 dst 不是空指针)len 个宽字符已存储在 dst 指向的数组中。每转换一次都相当于调用一次 mbrtowc()函数。如果 dst 不是空指针,就把空指针(如果因到达结尾的空字符而停止转换)或最后一个待转换多字节字符的地址赋给 src 指向的指针对象。如果由于到达结尾的空字符而停止转换,且 dst 不是空指针,那么描述的结果状态就是初始转状态。如果执行成功,函数返回成功转换的多字节字符数(不包括空字符);否则函数返回-1 size_t wcsrtombs(char *restrict dst,const wchar_t **restrict src,size_t len,mbstate_t *restrict ps); wcsrtombs()函数把 src 间接指向的数组中的宽字符序列转换成对应的多字节字符序列(从 ps 指向的对象描述的转换状态开始)。如果 dst 不是空指针,待转换的字符将被存储在 dst 指向的数组中。一直转换到结尾的空字符(包括该字符并存储)或换了 len 个多字节字符。出现这两种情况时停止转换:如果宽字符没有对应的有效多字节字符,或者(如果 dst 不是空指针)下一个多字节字超过了存储在 dst 指向的数组中的总字节数 len 的限制。每转换一次都相当于调用一次 wcrtomb()函数。如果 dst 不是空指针,就把空指针(如果因到达结尾的空字符而停止转换)或最后一个待转换多字节字符的地址赋给 src 指向的指针对象。如果由于到达结尾的空字符而停止转换,描述的结果状态就是初始转状态。如果执行成功,函数返回成功转换的多字节字符数(不包括空字符);否则函数返回-1
宽字符分类和映射工具
wctype.h类型/宏
类型/宏 描述 wint_t 整数类型,用于存储扩展字符集中的任意值,还可以存储至少一个不是扩展字符成员的值 wctrans_t 标量类型,可以表示本地化指定的字符映射 wctype_t 标量类型,可以表示本地化指定的字符分类 WEOF wint_t 类型的常量表达式,不对应扩展字符集中的任何成员,相当于宽字符中的 EOF,用于表示宽字符输入的文件结尾 函数
函数原型 描述 int iswalnum(wint_t wc); 如果 wc 表示一个字母数字字符(字母或数字),函数返回真 int iswalpha(wint_t wc); 如果 wc 表示一个字母字符,函数返回真 int iswblank(wint_t wc); 如果 wc 表示一个空格,函数返回真 int iswcntrl(wint_t wc); 如果 wc 表示一个控制字符,函数返回真 int iswdigit(wint_t wc); 如果 wc 表示一个数字,函数返回真 int iswgraph(wint_t wc); 如果 iswprint(wc)为真,且 iswspace(wc)为假,函数返回真 int iswlower(wint_t wc); 如果 wc 表示一个小写字符,函数返回真 int iswprint(wint_t wc); 如果 wc 表示一个可打印字符,函数返回真 int iswpunct(wint_t wc); 如果 wc 表示一个标点字符,函数返回真 int iswspace(wint_t wc); 如果 wc 表示一个制表符、空格或换行符,函数返回真 int iswupper(wint_t wc); 如果 wc 表示一个大写字符,函数返回真 int iswxdigit(wint_t wc); 如果 wc 表示一个十六进制数字,函数返回真 int iswctype(wint_t wc,wctype_t desc); 如果 wc 具有 desc 描述的属性,函数返回真 wctype_t wctype(const char *property); wctype()函数构建了一个 wctpe_t 类型的值,它描述了由字符串参数 property 指定的宽字符分类。如果根据当前本地化的 LC_CTYPE 类别,property 识别宽字符分类有效,wctype()函数则返回非零值(可作为 iswctype()函数的第 2 个参数);否则,函数返回 0 wint_t towlower(wint_t wc); 如果 wc 是大写字符,返回其小写形式;否则返回 wc wint_t towupper(wint_t wc); 如果 wc 是小写字符,返回其大写形式;否则返回 wc wint_t towctrans(wint_t wc,wctrans_t desc); 如果 desc 等于 wctrans(“lower”)的返回值,函数返回 wc 的小写形式(由 LC_CTYPE 设置确定);如果 dest 等于 wctrans(“upper”)的返回值,函数返回 wc 的大写形式(由 LC_CTYPE 设置确定) wctrans_t wctrans(const char *property); 如果参数是”lower”或”upper’”,函数返回一个 wctrans_t 类型的值,可用作 towctrans()的参数并反映 LC_CTYPE 设置,否则函数返回 0
拓展整数类型inttypes.h
精确宽度类型
类型名 printf()说明符 scanf()说明符 最小值 最大值 int8_t PRId8 SCNd8 INT8_MIN INT8_MAX int16_t PRId16 SCNd16 INT16_MIN INT16_MAX int32_t PRId32 SCNd32 INT32_MIN INT32_MAX int64_t PRId64 SCNd64 INT64_MIN INT64_MAX uint8_t PRIu8 SCNu8 0 UINT8_MAX uint16_t PRIu16 SCNu16 0 UINT16_MAX uint32_t PRIu32 SCNu32 0 UINT32_MAX uint64_t PRIu64 SCNu64 0 UINT64_MAX 最小宽度类型
类型名 printf()说明符 scanf()说明符 最小值 最大值 int_least8_t PRILEASTd8 SCNLEASTd8 INT_LEAST8_MIN INT_LEAST8_MAX int_least16_t PRILEASTd16 SCNLEASTd16 INT_LEAST16_MIN INT_LEAST16_MAX int_least32_t PRILEASTd32 SCNLEASTd32 INT_LEAST32_MIN INT_LEAST32_MAX int_least64_t PRILEASTd64 SCNLEASTd64 INT_LEAST64_MIN INT_LEAST64_MAX uint_least8_t PRILEASTu8 SCNLEASTu8 0 UINT_LEAST8_MAX uint_least16_t PRILEASTu16 SCNLEASTu16 0 UINT_LEAST16_MAX uint_least32_t PRILEASTu32 SCNLEASTu32 0 UINT_LEAST32_MAX uint_least64_t PRILEASTu64 SCNLEASTu64 0 UINT_LEAST64_MAX 最快最小宽度类型
类型名 printf()说明符 scanf()说明符 最小值 最大值 int_fast8_t PRIFASTd8 SCNFASTd8 INT_FAST8_MIN INT_FAST8_MAX int_fast16_t PRIFASTd16 SCNFASTd16 INT_FAST16_MIN INT_FAST16_MAX int_fast32_t PRIFASTd32 SCNFASTd32 INT_FAST32_MIN INT_FAST32_MAX int_fast64_t PRIFASTd64 SCNFASTd64 INT_FAST64_MIN INT_FAST64_MAX uint_fast8_t PRIFASTu8 SCNFASTu8 0 UINT_FAST8_MAX uint_fast16_t PRIFASTu16 SCNFASTu16 0 UINT_FAST16_MAX uint_fast32_t PRIFASTu32 SCNFASTu32 0 UINT_FAST32_MAX uint_fast64_t PRIFASTu64 SCNFASTu64 0 UINT_FAST64_MAX 最大宽度类型
类型名 printf()说明符 scanf()说明符 最小值 最大值 intmax_t PRIdMAX SCNdMAX INTMAX_MIN INTMAX_MAX uintmax_t PRIuMAX SCNuMAX 0 UINTMAX_MAX 可存储指针值的整型
类型名 printf()说明符 scanf()说明符 最小值 最大值 intptr_t PRIdPTR SCNdPTR INTPTR_MIN INTPTR_MAX uintptr_t PRIuPTR SCNuPTR 0 UINTPTR_MAX 拓展的整型常量
1、在整数后面加上
L后缀可表示 long 类型的常量,如445566L。如何表示 int32_t 类型的常量?
2、要使用inttypes.h头文件中定义的宏。例如,表达式INT32_C(445566)展开为一个 int32_t 类型的常量
3、从本质上看,这种宏相当于把当前类型强制转换成底层类型,即特殊实现中表示 int32_t 类型的基本类型
4、宏名把相应类型名中的_C用_t替换,再把名称中所有的字母大写。例如,要把 1000 设置为 unit_least64_t 类型的常量,可以使用表达式UNIT_LEAST_64C(1000)
拓展字符支持
三字符序列
三字符序列 符号 三字符序列 符号 三字符序列 符号 ??= # ??( [ ??) ] ??’ ^ ??< { ??> } ??- ~ ??/ \ ??! | 双字符(C99,但不会替换双引号中的双字符)
双字符序列 符号 双字符序列 符号 双字符序列 符号 <: [ :> ] <% { %> } %: # %:%: ## 可选拼写
iso646.h- 见前函数介绍



如果较为紧急,建议添加微信或QQ,并注明来意
评论系统可能加载较慢,请耐心等待或刷新重试